干货|多重预训练视觉模型的迁移学习
微信公众号
关键字全网搜索最新排名
【机器学习算法】:排名第一
【机器学习】:排名第一
【Python】:排名第三
【算法】:排名第四
源 | 全球人工智能
本文介绍的是基于Keras Tensorflow抽象库建立的迁移学习算法模型,算法简单、易于实现,并且具有很好的效果。
许多被称为“深度学习”的方法已经出现在机器学习和数据科学领域。在所有的这些“深度学习”方法中,有一种尤为突出,即对已学习representations的迁移,其有一种方法在迁移已学习的representations时,其简洁性、鲁棒性、有效性尤为突出。尤其是在计算机视觉领域,这个方法展示出了空前的优势,使以前难以克服的任务变得像keras.applications import *一样容易。
简而言之,这个方法规定应该使用一个大型的数据集学习将所感兴趣的对象(如图像,时间序列,客户,甚至是网络)表示为一个特征向量,以适合数据科学研究任务,如分类或聚类。一旦学习完毕,representation机制就可供其他研究人员或其他数据集使用, 而几乎不需要考虑新数据的数据量或可用计算资源的大小。
本文我们展示了基于预训练计算机视觉模型的迁移学习的用途,并使用了keras TensorFlow抽象库。预训练计算机视觉模型已经在大型ImageNet数据集上进行了训练,并学会了以特征向量的形式生成图像的简单表示。这里,我们将利用这个机制学习一个鸟类分类器。
能够使用预训练模型的方法有很多,其选择通常取决于数据集的大小和可用的计算资源,这些方法包括:
1.微调(Fine tuning):在这种情况下,用适当大小的softmax层替换网络的最终分类层,以适应当前的数据集,同时其他所有层的学习参数保持不变,然后在新任务上进行更进一步的训练。
2.冻结(Freezing):fine-turning方法需要相对较强的计算能力和较大的数据量。对于较小的数据集,通常“冻结”网络的一些第一层,这就意味着预训练网络的参数在这些层中是固定的。其他层在新任务上像以前一样进行训练。
3.特征提取(Feature extraction):这种方法是预训练网络最宽松的一种用法。图像经过网络前馈,将一个特定的层(通常是在最终分类器输出之前的一个层)作为一个representation,其对新任务绝对不会再训练。这种图像-矢量机制的输出,在后续任何任务中几乎都可以使用。
本文我们将使用特征提取方法。首先,我们使用单个预训练深度学习模型,然后使用堆叠技术将四个不同的模型组合在一起。然后再对CUB-200数据集进行分类,这个数据集(由vision.caltech提供)包括200种被选中的鸟类图像。

首先,下载数据集,MAC/Linux系统下载路径:

或者,只需手动下载并解压文件即可。
接下来将描述程序中的主要元素。我们省略了导入和部署代码,以支持可读性更好的文本,如有需要请查看完整代码。
让我们从加载数据集开始,用一个效用函数(here)来加载具有指定大小的图像的数据集。当解压数据集时创建了“CUB_200_2011”文件夹,常量CUB_DIR指向该文件夹中的“image”目录。

首先,我们将用Resnet50模型(参见论文和keras文件)进行特征提取。注意,我们所使用的是大小为244X244像素的图像。为了生成整个数据集的向量representations,需要添加以下两行代码:

当模型被创建时,使用preprocess_input函数对初始训练数据(ImageNet)进行规范化,即求出平均信道像素值的减法结果。ResNet50.predict进行实际转换,返回代表每个图像大小为2048的向量。当首次被调用时,ResNet501d[1]的构造器会下载预训练的参数文件,所需时间长短取决于您的网速。之后,用这些特征向量和简单的线性SVM分类器来进行交叉验证过程。
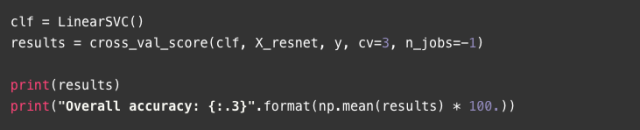
[ 0.62522158 0.62344583 0.62852745]
Overall accuracy: 62.6
通过这个简单的方法,我们在200类数据集上达到了62.6%的准确度。在接下来的部分中,我们将使用几个预先训练好的模型和一个叠加方法来继续改进这个结果。
使用多个预训练模型后,感觉与任何情况下使用一个特征集的情况相同:它们希望提供一些不重叠的信息,从而使组合时性能更优越。
我们将使用的方法来自这四个预训练模型(VGG19, ResNet, Inception, and Xception)派生出的特性,被统称为“stacking”。Stacking是一个两阶段的算法,在此算法中,一组模型(基础分类器)的预测结果被聚合并传送到第二阶段的预测器中(元分类器)。在这个例子中,每个基本分类器将是一个简单的逻辑回归模型。然后求出这些输出概率的平均数,并传送到一个线性SVM算法中来提供最终决策。

每个预训练的模型(如上述的ResNet)都可以生成特征集(X_vgg, X_resnet, X_incept, X_xcept),我们以此作为开始(完整的代码请参阅git repo)。方便起见,将所有的特征集合叠加到一个单独的矩阵中,但是保留边界索引,以便每个模型都可以指向正确的集合。

我们将使用功能强大的mlxtend扩展库,使stacking算法变得更加容易。对于四个基本分类器中的任何一个,我们都构建了一个可以选择适当特性的传递方法,并遵循LogisticRegression算法的途径。

定义并配置堆叠分类器,以使用每个基本分类器提供的平均概率作为聚合函数。

最后,我们准备测试stacking方法:

[ 0.74221322 0.74194367 0.75115444]
Overall accuracy: 74.5
提供一些基于模型的分类器,并利用这些单独的被预先训练过的分类器的stacking方法,我们获得了74.5%的精确度,与单一的ResNet模型相比有了很大的提升(人们可以用同样的方法测试其它模型,来对两种方法进行比较)。
综上所述,本文描述了利用多个预训练模型作为特征提取机制的方法,以及使用stacking算法将它们结合起来用于图像分类的方法。这种方法简单,易于实现,而且几乎会产生出人意料的好结果。
[1]深度学习模型通常是在GPU上训练,如果您使用的是低端笔记本GPU,可能不适合运行我们这里使用的一些模型,因为会导致内存溢出异常,如果是这样,那么您应该强制TensorFlow运行CPU上的所有内容,将所有深度学习相关的内容放到一个带有tf.device("/cpu:0"): 的块下面。
近期热文
干货 | 自然语言处理(3)之词频-逆文本词频(TF-IDF)详解
机器学习(32)之典型相关性分析(CCA)详解 【文末有福利......】
加入微信机器学习交流群
请添加微信:guodongwe1991
备注姓名-单位-研究方向
广告、商业合作
请添加微信:guodongwe1991
(备注:商务合作)





