当SVM碰上对比学习?霍普金斯/MIT学者在AAAI2022提出《最大化间隔对比学习》选择更好的负样例提升对比性能
对比学习是现在机器学习热点研究方法之一。来自霍普金斯、MIT等学者受支持向量机启发,提出最大化间隔对比学习,能够选择更好负样例,提供更好的对比学习性能。

标准的对比学习方法通常需要大量的负样例来实现有效的无监督学习,并且通常表现出缓慢的收敛。我们怀疑这种行为是由于负样本的次优选择,以提供对积极样例的对比。为了克服这个困难,我们从支持向量机(SVM)中汲取灵感,提出了最大间隔对比学习(MMCL)。我们的方法选择负样例作为通过二次优化问题获得的稀疏支持向量,并通过最大化决策裕度来增强对比度。由于支持向量机优化可能需要大量的计算,特别是在端到端环境中,我们提出了简化方法来减轻计算负担。我们在标准视觉基准数据集上验证了我们的方法,证明了在无监督表示学习中比最先进的技术有更好的性能,同时具有更好的收敛特性。
https://www.zhuanzhi.ai/paper/f7a25615105237c8c9a7750213072bf2
学习有效的数据表示是任何机器学习模型成功的关键。近年来,利用大量未标记数据的无监督表示学习算法出现了激增(Chen et al. 2020a; Gidaris, Singh, and Komodakis 2018; Lee et al. 2017; Zhang et al. 2019; Zhan et al. 2020)。在这种算法中,辅助学习目标通常被设计成生成可泛化表示,以捕获数据的一些高阶属性。假设这些属性可能在(有监督的)下游任务中有用,因为下游任务可能有更少的带注释的训练样本。例如,在(Noroozi和Favaro 2016; Santa Cruz et al. 2018), pre-text任务是解决patch jigsaw 难题,以便所学习的表示能够潜在地捕获图像的自然语义结构。其他流行的辅助目标包括视频帧预测(Oord, Li,和Vinyals 2018)、图像着色(Zhang, Isola,和Efros 2016)和深度聚类(Caron等人2018)等。
在典型的表征学习的辅助目标中,最近获得显著进展的一个是对比学习,这是标准噪声对比估计(NCE)的一个变体(Gutmann和Hyvarinen 2010)。在NCE中,目标是通过将未标记数据与随机噪声进行分类来学习数据分布。然而,最近发展起来的对比学习方法通过设计目标来捕获数据不变性来学习表示。具体来说,这些方法不像NCE那样使用随机噪声,而是将数据样本转换为样本集,每个样本集由一个样本的转换变体组成,辅助任务是将一个样本集(阳性)与其他样本集(阴性)进行分类。令人惊讶的是,即使使用简单的数据转换,如颜色抖动、图像裁剪或旋转,这些方法也能够学习优越的和可泛化的表示,有时甚至在下游任务中优于监督学习算法(例如,CMC (Tian, Krishnan, and Isola 2020), MoCo (Chen et al. 2020c; He et al. 2020)、SimCLR (Chen et al. 2020a)和BYOL (Grill et al. 2020))。
通常,对比学习方法使用NCE-loss作为学习目标,这通常是一个将正样例和负样例分开的逻辑分类器。然而,正如在NCE算法中经常发现的那样,负样例的分布应该接近于正样例,这样学习的表示才会有用——在实践中,这个标准通常需要大量的负数(例如,SimCLR中的16K (Chen et al. 2020a))。此外,标准对比学习方法做出了隐含的假设,即在下游任务中积极和消极属于不同的类别(Arora等人,2019)。这一要求很难在无监督的训练机制中执行,违背这一假设可能会损害下游的表现,因为有益的判别性线索被忽视。
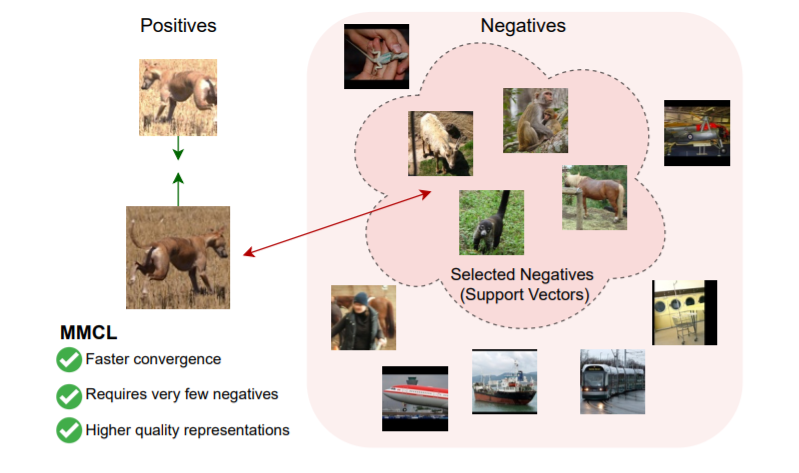
我们的Max-Margin对比学习框架的图解。对于每一个正的例子,我们通过求解SVM目标来计算一个判别超平面来计算(硬)负的加权子集。然后,这个超平面被用于学习以最大化正数表示之间的相似性,最小化正数表示与负数表示之间的相似性。图中的负数是由我们的方案为各自的正数选择的实际数字。
在本文中,我们探索了标准逻辑分类器之外的对比学习。我们的关键是设计一个目标函数: (i) 选择一个合适的对比样例子集, 和 (2)提供了一个放松假负样例在学习表示上的影响。图1给出了这个想法的概述。在这方面,一个自然的目标是经典的支持向量机(SVM),它产生一个区分超平面,最大限度地将正与负样例分离。受支持向量机的启发,我们提出了一种新的目标,最大间隔对比学习(MMCL),以学习数据表示,使支持向量机的决策边际最大化。MMCL为表示学习带来了几个好处。例如,内核技巧允许使用丰富的非线性嵌入来捕获所需的数据相似性。此外,决策裕度与支持向量直接相关,支持向量构成加权数据子集。在支持向量机公式中使用松弛变量的能力允许对假负样例对表示学习设置的影响进行自然控制。
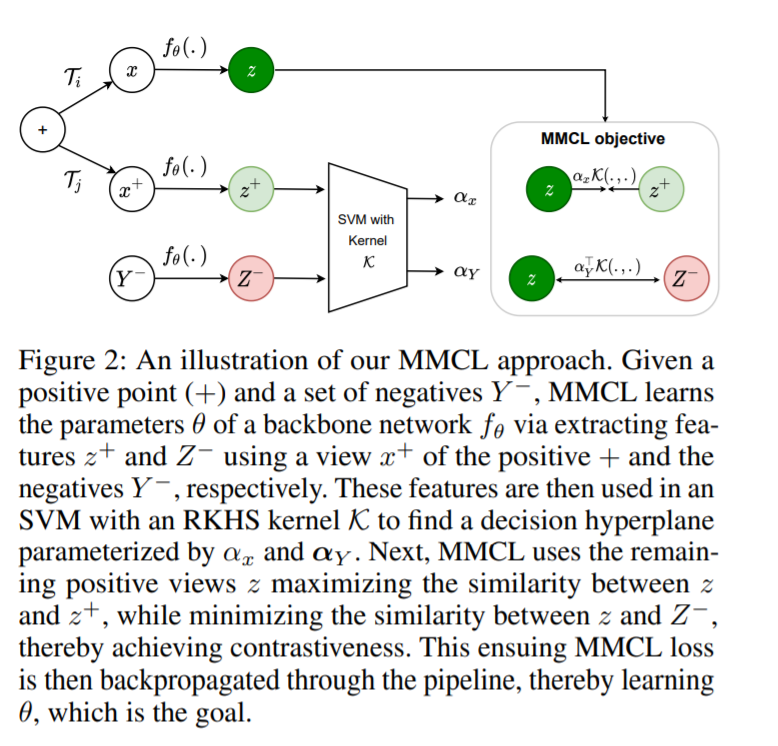
直接使用MMCL目标可能具有实际挑战性。这是因为支持向量机涉及到求解一个有约束的二次优化问题,当在标准的深度学习模型中使用时,求解这个问题可以极大地增加训练时间。为此,受坐标下降算法的启发,我们提出了一种新的支持向量机目标的重新表述,使用的假设通常用于对比学习设置。具体地说,我们提出使用一个单一的正数据样本来训练支持向量机对抗负样例数据-在这种情况下,可以获得判别超平面的有效近似解。一旦获得超平面,我们提出使用它来进行表示学习。因此,我们制定了一个目标,使用这个学习过的超平面来最大限度地提高剩余的正与负之间的分类裕度。为了证明我们的方法在无监督学习方面的经验优势,我们用提出的MMCL目标代替了先前的对比学习算法中的逻辑分类器。我们在标准基准数据集上进行了实验; 我们的结果表明,使用我们的最大边际目标可以更快地收敛,需要的负样例比以前的方法少得多,并且产生的表示可以更好地泛化到几个下游任务,包括多样本识别的迁移学习、少样本识别和表面正态估计。
我们利用支持向量机提出了一种新的对比学习公式,称为max-margin对比学习;
我们提出了一种使用对比学习中常用的问题设置来简化支持向量机目标的新方法——这种简化允许为决策超平面推导出有效的近似。
我们探索了支持向量机超平面的两个近似求解器:(i)使用投影梯度下降和(ii)使用截断最小二乘的封闭形式。
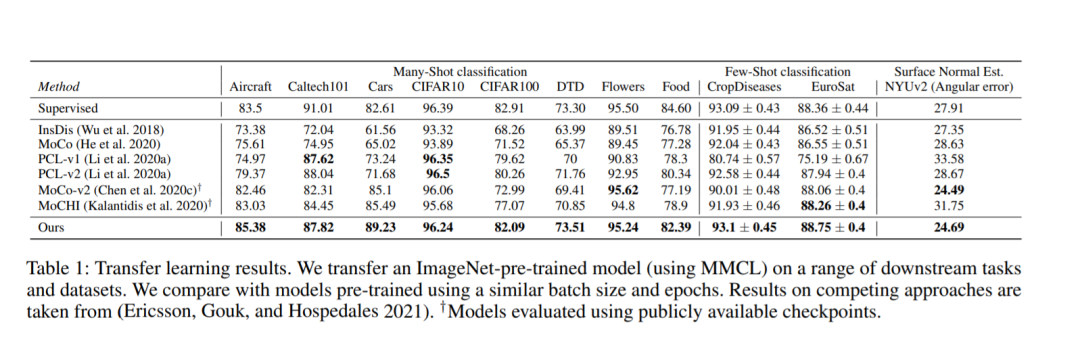
我们展示了在标准计算机视觉数据集上的实验,如ImageNet-1k, ImageNet-100, STL-10, cifar100,和UCF101,展示了与先进技术相比的优越性能,同时只需要较小的负批次。此外,在广泛的迁移学习任务中,我们的预训练模型比竞争方法显示出更好的泛化性。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MMCL” 就可以获取《AAAI2022提出《最大化间隔对比学习》选择更好的负样例提升对比性能》专知下载链接





