商品检索是在线电商系统的基础,需要快速准确地找到用户所需的产品。其中,相关性是检索过程的一个重要考量因素,其作用是避免展现与用户搜索意图不匹配的产品,从而优化用户体验。在相关性任务场景中,用户的搜索词条是最能够清晰反映其意图的信息;同时,商品的标题文本作为展现的主要信息,也能够体现商品的本质内容。因此,通过比较两者间的语义匹配程度能够很好的评估和约束展现商品的相关性,即语义相关性学习。当前,该任务上仍存在着一些亟待解决的问题,包括电商领域严重的长尾数据分布、高质量语义监督信息的匮乏等。近期的相关研究试图通过引入场景中丰富的
用户行为
进行相关性学习。然而,用户行为中大量的噪声很容易导致语义建模不足。为了解决以上问题,本文首先提出了一个弱监督的对比学习框架,该框架能够提供有效的语义监督进行更好的数据表征学习。具体的,我们利用用户行为异构图中包含的拓扑结构信息来设计语义感知的数据构建策略,并设计了针对电商场景特征的数据增强方法与训练目标。此外,在后交叉计算阶段,我们提出了一种新的混合式方法,通过结合微调与迁移学习缓解了数据分布偏差造成的负面影响。大量的实验与分析表明,本文所提出的方法在语义相关性学习中具有显著的性能。基于该项工作整理的内容已发表在 CIKM 2022,欢迎阅读交流。
论 文 :Graph-based Weakly Supervised Framework for Semantic Relevance Learning in E-commerce
下 载 (点击↓阅读原文) https://dl.acm.org/doi/10.1145/3511808.3557143
2. 背景
文本表示学习是自然语言处理的一项基本任务,良好的语义表示能力对许多下游任务有益,如语义相似性匹配和信息检索。电商检索是该技术的主要应用场景之一,它旨在根据用户的搜索词条提取候选商品。语义相关性匹配通过计算用户搜索词条与商品文本信息之间的关联程度为候选商品检索提供了基础,能够有效减少不愉快的用户体验并保障用户对电商平台长期的满意度。
与传统的文本匹配任务不同,语义相关性学习需要建模不同数据分布间的联系。举例来说,用户的检索词条往往比较简短,并具有清晰的语义,如“
黑色连衣裙 ”。而商品标题通常很长、语义成分复杂、并且包含一些噪声,如“
2022年新款法式别致赫本风小众黑色西装长袖连衣裙子女秋冬季 ”。直接建模两者之间的匹配关系可能会使模型无法完全理解语义,而只能通过简单的文字重叠率进行判断。并且,用户检索词条与商品标题的人工标注数据成本高昂,无法大规模使用。近期的工作试图利用用户行为(点击、购买等)作为弱监督信息来解决标注匮乏的问题。然而,根据分析,我们发现用户行为是多种复杂因素的综合表现,其中包含了大量语义噪声。综上,为了优化语义相关性,我们提出了一种训练框架。首先基于用户行为图上拓扑结构挖掘语义信息,并设计适用于电商领域的对比学习框架建模语义感知的数据表示,再通过微调与迁移学习对检索词条和商品标题间的相关性进行建模。
本文的主要研究成果和创新点为:
设计了一种基于图的数据采样策略,从原始用户行为图中提炼出语义信息,为语义相关性学习提供了大量弱监督数据,缓解了训练数据匮乏的现象。
基于对比学习,在模型结构、数据增强、训练目标上围绕电商场景的特征进行针对性设计,提出适用于电商领域的对比学习训练框架。
在交互计算阶段提出一种混合式方法,结合微调与迁移学习,缓解数据分布偏差对相关性学习的负面影响。
3. 方法 3.1 基于图的数据构建
图1 用户行为图示例
为了提高方法的泛化性,本文仅关注简单的电商场景二部图。如图1所示,用户行为图中包含用户检索词条(query)以及商品(item)两种节点,并通过点击、购买等交互行为构建其连边。在图中,不同query可能同时与某个item产生交互行为,这在不同query之间提供了语义关联,这种关联可用异质图中的元路径(meta-path)表示。为了衡量语义关联的程度,我们使用了query之间的点对互信息(PMI)作为连边的权重:
进一步地,我们设计了一种类似node2vec[1]的方法,利用图中的高阶拓扑信息挖掘更细粒度的语义关联。具体地,从图中某个query节点为起点进行深度优先检索(DFS),我们能够通过设置游走步数等经验参数,控制终点query节点的语义偏移程度,从而采集到不同难度的相关性学习样本。相较于传统的数据构建方式,本文提出的方法能够拟合真实的应用场景,并且能通过简单的参数设置对正负样本的难度和比例做出调整,为下游任务提供置信度更高的监督信息。
3.2 对比学习框架
图2 对比学习框架
我们以MoCo对比学习结构[2]为基础训练query的建模,并在此基础上结合电商场景的特征,在数据增强方法与训练目标上进行了针对性的设计。具体来说,为了提升数据的多样性与连续性,同时提高模型对于噪声的鲁棒性,我们采用了Mix-up[3]和对抗攻击[4]进行数据增强。同时,为将用户行为图中的拓扑信息建模到数据表示中,我们设计了簇级别的对比学习训练目标。
Mix-up :以一定比例混合正样本与负样本,产生更具难度的负样本,有助于模型更好的建模正负样本的区分边界。
对抗攻击 :通过添加基于梯度的对抗扰动,同样能够提高负样本的难度,并且该方法对于数据中的噪声具有更强的鲁棒性。
簇级别对比学习 :若多个query节点可以构成一个完全子图,则将它们视为一个语义单元并进行联合的对比学习优化。
3.3 交叉计算方法
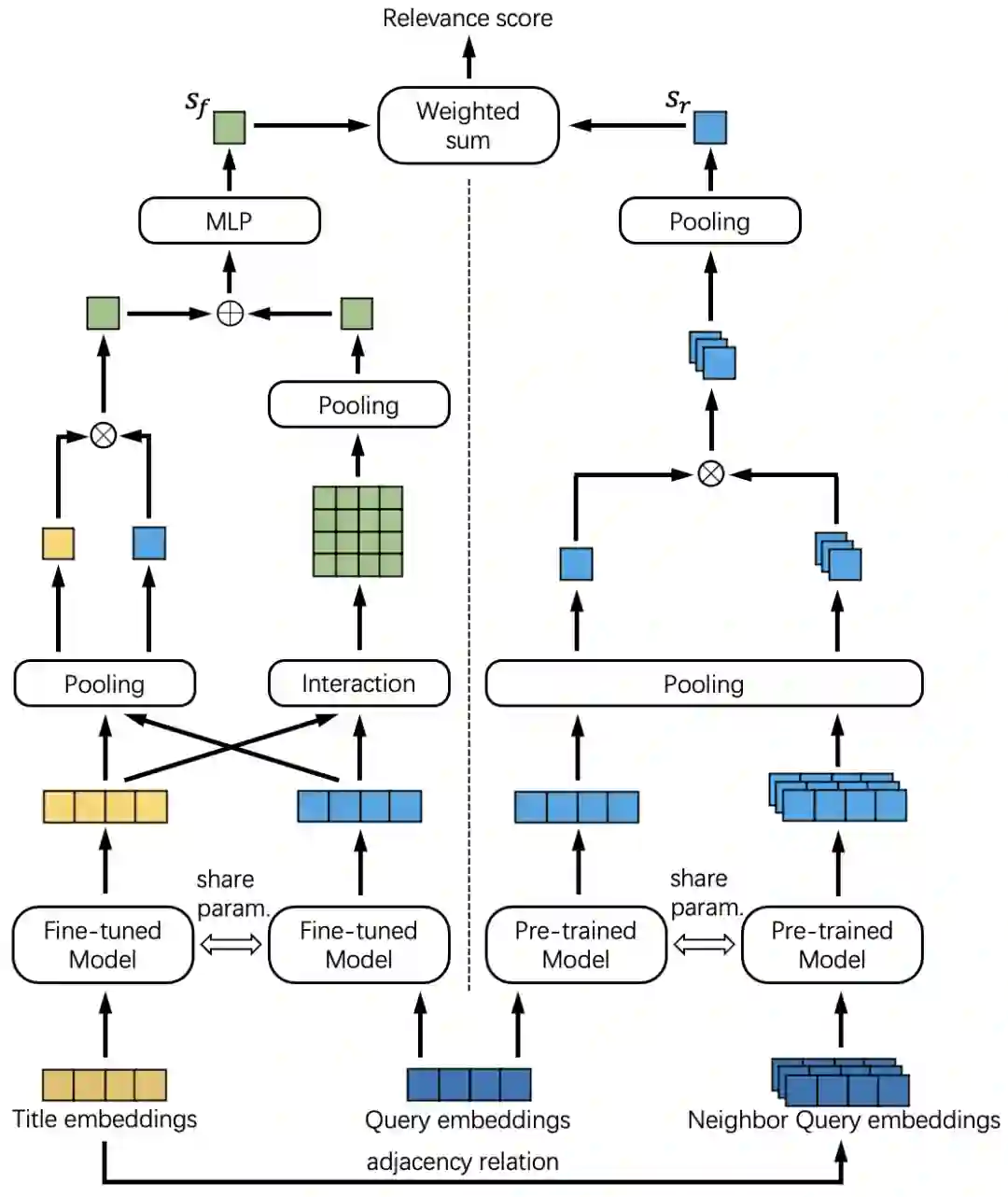
图3 交叉计算方法
图3展示了我们提出的相关性交叉计算方法。该方法通过结合多粒度微调(左侧)与基于关系的迁移学习(右侧),能够将基于query的预训练模型泛化到query与item的相关性计算任务上,在充分保留模型语义表示能力的前提下,缓解query与item标题之间的数据分布偏差带来的负面影响。
多粒度微调 :利用少量的人工标注样本与用户行为图中的高置信度交互关系样本(如点击率高于阈值),能够获取到query-item标题的正负样本。我们从句子粒度和分词粒度进行数据对的表示交叉,并通过一个分类任务完成预训练模型的微调。
基于关系的迁移学习 :我们发现,在用户行为图上,以某个item为中心,其相邻的query可以表示相似的语义。因此,我们将query和item标题之间的语义匹配转换为query和item的相邻query集合之间的匹配。该方法的优点是计算query同质信息间的语义相关性,能够避免受到数据分布偏差的影响。
4. 实验分析
本节中我们选择了部分实验结论进行展示,更多实验细节与结论请参考原论文。
https://dl.acm.org/doi/10.1145/3511808.3557143
4.1 对比与消融实验
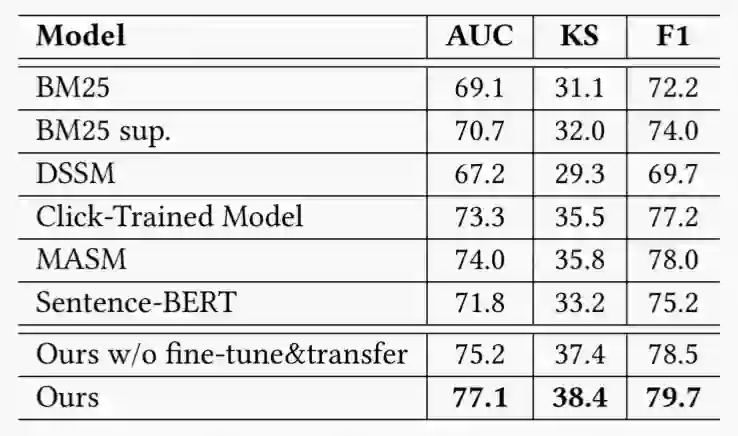
结合淘宝在线电商平台的用户交互信息构建大规模异质图进行弱监督数据采样,少量人工标注的相关性数据进行微调和测试。表1所示为本文提出的模型框架与基线模型在AUC、F1-score和KS指标上的对比。我们从两个方面给出了模型的实验结果。首先,对本文提出的总体模型框架进行了测试,以验证其最优表现。同时,我们也给出了没有微调和迁移学习的结果,这种设置方式避免了query和item之间进行有参数的信息交叉,以便与基线模型进行更公平的比较。结果表明,本文提出的模型在各项指标上获得了一致的提升。与Sentence-BERT相比,基于用户行为的对比预训练可以有效地缓解数据表示的各向异性,从而提升语义表示能力;与Click-Trained Model和MASM相比,我们的数据构建策略和训练目标设计更适宜语义相关性学习,是性能提升的主要来源。
表1:与基线模型的对比实验结果
表2中,详细的消融实验结果表明,所提出的方法都对相关性学习有积极影响。传统自监督对比学习由于难以适应电商场景的复杂数据分布,因而表现不佳。在添加了从用户行为中挖掘的弱监督语义信息后,模型性能得到了显著改善,这表明我们的数据构建策略契合任务的特点。除此之外,困难负样本的增强与簇级别对比学习对于语义建模也十分重要,可以更好地建模表示空间中不同语义单元的区分性。
表2:消融实验结果
4.3 样例分析
如表3所示,我们通过实际样例的分析体现电商场景中语义匹配任务的难点,并展示本文提出的改进方法的优化效果。我们筛选了部分需要充分语义理解才能做出准确相关性判断的典型样例,以DSSM作为基线模型,可以发现其给出的相关性分数严重依赖于简单的词汇匹配率。在添加弱监督对比预训练之后,相关性分数被显著纠偏,这体现出了语义预训练的效果。尽管如此,模型给出的预测结果仍然是错误的,我们认为这是由于同质语义建模与异质语义匹配之间的矛盾。因此,我们提出了基于关系的迁移学习,通过用户行为图中的拓扑信息实现数据迁移,将问题转化为同质语义匹配,该方法在所展示的样例中表现出了亮眼的性能,证明基于关系的迁移学习能够在语义匹配中发挥重要的作用。
表3:样例分析
5. 结论
语义相关性学习在电商场景中十分重要,而数据分布偏差、长尾数据分布以及高质量标注数据的匮乏等问题限制了其发展。本文中,我们提出了一种用于电商场景的弱监督预训练框架,挖掘用户行为数据中的拓扑信息,并通过改进的对比学习进行语义感知的表示学习,充分建模了电商场景中的文本特征。此外,我们提出了一种混合式的相关性交叉计算方法。通过结合微调和迁移学习,有效缓解了用户检索文本和商品标题文本之间的语义分布差异对模型建模带来的负面影响,进一步优化了模型的语义匹配能力。在人工标注数据集上,我们通过大量实验和分析证明了所提出方法的优势。在离线阶段取得效果验证后,我们在线上应用了所提出的方法,验证了其可以在引入可忽略时延的前提下显著提升相关性指标,减少不愉快的用户体验。
参考文献 [1] Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable Feature Learning for Networks. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2016).
[2] Kaiming He,Haoqi Fan,Yuxin Wu,Saining Xie,and Ross Girshick.2020. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9729–9738.
[3] Hongyi Zhang, Moustapha Cissé, Yann Dauphin, and David Lopez-Paz. 2018. mixup: Beyond Empirical Risk Minimization. ArXiv abs/1710.09412 (2018).
[4] Huangzhao Zhang, Hao Zhou, Ning Miao, and Lei Li. 2019. Generating Fluent Adversarial Examples for Natural Languages. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 5564–5569.
[5] Yuanmeng Yan, Rumei Li, Sirui Wang, Fuzheng Zhang, Wei Wu, and Weiran Xu. 2021. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer. arXiv preprint arXiv:2105.11741 (2021).
[6] Sen Li, Fuyu Lv, Taiwei Jin, Guli Lin, Keping Yang, Xiaoyi Zeng, Xiaoming Wu, and Qianli Ma. 2021. Embedding-based Product Retrieval in Taobao Search. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (2021).