
https://www.zhuanzhi.ai/paper/5d9a7923aecd639fe8d54d090cca1513
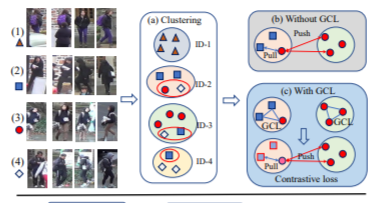
无监督人再识别(Re-ID)因其解决有监督Re-ID模型可扩展性问题的潜力而受到越来越多的关注。现有的无监督聚类方法大多采用迭代聚类机制,基于无监督聚类生成的伪标签训练网络。然而,聚类错误是不可避免的。为了生成高质量的伪标签并减少聚类错误的影响,我们提出了一种新的无监督人Re-ID聚类关系建模框架。具体来说,在聚类之前,利用图关联学习(GCL)模块探索未标记图像之间的关系,然后利用细化的特征进行聚类,生成高质量的伪标签。因此,协方差分析自适应地在一个小批量中挖掘样本之间的关系,以减少训练时异常聚类的影响。为了更有效地训练网络,我们进一步提出了一种带有选择性记忆库更新策略的选择性对比学习(SCL)方法。大量的实验表明,我们的方法比市场1501、DukeMTMC-reID和MSMT17数据集上大多数最先进的无监督方法的结果要好得多。我们将发布模型复制的代码。
成为VIP会员查看完整内容
相关内容
Arxiv
4+阅读 · 2021年6月21日

相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2021年6月21日