AI大语言模型的原理、演进及算力测算
机器学习中模型及数据规模增加有利于提高深度神经网络性能。
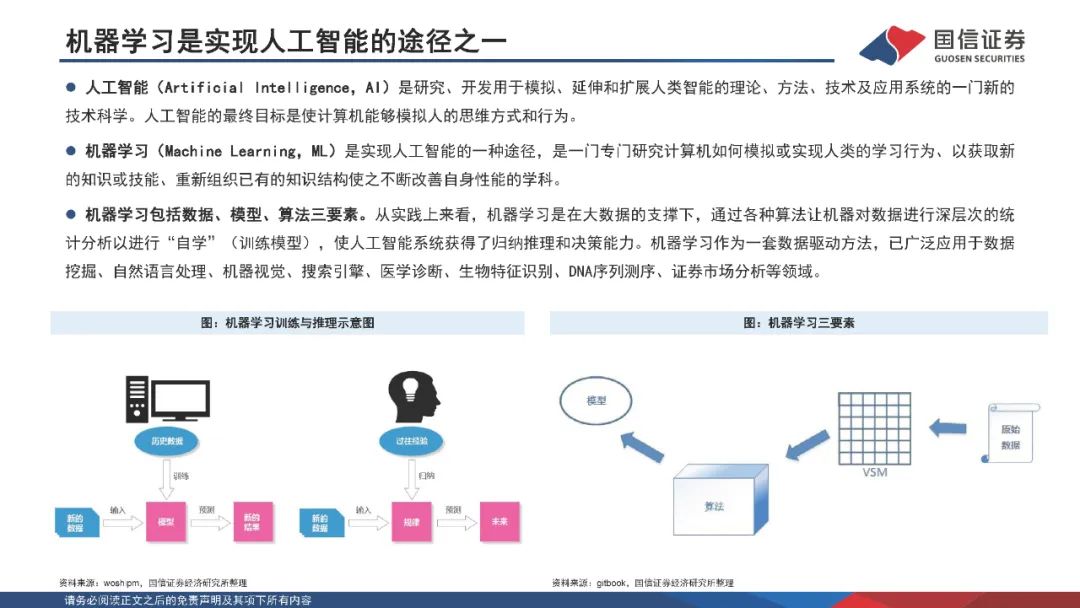
人工智能致力于研究能够模拟、延伸和扩展人类智能的理论方法及技术,并开发相关应用系统;其最终目标是使计算机能够模拟人的思维方式和行为。机器学习是一门专门研究计算机如何模拟或实现人类的学习行为、以获取新的知识或技能、重新组织已有的知识结构使之不断改善自身性能的学科,广泛应用于数据挖掘、计算机视觉、自然语言处理等领域。深度学习是机器学习的子集,主要由人工神经网络组成。与传统算法及中小型神经网络相比,大规模的神经网络及海量的数据支撑将有效提高深度神经网络的表现性能。 Transformer模型架构是现代大语言模型所采用的基础架构。
Transformer模型是一种非串行的神经网络架构,最初被用于执行基于上下文的机器翻译任务。Transformer模型以Encoder-Decoder架构为基础,能够并行处理整个文本序列,同时引入“注意机制”(Attention),使其能够在文本序列中正向和反向地跟踪单词之间的关系,适合在大规模分布式集群中进行训练,因此具有能够并行运算、关注上下文信息、表达能力强等优势。Transformer模型以词嵌入向量叠加位置编码作为输入,使得输入序列具有位置上的关联信息。编码器(Encoder)由Self-Attention(自注意力层)和FeedForwardNetwork(前馈网络)两个子层组成,Attention使得模型不仅关注当前位置的词语,同时能够关注上下文的词语。解码器(Decoder)通过Encoder-DecoderAttention层,用于解码时对于输入端编码信息的关注;利用掩码(Mask)机制,对序列中每一位置根据之前位置的输出结果循环解码得到当前位置的输出结果。
AI大语言模型的原理、演进及算力测算
GPT是基于Transformer架构的大语言模型,近年迭代演进迅速。 构建语言模型是自然语言处理中最基本和最重要的任务之一。GPT是基于Transformer架构衍生出的生成式预训练的单向语言模型,通过对大量语料数据进行无监督学习,从而实现文本生成的目的;在结构上仅采用Transformer架构的Decoder部分。自2018年6月OpenAI发布GPT-1模型以来,GPT模型迭代演进迅速。GPT-1核心思想是采用“预训练+微调”的半监督学习方法,服务于单序列文本的生成式任务;GPT-2在预训练阶段引入多任务学习机制,将多样化的自然语言处理任务全部转化为语言模型问题;GPT-3大幅增加了模型参数,更能有效利用上下文信息,性能得到跨越式提高;GPT-3.5引入人类反馈强化学习机制,通过使用人类反馈的数据集进行监督学习,能够使得模型输出与人类意图一致。
大语言模型的训练及推理应用对算力需求带来急剧提升。
以GPT-3为例,GPT-3参数量达1750亿个,训练样本token数达3000亿个。考虑采用精度为32位的单精度浮点数数据来训练模型及进行谷歌级访问量推理,假设GPT-3模型每次训练时间要求在30天完成,对应GPT-3所需运算次数为3.1510^23FLOPs,所需算力为121.528PFLOPS,以A100PCle芯片为例,训练阶段需要新增A100GPU芯片1558颗,价值量约2337万美元;对应DGXA100服务器195台,价值量约3880.5万美元。假设推理阶段按谷歌每日搜索量35亿次进行估计,则每日GPT-3需推理token数达7.9万亿个,所需运算次数为4.7610^24FLOPs,所需算力为55EFLOPs,则推理阶段需要新增A100GPU芯片70.6万颗,价值量约105.95亿美元;对应DGXA100服务器8.8万台,价值量约175.12亿美元。