【学界】GAN跨界合成高保真音乐,Jeff Dean听了都陶醉
来源:新智元
【导读】谷歌大脑团队最新ICLR论文提出用GAN生成高保真音乐的新方法,速度比以前的标准WaveNet快5万倍,且音乐质量更好!
GAN 在生成高质量图像方面是当之无愧的最先进的方法。然而,将 GAN 扩展到如声音这类的序列数据任务,尽管有许多尝试,仍困难重重。
近日,谷歌大脑团队 Jesse Engel 等人用GAN生成音乐的新研究引起大量关注。Jesse Engel 在推特上兴奋地宣布:“用GAN生成音乐成功了!GANSynth是一种快速生成高保真音频的新方法。”
他们的论文 GANSynth: Adversarial Neural Audio Synthesis 已被 ICLR 2019接收。
谷歌 AI 总统帅 Jeff Dean 也被这个研究吸引,大加赞赏,并建议大家试听一下更多样本音乐。

GANSynth 生成音乐有多强呢?Jesse Engel 用一句话解释:“我们证明了,我们可以比标准的 WaveNet 快 5 万倍地生成乐器音频,并且具有更高的质量 (无论是定量测试还是听众测试),并且可以独立控制音高和音色,使得乐器之间的插入更加平滑。”
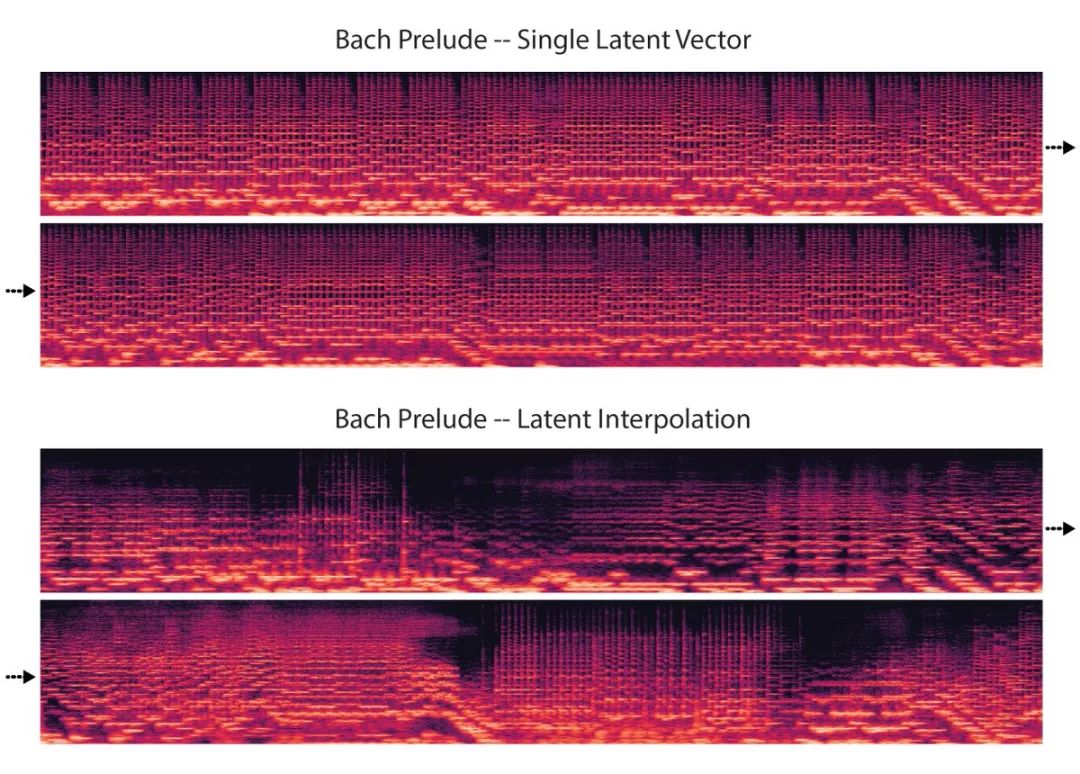
巴赫前奏曲的示例
他说:“与之前的音频模型 (如 WaveNet 自动编码器) 不同,我们学习整个音频剪辑的单个潜在向量,并添加音调调节向量。这可以产生更平滑的插值 (interpolations),让每个点听起来都像是一个有效的样本。”
他们发布了代码,享受用 colab notebook 制作自己的音乐的乐趣吧!
更多音乐样本:
https://storage.googleapis.com/magentadata/papers/gansynth/index.html
Colab:
https://colab.research.google.com/notebooks/magenta/gansynth/gansynth_demo.ipynb
论文: https://openreview.net/forum?id=H1xQVn09FX
Code:
https://github.com/tensorflow/magenta/tree/master/magenta/models/gansynth
Blog: http://magenta.tensorflow.org/gansynth
接下来,我们将详细介绍 GANSynth 生成音乐的运作原理.
GAN 是用于生成高质量图像的最先进的方法。然而,研究人员一直在努力将其应用到更加序列性的数据,如音频和音乐。
在序列数据中,自回归 (AR) 模型占主导地位,如 wavenet 和 Transformers,它们的运作方式是一次预测单个样本。虽然 AR 模型的这一特性有助于它们的成功,但这也意味着采样是连续的,而且非常缓慢,实时生成需要 distillation 或专用内核等技术。
GANynth 不是按序列生成音频,而是并行生成整个序列,在现代 GPU 上合成音频的速度比实时更快,比标准 WaveNet 快约 50000 倍。
与原始论文中使用时间分布潜码的 WaveNet 自动编码器不同,GANynth 从单个潜在向量生成整个音频片段,从而更轻松地分开音高和音色等全局特征。利用乐器音符的 NSynth 数据集,我们可以独立控制音高和音色。
请听听下面的示例音乐,我们首先保持音色是常数,然后在整首曲子中插入音色:
保持音色常数的示例
在整首曲子中插入音色
GANynth 使用一个 Progressive GAN 架构,通过卷积将样本从单个向量逐步上采用到完整的声音。与之前的工作类似,我们发现直接生成相干波形 (coherent waveforms) 很困难,因为上采样卷积与高周期信号的相位对齐相悖。如下图所示:

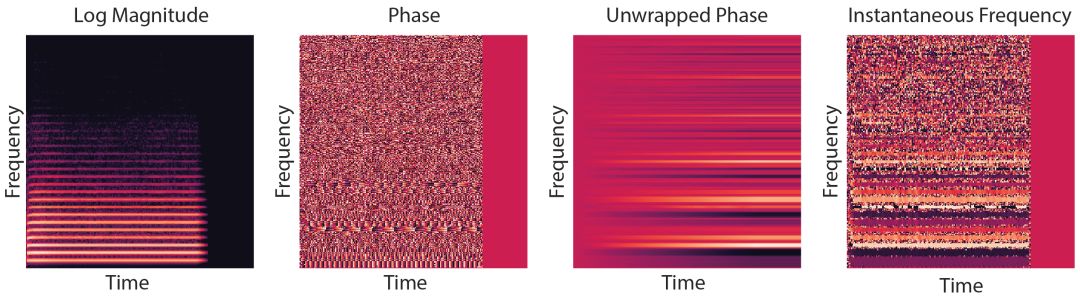
上图中,红黄相间的曲线是一个周期信号,每个周期波形的开始处都有一个黑点。如果我们尝试通过将其切割成周期性的帧 (黑色虚线) 来对信号进行建模,就像对 GAN 中的上采样卷积和短时距傅里叶变换 (STFT) 所做的那样,帧的开始 (虚线) 和波形的开始 (点) 之间的距离随时间变化而改变 (黑色实线)。
对于跨步卷积,这意味着卷积需要学习给定滤波器的所有相位排列,这是非常低效的。这种差异 (黑线) 被称为相位 (phase),它随着时间的推移而进行,因为波和帧有不同的周期。

正如上面的示例所展示的,相位是一个环形量 (黄色条,mod 2π),但是如果我们展开它 (橙色条), 它每帧减少一个恒定量 (红色条)。我们称之为瞬时频率 (IF),因为频率的定义是相位随时间的变化。STFT 将一帧信号与许多不同频率进行比较,得到如下图所示的斑点相位模式。相比之下,当我们提取瞬时频率时,我们看到的是一致的粗体线条,反映了潜在声音的相干周期。
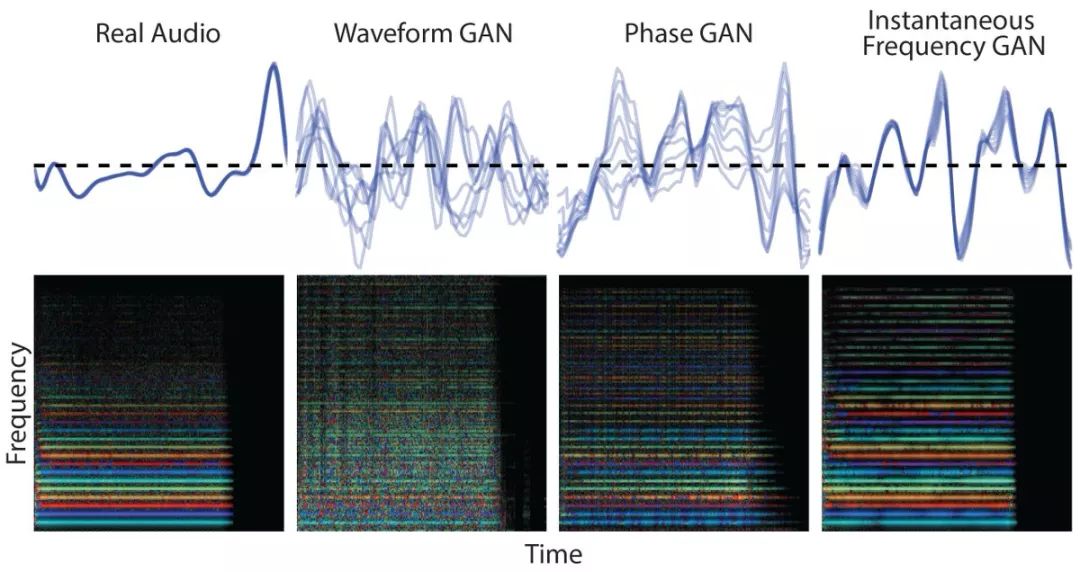
在 GANynth ICLR 的论文中,我们用一系列频谱表示来训练 GAN,发现对于像音乐这样的高周期性声音,为相位分量生成瞬时频率 (IF) 的 GAN 优于其他表示和其他强大基线,包括生成波形的 GAN 和无条件 WaveNets。
我们还发现,progressive training (P) 和提高 STFT (H) 的频率分辨率有助于分离紧密间隔的谐波,从而提高性能。下面的图表显示了用户听力测试的结果,测试中用户需要收听来自两种不同方法的音频示例,并被提问他们更喜欢哪一种:
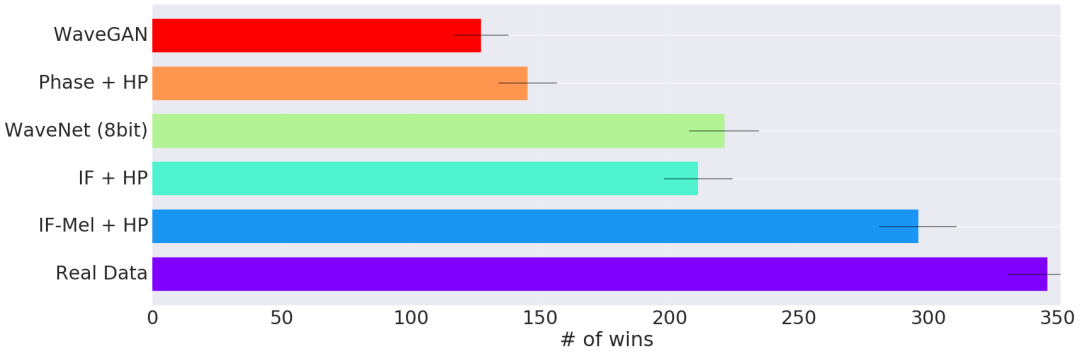
除了本文中提到的多种定量测量方法外,我们还可以定性地看到产生瞬时频率 (IF-GAN) 的 GAN 也会产生更多的相干波形。
下图的第一行显示了所生成的波形,对音符的基本周期取模。需要注意的是,真实数据完全与它自身重叠,因为波形是非常周期性的。然而, WaveGAN 和 PhaseGAN 有许多相位不规则性,形成了模糊的线条网。IF-GAN 更为连贯,在周期和周期之间只有很小的变化。
在下面的彩虹图 (CQT,颜色代表瞬时频率) 中,真实数据和 IF 模型具有相干波形,使得每个谐波的颜色具有很强的一致性,而 PhaseGAN 由于相位不连续有许多斑点, WaveGAN 则非常不规则。
这项工作是使用 GAN 生成高保真音频的初步尝试,但仍存在许多有趣的问题。虽然上述方法在处理音乐信号方面效果不错,但在语音合成方面仍产生了一些明显的缺陷。
最近的一些相关工作就是在此基础上,探索从生成的频谱图中恢复相位的方法,同时减少伪影。其他有前途的方向包括使用 multi-scale GAN、处理可变长度输出,以及用灵活的可微分合成器替换上采样卷积生成器。
更多音乐样本:
https://storage.googleapis.com/magentadata/papers/gansynth/index.html
Colab:
https://colab.research.google.com/notebooks/magenta/gansynth/gansynth_demo.ipynb
论文: https://openreview.net/forum?id=H1xQVn09FX
Code:
https://github.com/tensorflow/magenta/tree/master/magenta/models/gansynth
Blog: http://magenta.tensorflow.org/gansynth
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得





