

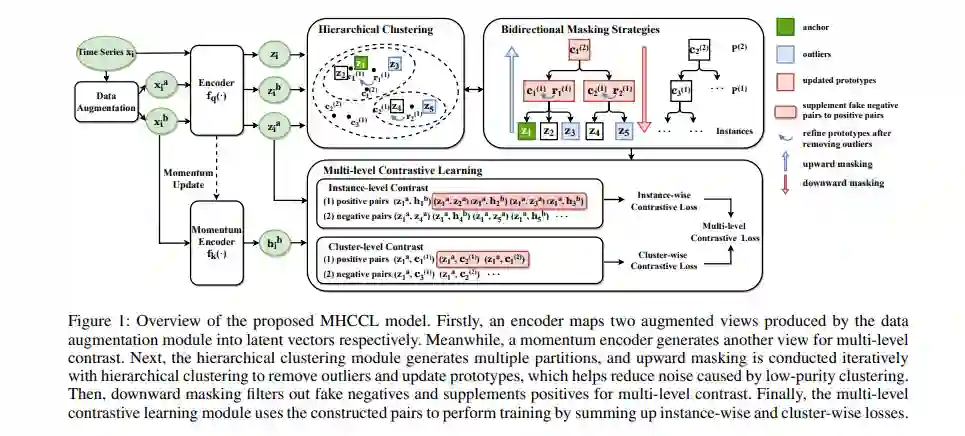
从原始无标签时间序列数据中学习语义丰富的表示,对于分类和预测等下游任务至关重要。最近,对比学习在没有专家注释的情况下显示出了很好的表示学习能力。然而,现有的对比方法通常独立地对待每个实例,从而导致具有相同语义的假负样本对。为了解决这一问题,本文提出了一种掩码层次聚类对比学习模型MHCCL,利用多元时间序列的多个潜在分区组成的层次结构所获得的语义信息。细粒度聚类保持了较高的纯度,而粗粒度聚类反映了更高层次的语义,受此启发,本文提出了一种新的向下屏蔽策略,通过融合来自聚类层次的多粒度信息来过滤假负样本并补充正样本。此外,MHCCL设计了一种向上掩蔽策略,在每个划分处去除聚类的离群点,以完善原型,有助于加快层次聚类过程,提高聚类质量。在7个广泛使用的多元时间序列数据集上进行了实验评估。实验结果表明,MHCCL比目前最先进的无监督时间序列表示学习方法具有优越性。
https://www.zhuanzhi.ai/paper/e0c875b4a35564ddf37b97d9d3fab9f7
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 2023年2月9日
Arxiv
0+阅读 · 2023年2月7日


相关VIP内容
相关资讯