摘要
文本分类是自然语言处理中最基本、最基本的任务。过去十年,由于深度学习取得了前所未有的成功,这一领域的研究激增。大量的方法、数据集和评价指标已经在文献中提出,提高了全面和更新综述的需要。本文通过回顾1961年到2020年的先进方法的现状来填补这一空白,侧重于从浅到深的模型学习。我们根据所涉及的文本和用于特征提取和分类的模型创建文本分类的分类法。然后我们详细讨论每一个类别,处理支持预测测试的技术发展和基准数据集。本综述还提供了不同技术之间的综合比较,以及确定各种评估指标的优缺点。最后,总结了本研究的关键意义、未来研究方向和面临的挑战。
介绍
在许多自然语言处理(NLP)应用中,文本分类(为文本指定预定义标签的过程)是一个基本和重要的任务, 如情绪分析[1][2][3],主题标签[4][5][6],问答[7][8][9]和对话行为分类。在信息爆炸的时代,手工对大量文本数据进行处理和分类是一项耗时且具有挑战性的工作。此外,手工文本分类的准确性容易受到人为因素的影响,如疲劳、专业知识等。人们希望使用机器学习方法来自动化文本分类过程,以产生更可靠和较少主观的结果。此外,通过定位所需信息,可以提高信息检索效率,缓解信息超载的问题。 图1给出了在浅层和深层分析的基础上,文本分类所涉及的步骤流程图。文本数据不同于数字、图像或信号数据。它需要NLP技术来仔细处理。第一个重要的步骤是对模型的文本数据进行预处理。浅层学习模型通常需要通过人工方法获得良好的样本特征,然后用经典的机器学习算法对其进行分类。因此,特征提取在很大程度上制约了该方法的有效性。然而,与浅层模型不同,深度学习通过学习一组直接将特征映射到输出的非线性转换,将特征工程集成到模型拟合过程中。
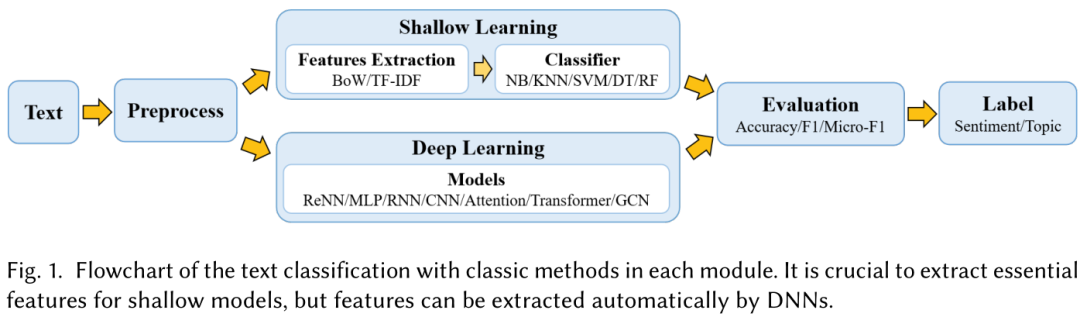
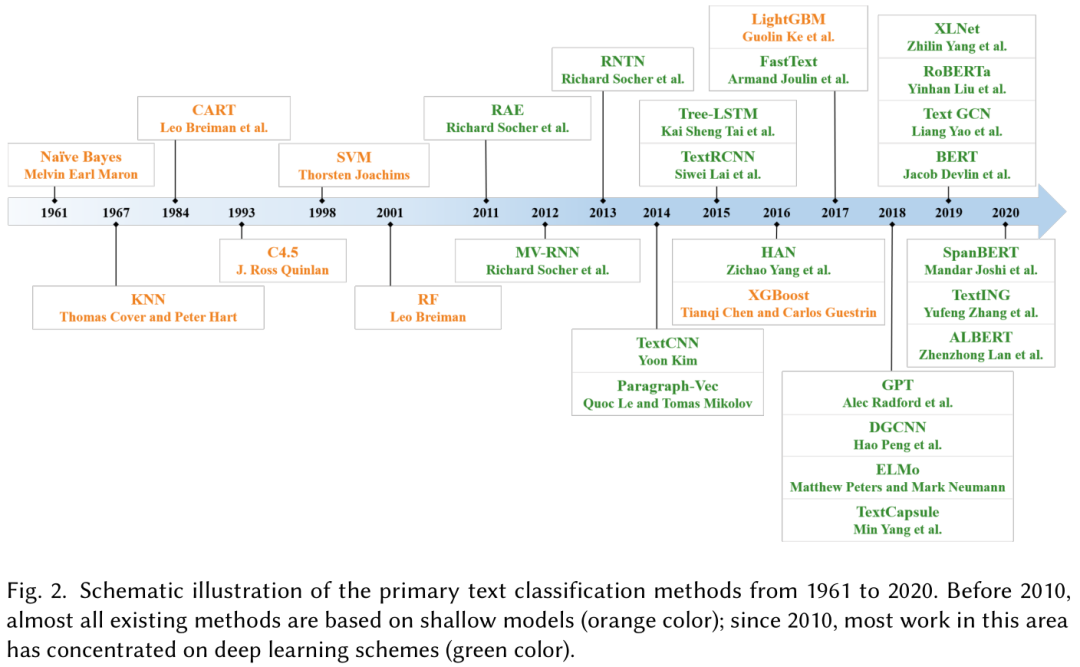
主要文本分类方法的示意图如图2所示。从20世纪60年代到21世纪10年代,基于浅层学习的文本分类模型占据了主导地位。浅层学习意味着在乐此不疲的模型,如 NaÃŕve Bayes(NB)[10], K-近邻(KNN)[11],和支持向量机(SVM)[12]。与早期基于规则的方法相比,该方法在准确性和稳定性方面具有明显的优势。然而,这些方法仍然需要进行特征工程,这是非常耗时和昂贵的。此外,它们往往忽略文本数据中自然的顺序结构或上下文信息,使学习词汇的语义信息变得困难。自2010年代以来,文本分类逐渐从浅层学习模式向深度学习模式转变。与基于浅层学习的方法相比,深度学习方法避免了人工设计规则和特征,并自动提供文本挖掘的语义意义表示。因此,大部分文本分类研究工作都是基于DNNs的,这是一种计算复杂度很高的数据驱动方法。很少有人关注于用浅层学习模型来解决计算和数据的局限性。
在文献中,Kowsari等[13]考虑了不同的文本特征提取、降维方法、文本分类的基本模型结构和评价方法。Minaee等人[14]回顾了最近基于深度学习的文本分类方法、基准数据集和评估指标。与现有的文本分类研究不同,我们利用近年来的研究成果对现有的模型进行了从浅到深的总结。浅层学习模型强调特征提取和分类器设计。一旦文本具有精心设计的特征,就可以通过训练分类器来快速收敛。在不需要领域知识的情况下,DNNs可以自动进行特征提取和学习。然后给出了单标签和多标签任务的数据集和评价指标,并从数据、模型和性能的角度总结了未来的研究挑战。此外,我们在4个表中总结了各种信息,包括经典浅层和深度学习模型的必要信息、DNNs的技术细节、主要数据集的主要信息,以及在不同应用下的最新方法的一般基准。总而言之,本研究的主要贡献如下:
-
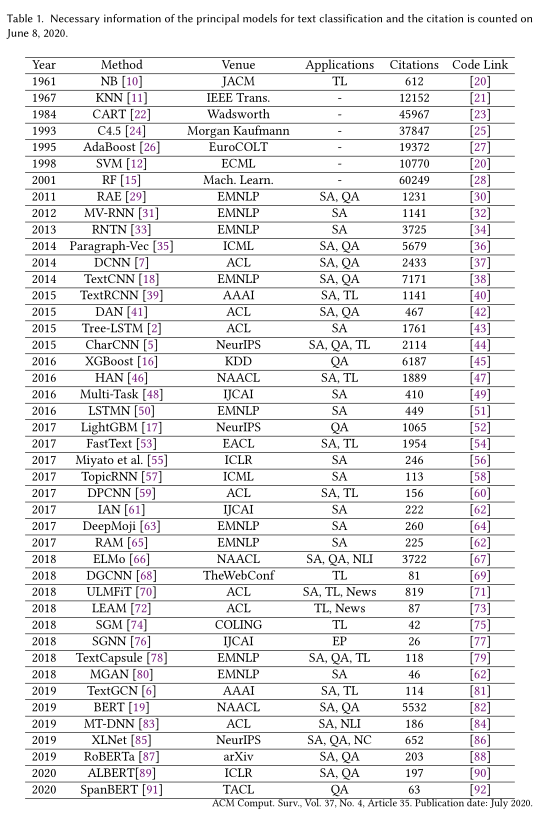
我们在表1中介绍了文本分类的过程和发展,并总结了经典模式在出版年份方面的必要信息,包括地点、应用、引用和代码链接。
-
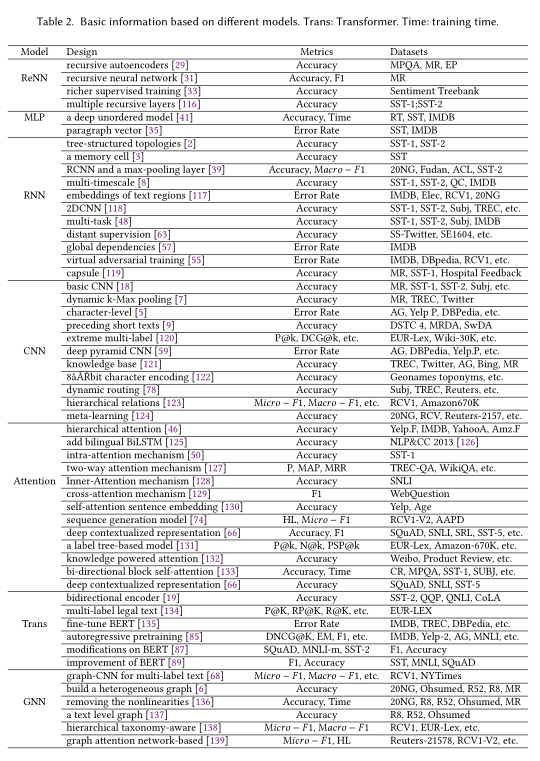
根据模型结构,从浅层学习模型到深度学习模型,对主要模型进行了全面的分析和研究。我们在表2中对经典或更具体的模型进行了总结,并主要从基本模型、度量和实验数据集方面概述了设计差异。
-
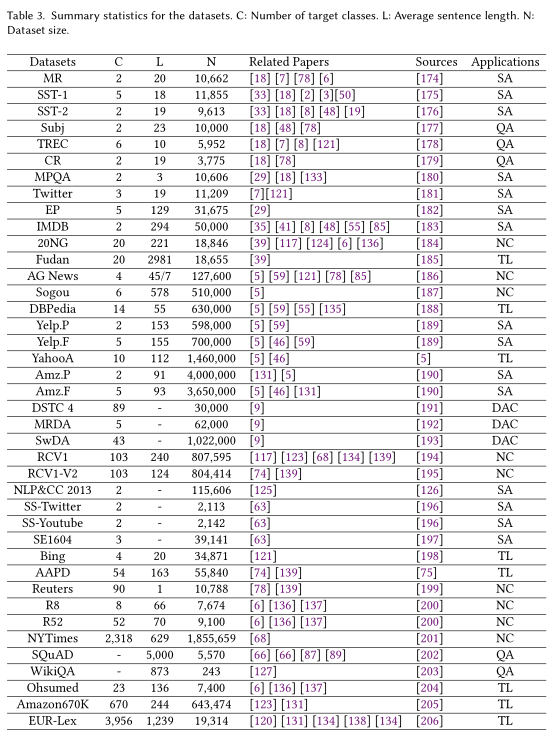
我们介绍了现有的数据集,并给出了主要的评价指标的制定,包括单标签和多标签文本分类任务。我们在表3中总结了基本数据集的必要信息,包括类别的数量,平均句子长度,每个数据集的大小,相关的论文和数据地址。
-
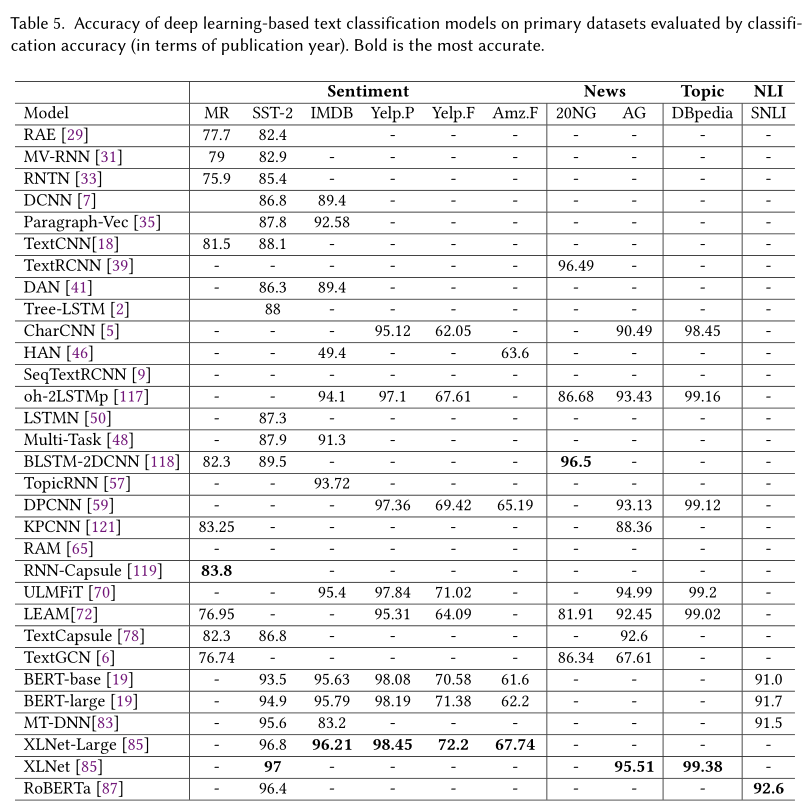
我们在表5中总结了经典模型在基准数据集上的分类精度得分,并通过讨论文本分类面临的主要挑战和本研究的关键意义来总结综述结果。