
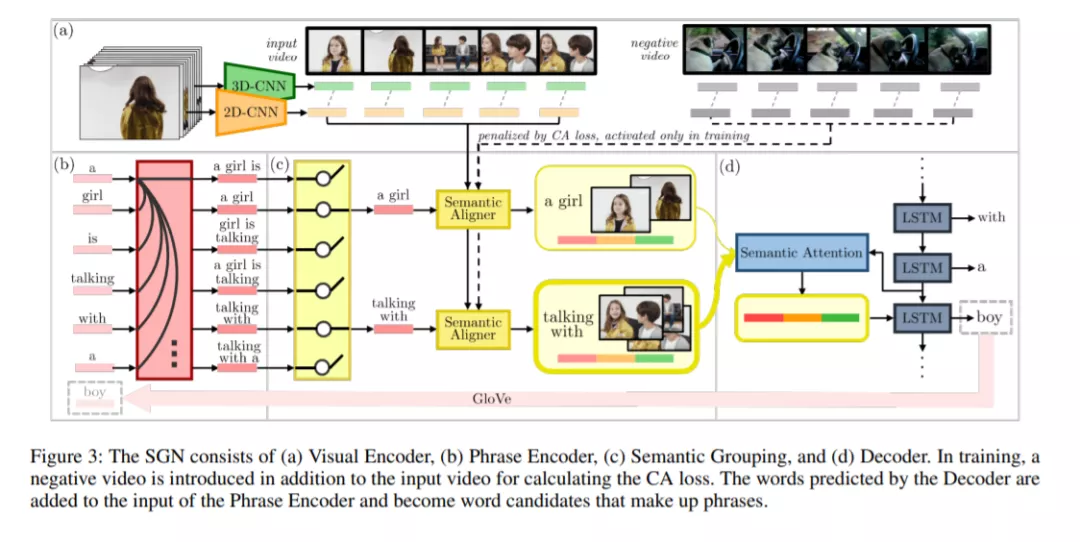
本文提出一种语义分组网络通过建立词组与相关语义视频帧的映射来减少信息冗余。 本文提出了一个语义分组网络(SGN)的视频描述生成网络,该网络尝试(1)使用具有部分已解码描述的可区分词组对视频帧进行分组,然后(2)在预测下一个单词时使用这些语义对齐的视频帧组进行解码。 本文发现连续的帧可能提供了相同的信息,然而现有方法集中于仅基于输入视频来丢弃或合并重复信息。语义分组网络学习了一种算法来捕获部分已解码描述中最具区分性的词组以及将每个词组与相关视频帧的映射,通过建立此映射可以将语义上相关的帧聚类,从而减少冗余。与现有方法相反,来自已解码描述词的连续反馈使语义分组网络能够动态更新适应部分解码描述的视频表示。此外,本文提出了一种对比注意损失,以促进单词短语和视频帧之间的准确对齐而无需人工注释。
https://www.zhuanzhi.ai/paper/ca2f9fa733ff339f5ca3e10526823d47
成为VIP会员查看完整内容
相关内容
Arxiv
3+阅读 · 2020年3月17日
Arxiv
3+阅读 · 2019年7月11日
Arxiv
8+阅读 · 2018年5月2日
Arxiv
5+阅读 · 2018年4月3日
相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2020年3月17日
Arxiv
3+阅读 · 2019年7月11日
Arxiv
8+阅读 · 2018年5月2日
Arxiv
5+阅读 · 2018年4月3日