【AAAI2023】对比掩码自动编码器的自监督视频哈希

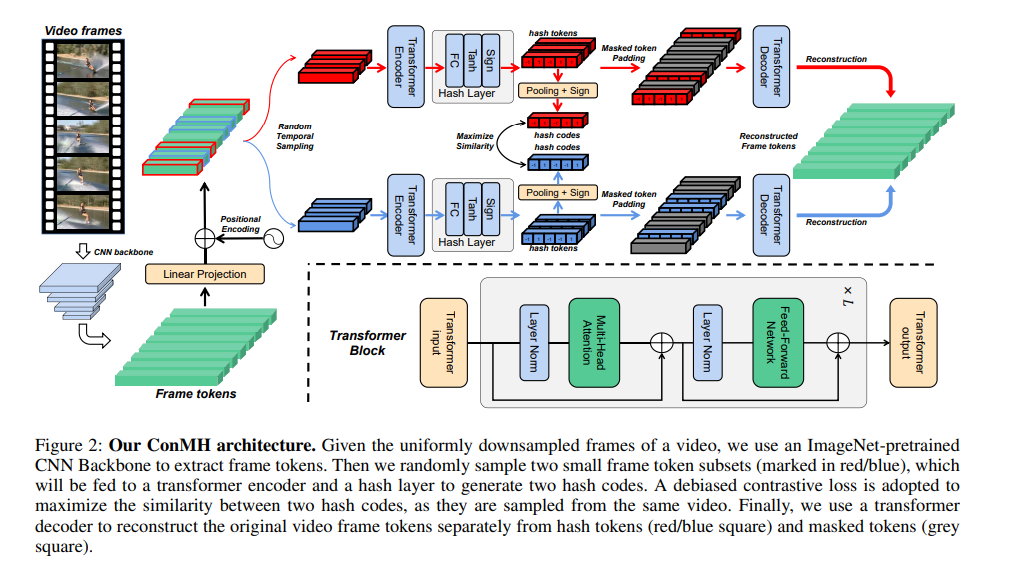
自监督视频哈希(SSVH)模型学习为视频生成短二进制表示,无需地真监督,提高了大规模视频检索的效率,引起了越来越多的研究关注。SSVH的成功之处在于对视频内容的理解以及捕获未标记视频之间语义关系的能力。通常,最先进的SSVH方法在两阶段训练管道中考虑这两点,首先通过实例掩码训练辅助网络并预测任务,其次训练哈希模型以保留从辅助网络转移的伪邻域结构。这种连续的训练策略是不灵活的,也是不必要的。本文提出了一种简单有效的单阶段SSVH方法——ConMH,该方法将视频语义信息和视频相似关系的理解融合在一个单阶段中。为了获取视频语义信息,我们采用编码器-解码器结构从时间掩码帧重构视频。特别是,我们发现较高的掩蔽比有助于视频理解。此外,我们充分利用了视频之间的相似关系,最大化了视频的两个增强视图之间的一致性,从而获得了更具鉴别性和鲁棒性的哈希码。在三个大型视频数据集(FCVID, ActivityNet和YFCC)上的大量实验表明,ConMH达到了最先进的结果。网址:https://github.com/ huangmozhi9527/ConMH。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CMAH” 就可以获取《【AAAI2023】对比掩码自动编码器的自监督视频哈希》专知下载链接



登录查看更多
相关内容
Arxiv
11+阅读 · 2021年12月16日



相关VIP内容
相关资讯
相关论文
Arxiv
11+阅读 · 2021年12月16日