《文本分类大综述:从浅层到深度学习》最新2020版35页pdf

01
摘要
01
介绍
在许多自然语言处理(NLP)应用中,文本分类(为文本指定预定义标签的过程)是一个基本和重要的任务, 如情绪分析[1][2][3],主题标签[4][5][6],问答[7][8][9]和对话行为分类。在信息爆炸的时代,手工对大量文本数据进行处理和分类是一项耗时且具有挑战性的工作。此外,手工文本分类的准确性容易受到人为因素的影响,如疲劳、专业知识等。人们希望使用机器学习方法来自动化文本分类过程,以产生更可靠和较少主观的结果。此外,通过定位所需信息,可以提高信息检索效率,缓解信息超载的问题。
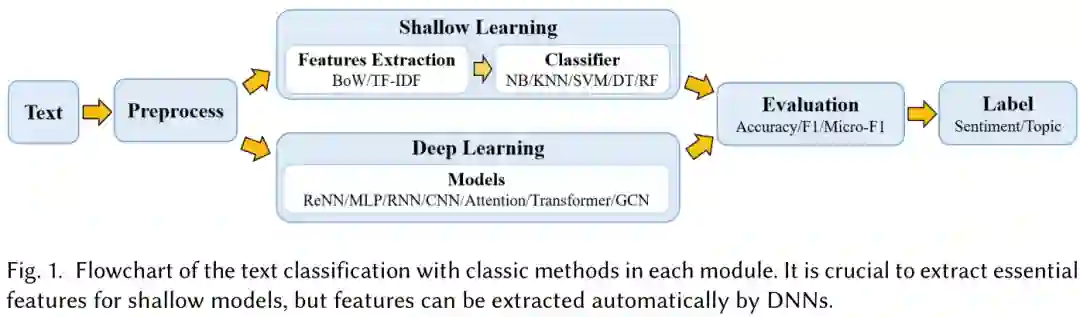
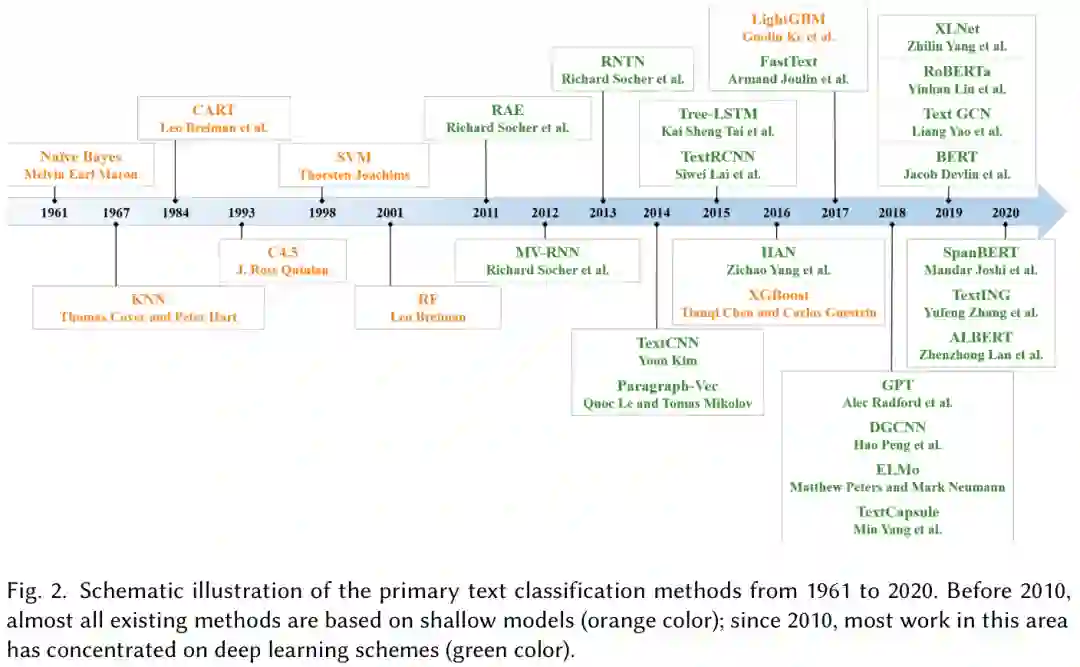
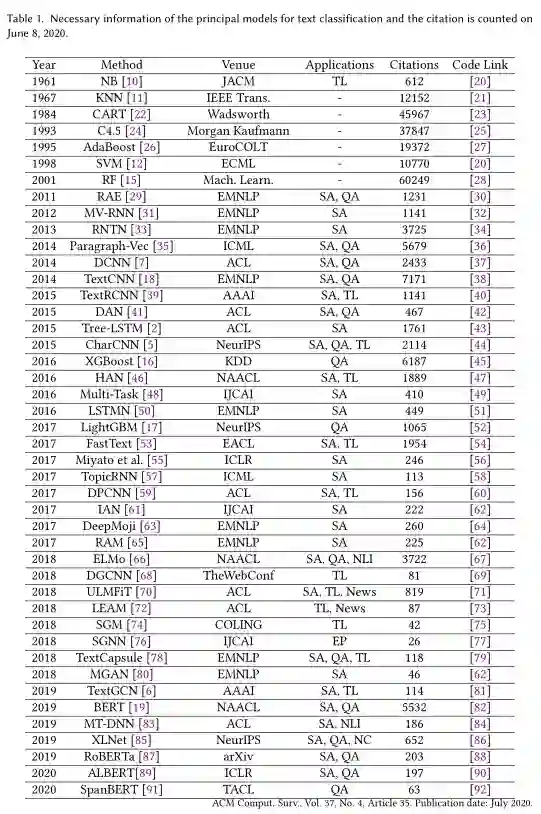
我们在表1中介绍了文本分类的过程和发展,并总结了经典模式在出版年份方面的必要信息,包括地点、应用、引用和代码链接。
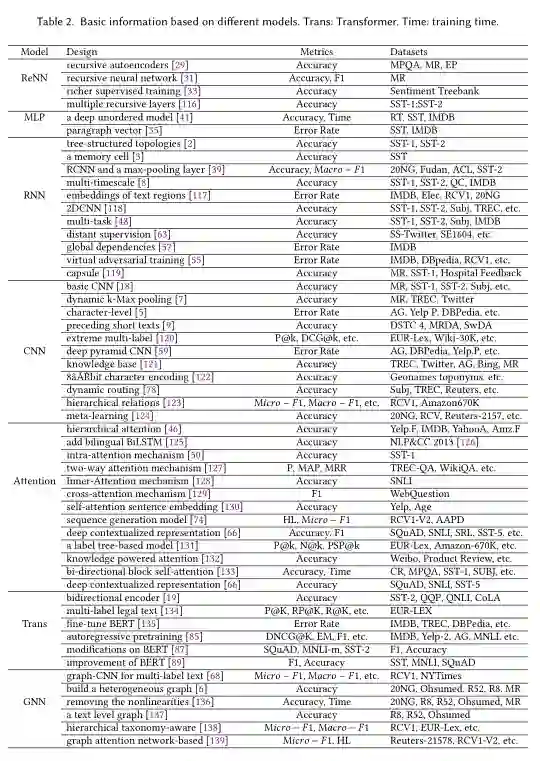
根据模型结构,从浅层学习模型到深度学习模型,对主要模型进行了全面的分析和研究。我们在表2中对经典或更具体的模型进行了总结,并主要从基本模型、度量和实验数据集方面概述了设计差异。
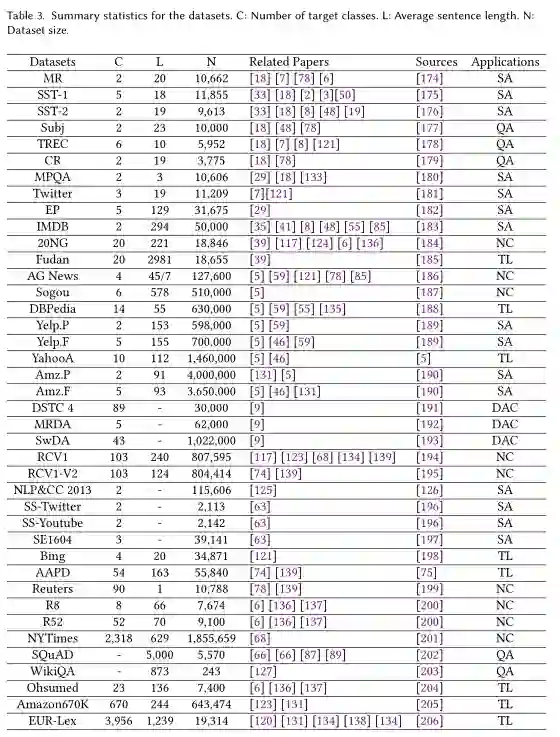
我们介绍了现有的数据集,并给出了主要的评价指标的制定,包括单标签和多标签文本分类任务。我们在表3中总结了基本数据集的必要信息,包括类别的数量,平均句子长度,每个数据集的大小,相关的论文和数据地址。
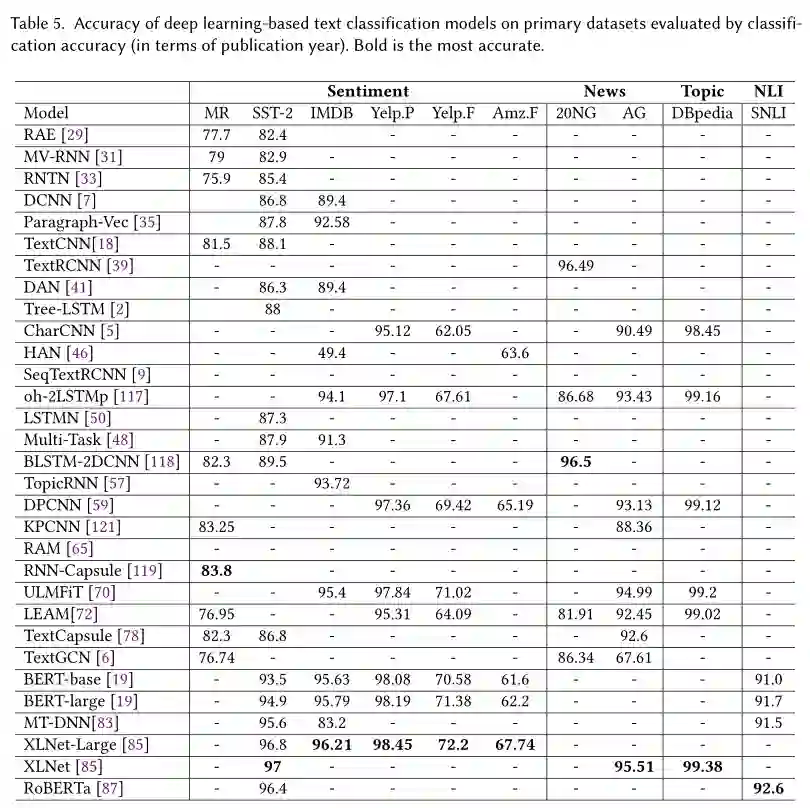
我们在表5中总结了经典模型在基准数据集上的分类精度得分,并通过讨论文本分类面临的主要挑战和本研究的关键意义来总结综述结果。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“STCSDL” 可以获取《【文本分类大综述:从浅层到深度学习,35页pdf】》专知下载链接索引


登录查看更多
相关内容

Arxiv
20+阅读 · 2020年3月10日




相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2020年3月10日