全能不如专精!微软发布Z-code++屠榜文本摘要,参数量仅为PaLM的1/600
![]()
新智元报道

新智元报道
【新智元导读】超大规模预训练模型混战之后,NLP模型该走向何方?
Google发布5400亿参数量的PaLM模型后,NLP预训练似乎走上了海纳百川的路线,即以大量的NLP任务进行训练,以达到全知全能,进而实现解决few-shot任务的能力。
性能是提高了,但对平民玩家来说太不友好了;而且要是用不到多任务的功能,海量参数实际上都是闲置的,性价比超低。
最近,微软的黄学东带队,和第一作者贺鹏程等人共同发表了一项重大的研究成果——全新预训练模型Z-Code++。之后,团队很快也会推出以此为基础的人工智能认知服务抽象式文本摘要API。
Z-Code++仅针对抽象式文本摘要任务进行优化,在5种语言的13个文本摘要任务中,有9个达到新sota性能,成功超越一众大模型,参数量仅为PaLM的600分之一,GPT-3的200分之一,性价比爆棚!

论文地址:https://arxiv.org/abs/2208.09770
在Zeor-shot和Few-shot的任务设置中,Z-code模型的性能仍然领先其他竞争模型。
Z-Code++采用两阶段预训练提升模型在低资源摘要任务上的性能:首先使用大规模文本语料库进行预训练,提升模型的语言理解能力;然后再摘要语料库上针对文本生成任务继续预训练。
在模型设计上,Z-code++将编码器中的自注意力层换成了disentangled注意力层,每个词的表征包含两个向量用来编码内容和位置。模型还使用fusion-in-encoder方法以层次化的方式提升处理长序列的效率。


从通用回归专用
从通用回归专用
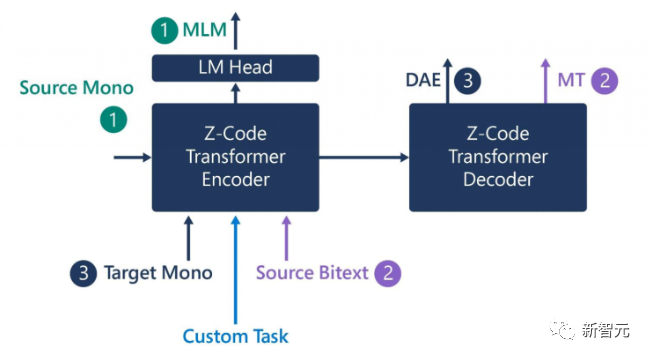
今年初,微软开发了一类全新的AI模型Z-Code,通过迁移学习利用跨多种语言的共享语言元素,将知识从一项任务应用到另一项相关任务,旨在提高机器翻译和其他语言理解任务的质量,并将这些功能扩展到其他小众的语言上。
Z-Code的基本思想很直观:与传统的神经机器翻译方法不同,Z-Code不仅使用多语言的数据在机器翻译任务上进行训练,同时使用单语言数据作为补充,在掩码语言模型(MLM)任务上训练。使用多任务学习,同时优化多个目标函数。模型结构使用标准Transformer的编码器和解码器。
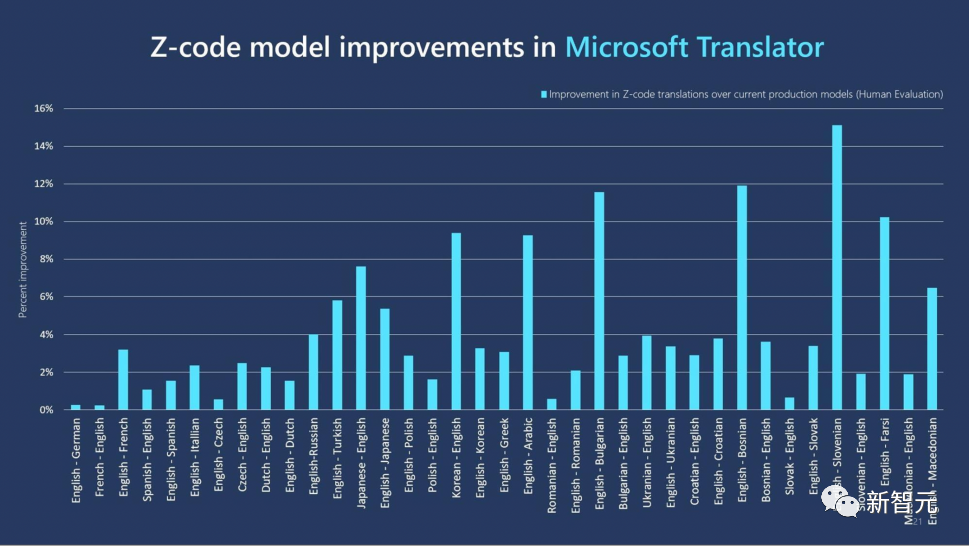
Z-Code的翻译效果非常好,也被应用到微软的各项产品中,以提高机器翻译的质量。
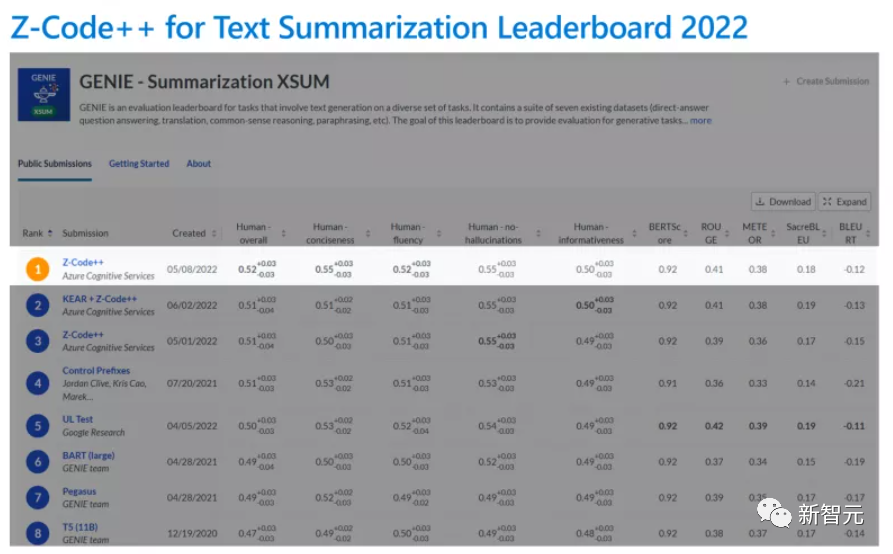
鉴于Z-Code不俗的表现,开发团队又进一步将Z-Code升级拓展为Z-Code++,使其可以完成文本摘要任务,并在GENIE benchmark上取得了第一名的好成绩。
文本摘要(text summarization)是自然语言处理领域的经典任务,输入一段长文本,输出的结果是一段简洁且流畅的摘要,字数更少,但需要保留源文档中的关键内容。
当下的摘要模型可以分为两类,抽取式摘要模型直接从源文本中抽取出重要的内容组成摘要;抽象式摘要模型则是重新组织语言,复述一遍内容以生成摘要。
相比之下,抽象式摘要更灵活,在提升文本摘要质量上更有潜力,所以相关研究也更多。但抽象式摘要模型的开发也更难,模型需要处理诸如语义表征、推理和低资源文本生成等问题。
近期的抽象式文本摘要模型都是基于大规模的预训练语言模型(PLMs),如PEGASUS、GPT、T5进行开发的,虽然这些模型可以生成非常流畅的文本,但生成的摘要往往包含与原文中不一致的事实,这种现象也被称为hallucination问题。
此外,由于源文件中的文本量可能非常大,考虑到当前硬件的内存限制和交互式信息检索的在线文档摘要等应用的延迟限制,训练一个端到端的抽象式文摘模型的代价是很大的。
所以常用的训练模式都是两阶段方法,即先用一个抽取式摘要器粗略地选择文档句子的子集,然后由一个抽象式摘要器在抽取的基础上生成摘要,但这种方法仍然不是最优解,因为在抽取的过程中可能会遗漏重要信息。
Z-code++也是采用两阶段训练方法,分别为language model pre-training和grounded pretraining阶段,主要灵感来源为GODEL模型,其主要用于为文本生成任务预训练模型。
在第一阶段, Z-code++的预训练由两个语言模型任务组成:replaced token detection(RTD)和corrupted span prediction (CSP).
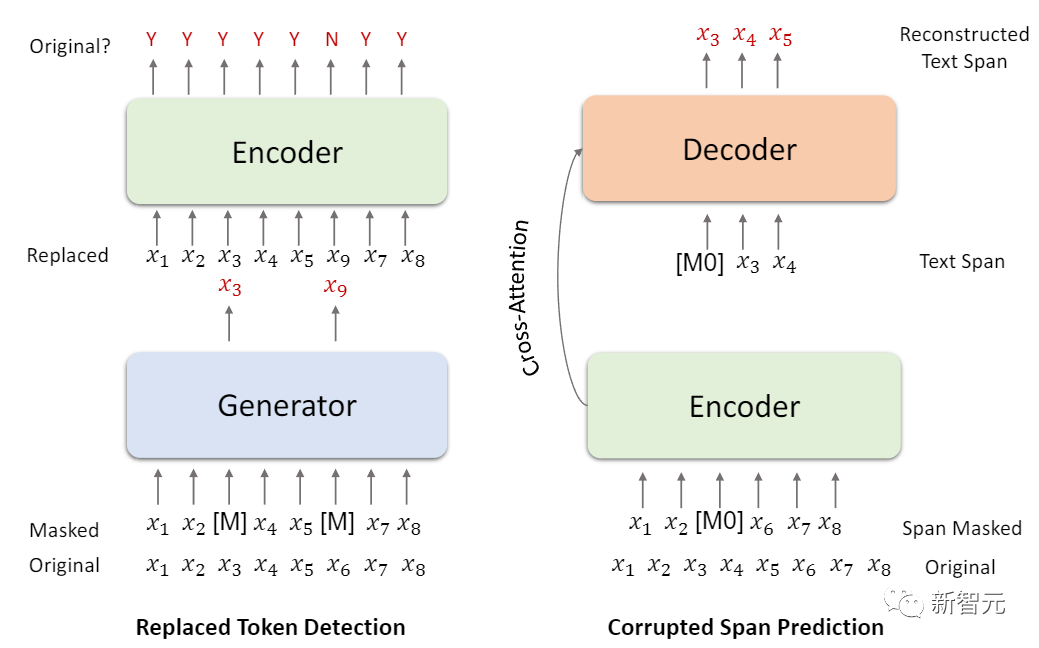
RTD任务使用一个经过MLM训练的生成器来生成一个不明确的标记,以取代原始输入X中的标记,然后用判别器来确定该标记是来自X还是由生成器生成的。
CSP任务广泛用于优化编码器-解码器预训练语言模型,如T5等。给定输入字符串X,首先通过随机选择X中的一个起始位置和一个平均长度为3的span来选择一个连续span。重复这个过程,直到被替换的标记达到X中所有标记的15%。最后将corrupted的输入送入编码器,训练编码器-解码器模型以从上下文中恢复选中的span。
如果将corrupted span限制为一个完整的句子,则CSP等同于GSG任务,模拟了抽取式摘要的过程,已经被证明对于训练抽象式摘要模型来说很有效。
研究人员发现CSP作为gap sentences generation(GSG)的一种更通用的形式,在许多自然语言的理解和生成任务中,包括文本摘要,效果更好。
在第二阶段的grounded预训练中,Z-Code++不断地在一系列文本摘要数据集上进行预训练,数据集由(文档,摘要)对组成,以更好地支持下游摘要任务的低资源微调。
研究人员还为每个训练对添加一个摘要任务的自然语言指令。

另一个优化技巧是在DeBERTa中使用的disentangled attention(DA),扩展了基础的自注意力机制。DA用两个独立的向量表示每个输入词,分别表示内容和位置,词之间的注意力权重是通过对其内容和相对位置的分解矩阵来计算的。
DeBERTa的实验表明,DA比SA更有效地编码了Transformer模型中的位置依赖,Z-Code++在建模中采用了DA,实验结果也表明DA可以训练出一个更有效的抽象式摘要器。
最后是Z-coder对长序列输入的编码。考虑到自注意和DA的二次方内存和计算复杂度,对长序列进行编码是相当费时费力的。
虽然有各种稀疏的注意力机制被提出来以缓解这个问题,但由于注意力精度的降低,稀疏注意力机制往往会损害短序列的性能。
受fusion-in-decoder和hierarchical transformer的启发,研究人员提出了fusion-in-encoder(FiE),通过一种简单而有效的机制来编码长序列,同时在短序列上保留高注意力精度。
FiE的工作原理是将Z-Code++的L个编码器层分离成m个局部层和n个全局层。在每个局部层中,输入序列的隐藏状态被分割成大小为如256或512个小块,自注意(或DA)只应用于这些小块的局部。在局部层之后,这些小块的隐藏状态被级联起来,形成长序列的表示。全局层与编码器中的原始自注意力(或DA)层相同,以融合小块的局部状态。
FiE将编码器的复杂度从O(LN^2)降低到O(mNl+nN^2),而且实验结果可以发现Z-coder++在长文本摘要任务上比为专门为摘要任务设计的LongT5中的机制实现了持平或更好的性能。
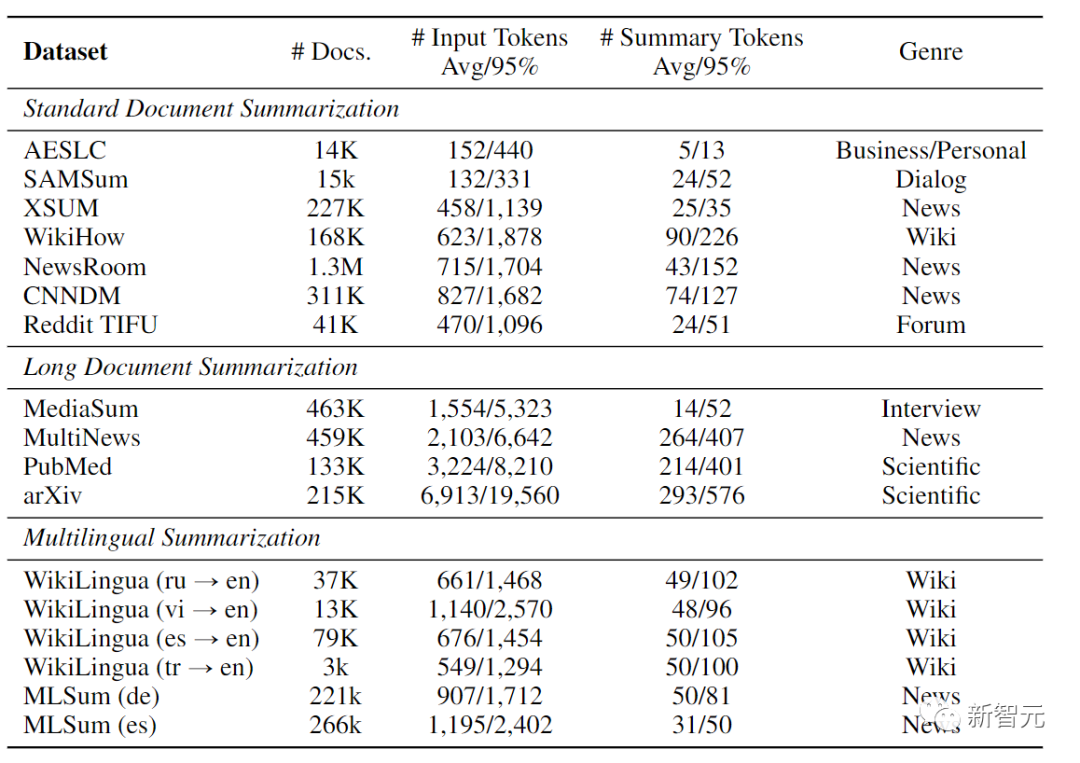
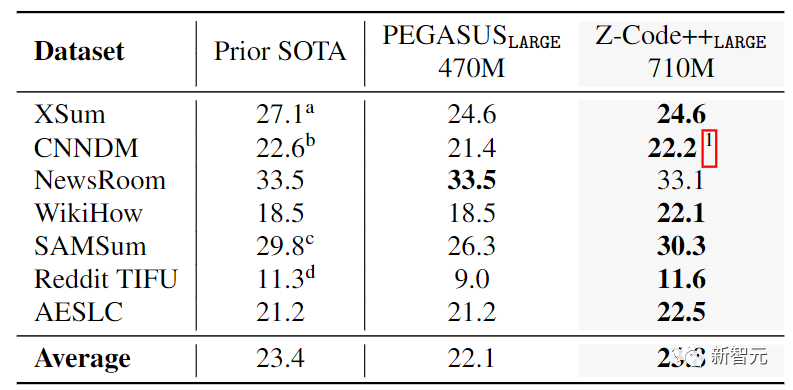
在实验部分,研究人员将Z-Code++和PEGASUS在7个具有代表性的标准公共英语摘要数据集上的性能进行比较,这些数据集的文档长度适中,包括AESLC、SAMSum、XSUM、WikiHow、NewsRoom、CNN/DailyMail(CNNDM),以及Reddit TIFU
可以看到Z-Code++在7个任务中的6个任务中,在ROUGE-2的F评分比PEGASUS取得了很大的改进。
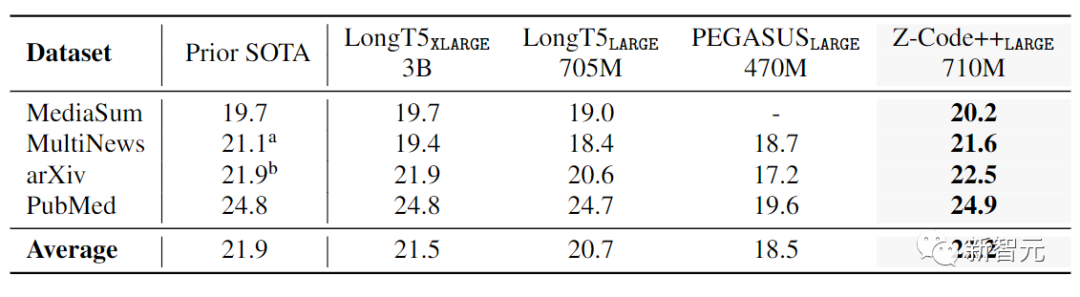
在长文本实验中,将Z-Code++与PEGASUS和LongT5进行比较后可以看到,Z-coder++依然是SOTA,并将平均最高分提升了0.35,而参数量还不到LongT5-3B的三分之一。
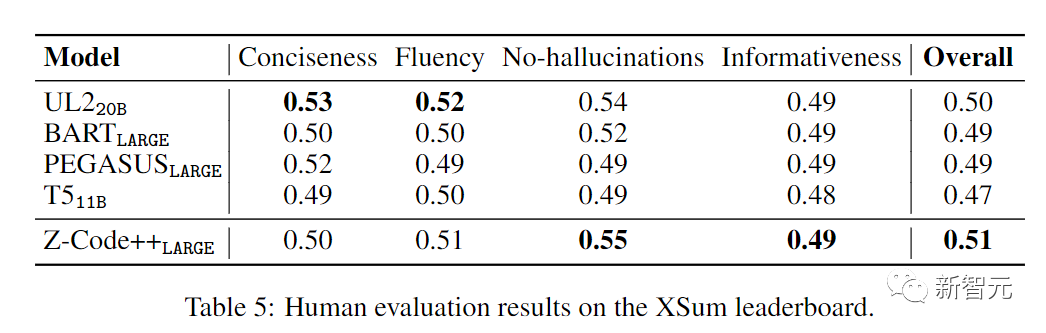
在XSum排行榜进行人工评价后,Z-coder++仍然从整体上来看是最高分,达到0.51
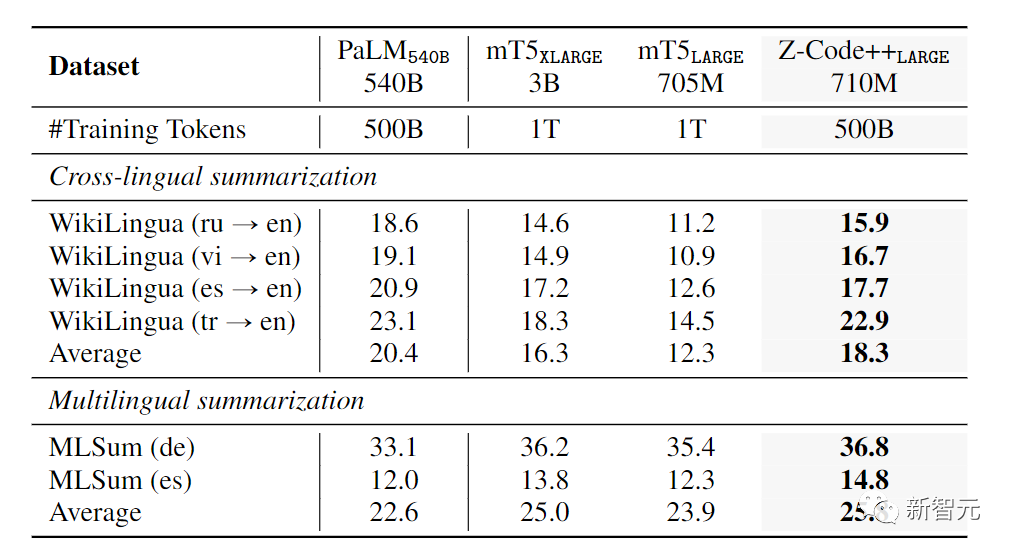
在多语言文摘评价上,研究人员在GEM基准上进行测试后,可以发现Z-coder++用了更少的训练数据,更少的参数量就达到了更好的性能。Zcode和Zcode++为微软认知服务机器翻译和文本摘要API提供了强大的技术基础。