

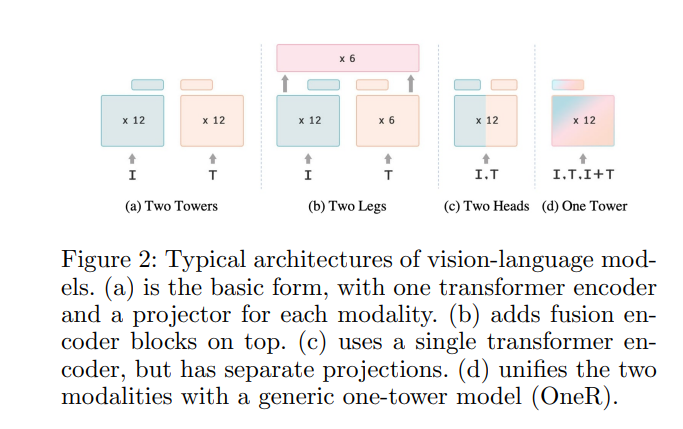
对比学习是远程学习的一种形式,旨在从两种相关表示中学习不变特征。在本文中,我们探索了一个大胆的假设,即图像及其标题可以被简单地视为潜在相互信息的两种不同视图,并训练一个模型学习统一的视觉-语言表示空间,该空间以模态不可知的方式对两种模态进行编码。我们首先确定了学习视觉语言预训练(VLP)的通用单塔模型的困难,并提出OneR作为实现我们目标的一个简单而有效的框架。发现了一些有趣的特性,将OneR与之前学习特定模态表示空间的工作区分开,如零样本物体定位、文本引导的视觉推理和多模态检索,并提出了分析,以提供对这种新的多模态表示学习形式的见解。本文全面的评估证明了一个统一的模式不可知VLP框架的潜力。
https://www.zhuanzhi.ai/paper/4e17357dee62d9195ef21f2d22320c40
成为VIP会员查看完整内容
相关内容
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
相关主题

相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日