

**摘要: **传统的多标签分类算法大多数采用监督学习的方式,但现实生活中有许多数据没有被标记。通过人工的方式对需要的全部数据进行标记耗费的成本较高。半监督学习算法可以使用大量未标记数据和标记数据来进行工作,因此受到了人们的重视。文中首次从监督和半监督学习的角度对多标签分类算法进行阐述,同时全面地对多标签分类算法的应用领域进行了总结。从决策树、贝叶斯、支持向量机、神经网络和集成等多个方向对标签非相关性和标签相关性的监督学习算法进行概述,从批处理和在线的方向对半监督学习算法进行综述,从图像分类、文本分类和其他等角度对多标签的实际应用领域进行介绍。文中还简要分析了多标签的评估指标,最后给出了关于半监督学习下的复杂概念漂移处理、特征选择处理、标签复杂相关性处理和类不平衡处理的研究方向。
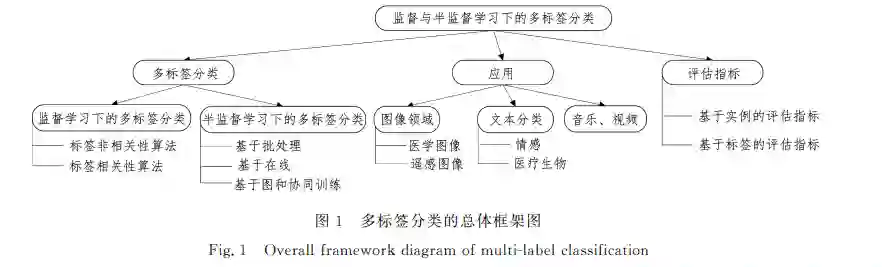
随着大数据技术的快速发展,生活中产生了大量的数据, 这些数据中包含着与人类生活密切相关的许多信息,为了从 中获得需要 的 数 据,学 者 开 展 了 许 多 与 数 据 挖 掘 有 关 的 研 究[1].传统的分类方法侧重于对单标签进行分类,然而,许多 现实问题却需要使用多标签分类(MultiGlabelClassification, MLC)[2]来解决. 给定一个d维输入空间X=X1××Xd 和一个输出标 签Y={λ1,λ2,,λq},q>1.多标签实例可以定义为一对(x, y),其中x=(x1,,xd)∈X 并且y⊆Y,其中y 被称为标签 集.当标签j和实例x 相关时,λj等于1,否则等于0.MLC 的目标是构建一个预测模型h:X→2Y ,为未知实例提供一组 相关标签.每个实例可能有几个与其相关的标签,这些标签 来自先前定义的标签集.因此,对于每个x∈X,有标签空间 Y 的二分集合(y,y -),其中y 是相关标签的集合,y - 是不相关 标签的集合. MLC主要可以应用于文本分类[3]、医学诊断分类[4]、蛋 白质分类[5]、音乐[6]或视频分类[7]等.例如,在文本分类中, 关于神州十二号发射的报道可以归类为社会类别,也可以归 类为科技类别.类似地,在医学诊断分类中,一位病人可以同 时患有糖尿病和高血压疾病. 经典的 MLC方法主要分为问题转化(ProblemTransforG mation,PT)和算法自适应(Algorithm Adaptation,AA).PT 是将多标签问题转化成多个简单的单标签分类问题,其中最 常用的是二元相关(BinaryRelevance,BR)方法.BR 方法将 多标签分类问题转化为|L|个不同的二元单标签分类问题, 转化后,选择任何现有的二元单标签分类算法作为基分类器. BR方法未考虑标签之间的相关性,为了解决这一问题,研究 人员提出了分类器链方法(ClassifierChains,CC)[8],它是在 BR算法的基础上,通过链的方法连接由 BR 获得的二元分类 器.标签幂集(LabelPowerGSet,LP)方法也是一种 PT 方法, LP是将多标签问题转化为具有 2|L| 个类标签的多 类问题. 随机子标签集成算法(Random KGLabelsets,RAkEL)[9]是对 LP方法的一种集成使用,其中每个 LP基分类器都是由随机 生成的且互不相同的小规模标签子集训练而成.AA 是修改 现有的算法以适应需要解决的新问题,具体表现为将现有的 单标签分类问题调整为 MLC问题.构建 AA的流行模型包括 k近邻[10]、决策树[11]、支持向量机[12]、神经网络[13]等. 近年来,已有一些关于 MLC 的综述.Zhang等[14]介绍 了多标签学习的基础知识,对8种经典的算法进行了分析和 讨论,总结了多标签学习的在线资源等.Tsoumakas等[15]从 PT和 AA 的角度对多标签进行分类的方法进行了详细的介 绍,简单介绍了一些评估指标,最后比较了 MLC方法的实验 结果.Moyano等[16]对20个数据集上的多标签集成分类算 法进行了比较,根据数据不平衡、标签间相关性的特征来评价 它们的性能.Zhou等[17]针对评估措施和标签相关性问题对 多标签学习进行了讨论,同时讲述了4种具有代表性的多标 签算法的基本思想和技术细节.Zheng等[18]从多标签数据流 分类的角度介绍了 传 统 的 MLC 方 法 并 讨 论 了 它 们 的 优 缺 点,确定了多标签数据流分类的挖掘约束.至今为止,还没有 综述从监督学习和半监督学习的角度对 MLC 进行介绍,同 时也没有综述对多标签的实际应用进行全面的介绍.本文的 总体框架如图1所示.
本文的主要贡献有: (1)首次从监督学习和半监督学习两个方面对 MLC 算 法进行了综述,角度更加新颖、全面. (2)首次从实际应用领域对 MLC 算法进行了全面的综 述,总结了近年来应用领域的先进算法. (3)深入分析了 MLC算法中存在的问题,并提出了未来 的研究方向.



