首篇自监督学习推荐系统综述: 150篇文献概述四大类方法(含开源算法库SELFRec)

论文:https://arxiv.org/abs/2203.15876
-
首先对基于自监督学习方法的推荐系统(SSR)进行全面的综述,力求尽可能多的调研相关文献,该文是该领域方向的首篇综述; -
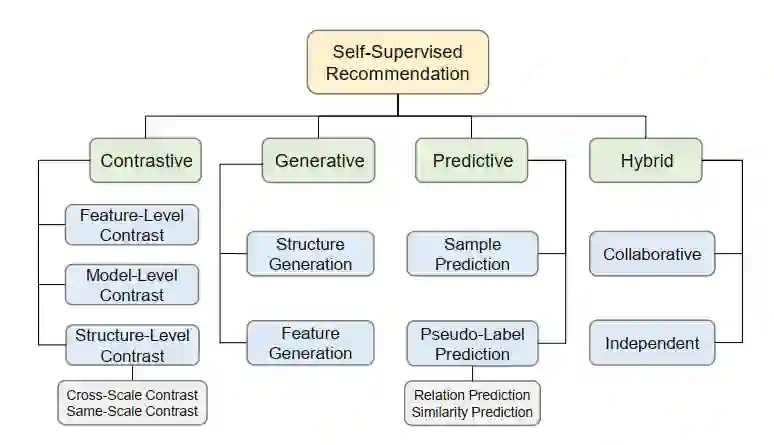
该文提出了针对于SSR的专属定义,并且提出了一个综合的分类视角,即将当前的SSR方法归纳为了对比式方法、生成式方法、预测式方法与混合方法。针对每一类方法,该文详细的阐述了其概念、公式、相关方法以及优缺点分析。 -
本文提出了一个开源工具包SELFREC,其包括了多个基准数据集以及评价指标,另外还实现了超10种SSR算法。
-
最后,本文介绍了该方向的局限性,并总结了剩余的挑战与未来研究方向。
自监督学习的问世为推荐系统领域提供了一种缓解数据稀疏问题的新视角,通过总结在推荐系统领域运用自监督学习技术的方式,该文总结了关于SSR的基本特征:
通过半自动化的方式获取更多的监督信号。
-
通过一个辅助任务利用增强的数据来微调推荐系统。 -
辅助任务(Pretext task)协助推荐系统任务(Primary task)来完成更高性能的推荐模型。
其中,1确定了SSR的基本范围,2确定了SSR区别于推荐系统其他领域的问题设置,3阐述了与推荐主任务与辅助任务的关系。
对于SSR的分类
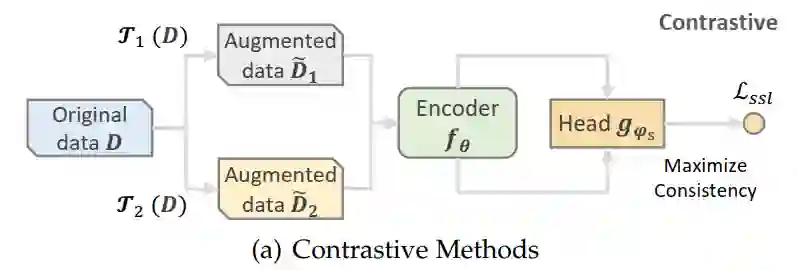
其中,对比式方法主要思想是通过数据增强任务来拉进两个相近实例的表示,拉远两个不相近实例的距离。

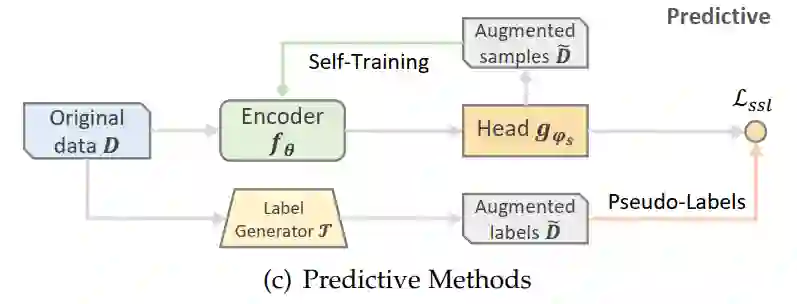
其中,预测式方法与生成式方法类似,其都拥有预测任务。主要思想是利用半监督学习技术来预测富有信息量的新样本或者伪标签。
其中,混合式方法主要思想是集成上述提及的任务一种或者多种辅助任务,并利用不同的权重将其整合起来。

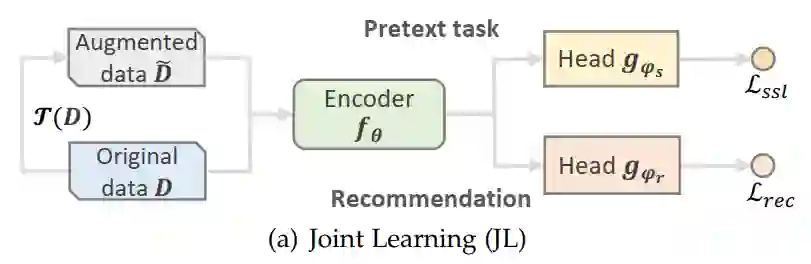
通过推荐主任务与辅助任务的整合方式,其可以分为三种类型的训练范式,即联合训练模式,预训练与微调模式与综合训练模式。
其中,联合训练模式主要框架是通过一个共享的编码器来同时优化主任务与辅助任务。

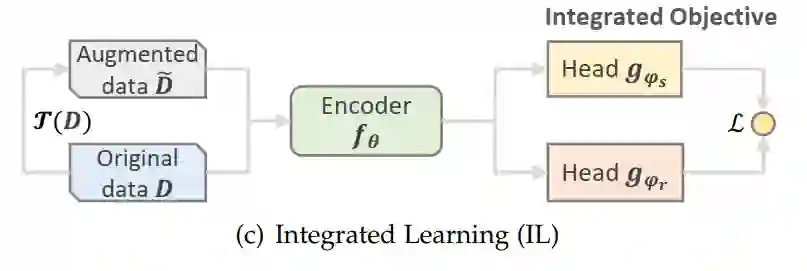
其中,综合训练模式相对较少,主要框架是通过将主任务与辅助任务进行对齐进而利用整体的损失函数进行优化。
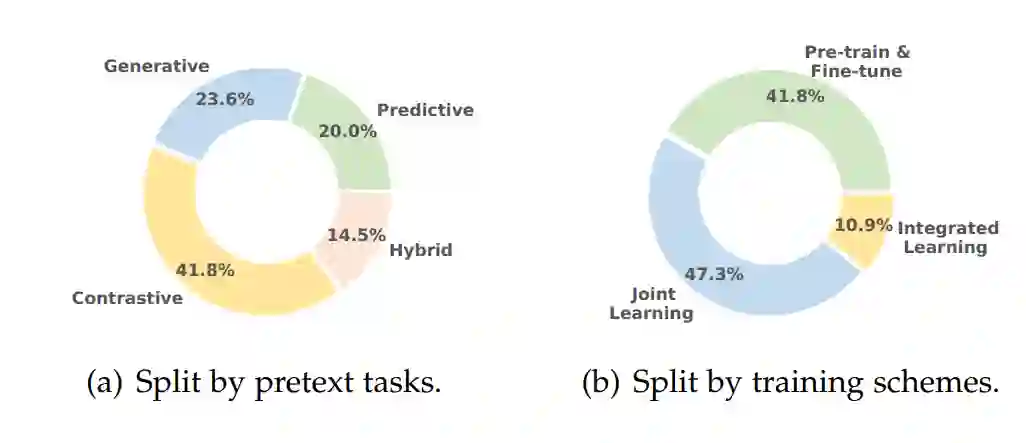
本文根据辅助任务与训练模式分别进行统计,发现生成式SSR与对比式SSR占比较高;联合训练模式的SSR方法与预训练模式的SSR方法是其主要使用的训练框架。
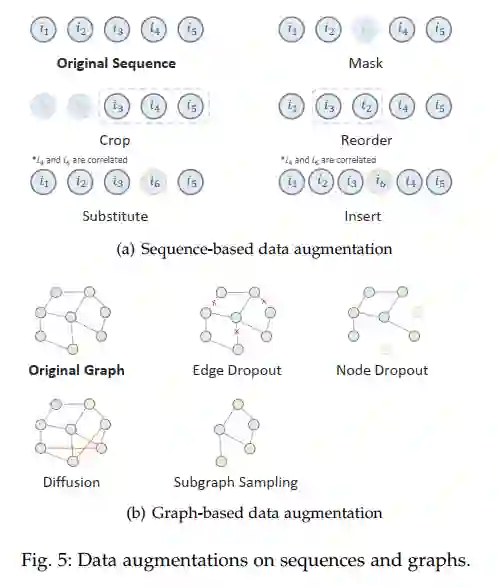
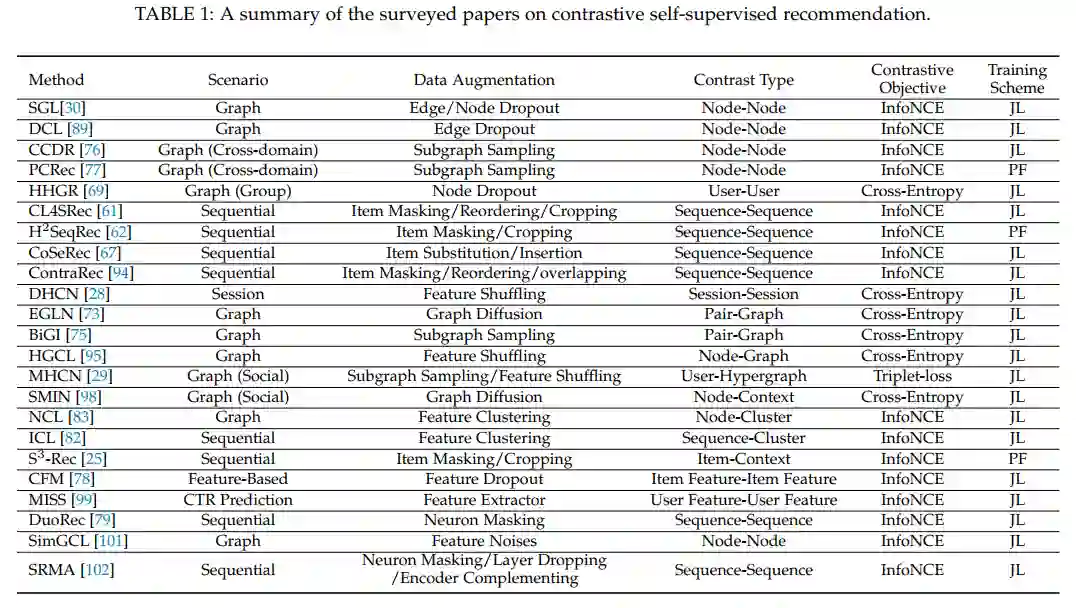
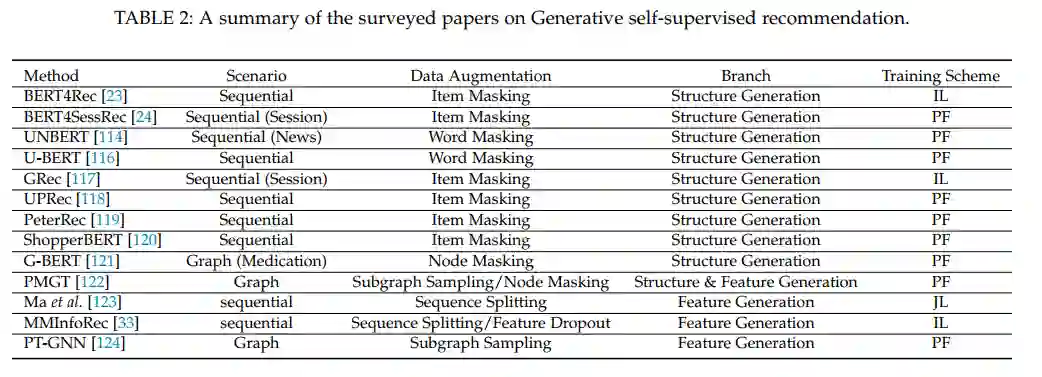
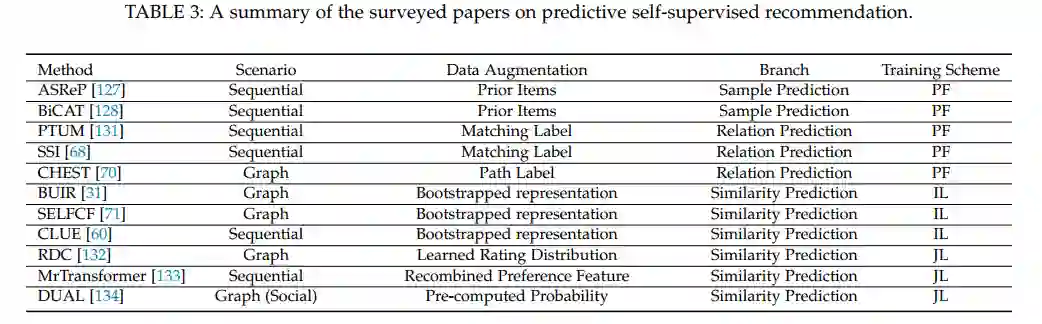
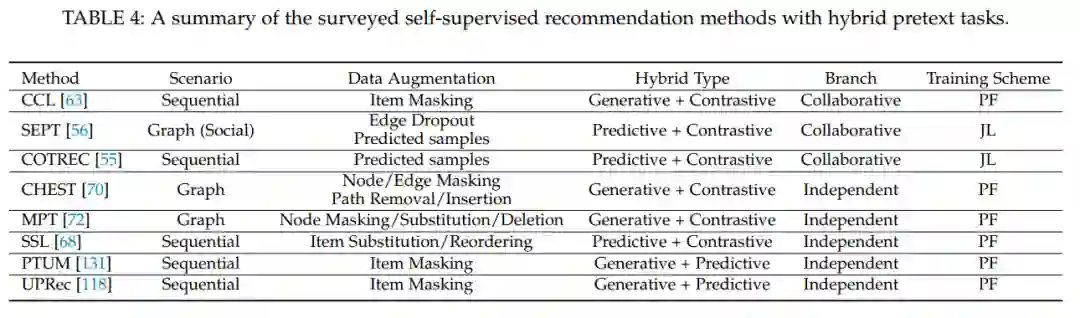
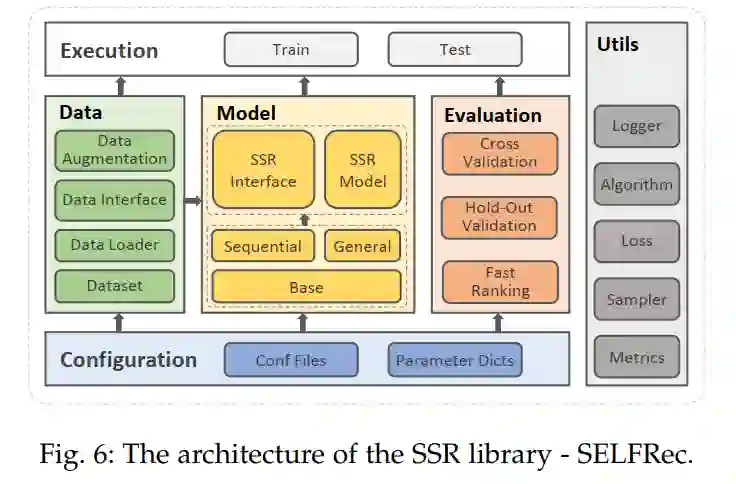
最后,本文提出了SSR方向一些潜在的挑战与未来研究方向。比如,对于数据增强选择的理论证明、基于自监督推荐系统的可解释性、基于预训练推荐模型的攻击与防御、移动边缘设备上的自监督推荐模型等以及通用预训练方法等。
欢迎干货投稿 \ 论文宣传 \ 合作交流
推荐阅读
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
由于公众号试行乱序推送,您可能不再准时收到机器学习与推荐算法的推送。为了第一时间收到本号的干货内容, 请将本号设为星标,以及常点文末右下角的“在看”。
登录查看更多
相关内容

Arxiv
15+阅读 · 2018年5月24日




相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2018年5月24日