AAAI2022 预训练中的多模态信息融合与表征探究
![]()
引言
![]()

引言

![]()
文章概览
![]()
文章概览
论文地址:https://arxiv.org/pdf/2201.05078.pdf
视觉语言预训练模型通过理解图片-文本之间的对齐,在支持多模态应用方面取得了巨大的成功。本文中,作者提出了一个对比学习的框架来增强视觉语言预训练模型对结构性事件信息的理解,并且收集了事件丰富的图文对用于模型的预训练。实验表明,在多模态时间提取方面,作者的CLIP-event预训练模型在Zero-shot和supervised的设定下能够在多模态事件抽取任务上达到SOTA。
3. Are Vision-Language Transformers Learning Multimodal Representations? A Probing Perspective
基于Transformer的视觉语言模型是否学习到多模态表征?一个探索性研究。
论文地址:https://hal.archives-ouvertes.fr/hal-03521715/file/11931.SalinE-7.pdf
近年来,由于基于transformer的视觉语言预训练模型的发展,联合文本-图片的embedding得到明显的改善。作者通过一组文本、图像、多模态探究任务在单模态和多模态层次上比较预训练和微调的表征,并且引入了专门用于多模态探测的新数据集。结果证明了视觉语言预训练在多模态层次上理解了颜色的概念,对位置和大小的理解更依赖文本;在语义对抗的例子上,作者发现多模态预训练模型能够准确地指出细微的多模态差异。同时,作者发现模型在多模态任务(VQA、NLVR)上进行fine-tune不一定能提高其多模态表示能力。
![]()
论文细节
![]()
论文细节

论文动机
使用图像的QA往往只限于从一组预定义的选项中挑选答案,而这样的多选形式被证明是有显示偏见的。Talmor等人(2021)贡献了一个涉及表格、文本和图片推理的抽取式多跳QA数据集;然而每张图片都与维基百科的一个实体相关联,因此对图片的推理基本可以归结为根据问题对图片进行排名并使用排名靠前的图片对应的实体。目前的多模态基准由于在回答问题时并不要求图像-文本grounding使得模型无法解决需要在图片和文本上进行联合推理的问题。因此,作者提出新的QA评估基准任务——多模态多跳QA,并且设计了自动生成silver-standard训练数据的pipeline。
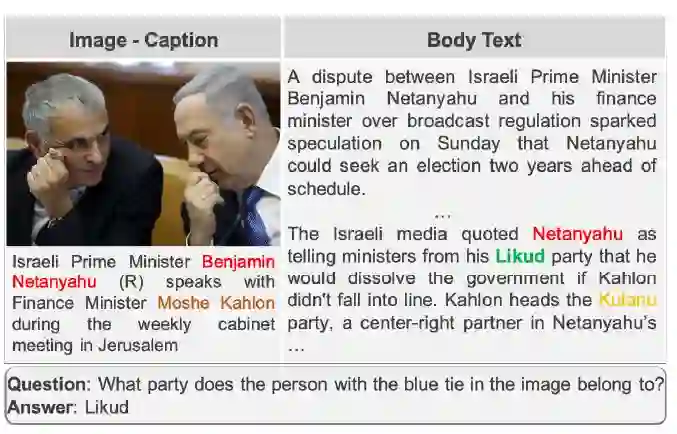
多模态多跳问题回答(MUMUQA)任务介绍
给定带有图像-标题对以及问题的新闻正文,系统需要在正文中找到相应的文本跨度来回答问题。回答问题的过程中,系统需要进行多跳推理:首先进行图片-标题对之间的grounding为与问题中图片相关的部分找到中间答案,称为桥项(bridge item);第二跳是通过中间答案在新闻正文中进行推理,提取文本跨度作为最终答案。例子如下:
Benchmark数据集
Silver-standard训练集生成
训练集的生成流程如下所示:
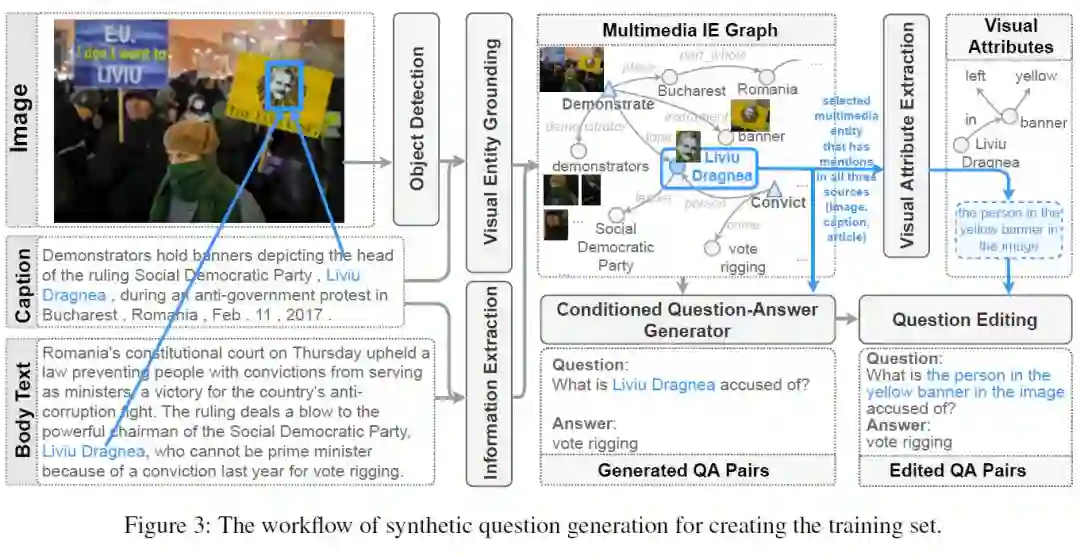
首先通过图片-Caption对之间的Grounding获得图片中Object在Caption中的描述,并对Drounded的图片Object运用视觉属性抽取系统提取相应的视觉属性以便生成对Object的描述。在得到Caption中Grounded的实体之后,先使用SOTA的知识抽取模型对Caption和正文进行相应的实体提交抽取以获得候选的上下文来进行问题-答案对生成。使用带视觉属性的图片Object的描述来替换生成的问题中的Grounded实体对应的文本跨度。最后过滤掉能够被单跳纯文本QA模型回答的数据。
在生成的Silver-standard训练集上,作者随机挑选100条数据进行了人为评估:80%的问题需要使用图片信息,59%有正确的桥项;在正确桥项的情况下,64%的问题拥有正确答案。Grounding以及QA生成的性能会显著影响数据集的质量。
QA模型基准
在文中,作者使用了SOTA的纯文本QA模型、通过OSCAR微调得到的端到端的QA模型以及pipeline-based多模态QA模型在数据集上进行实验。pipeline-based多模态QA模型架构如下:
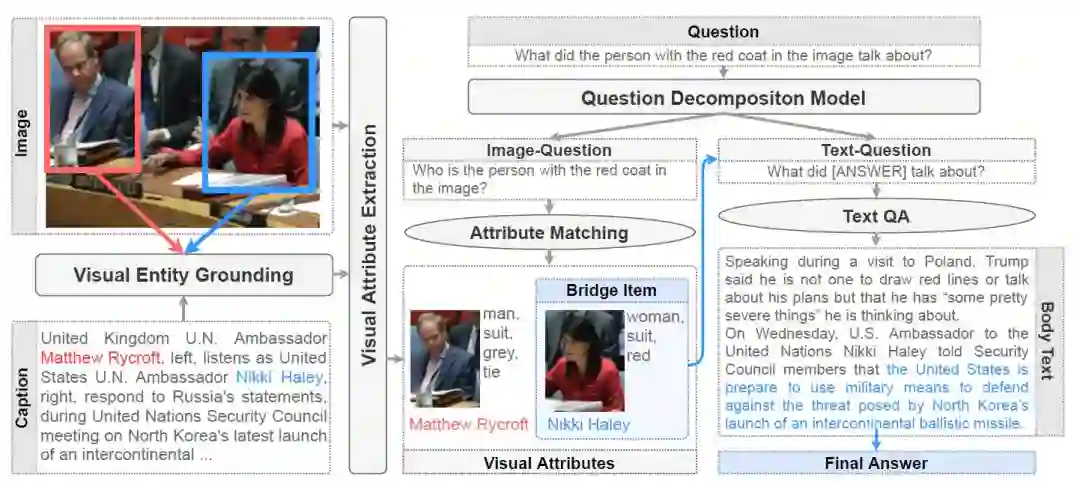
步骤和生成训练集的过程相似,首先进行Image-Caption Grounding得到候选的Entity-Object对,并进行视觉属性提取;对于问题,首先根据问题分解模块对问题进行分解得到图片相关问题以及文本相关问题;将图片相关问题中提及的属性与Grounding结果进行匹配,匹配的Entity作为中间答案与文本相关问题一起进行文本端的QA得到最终答案。
实验结果
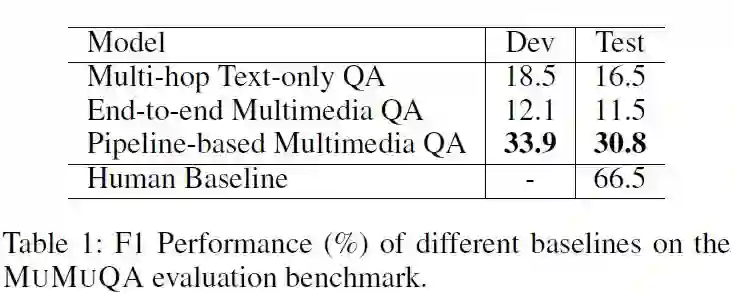
作者对Pipeline-based模型进行了各阶段的分析,发现模型找到正确桥项的 在开发集和测试集上分别为33.5%和29.8%,而人工基线为78.8%;在正确桥项的情况下,系统的 分数为51.1%。

论文动机
现实世界的多媒体应用不仅需要了解Entity的知识,还需要了解事件与事件Argument相关知识。然而目前已有的视觉语言预训练模型侧重对图像或Entity的理解,忽略了事件语义和结构信息,这可能导致模型对动词的理解失败。因此将事件结构知识的学习纳入到视觉语言模型预训练过程进行更多粒度的跨模态信息学习是很有必要的。据此作者设计了一个自监督的对比学习框架CLIP-event,利用标题中丰富的事件知识作为远距离监督来解释图像事件,从而有效地将事件知识进行跨模态迁移。
方法
以下是CLIP-event的架构:
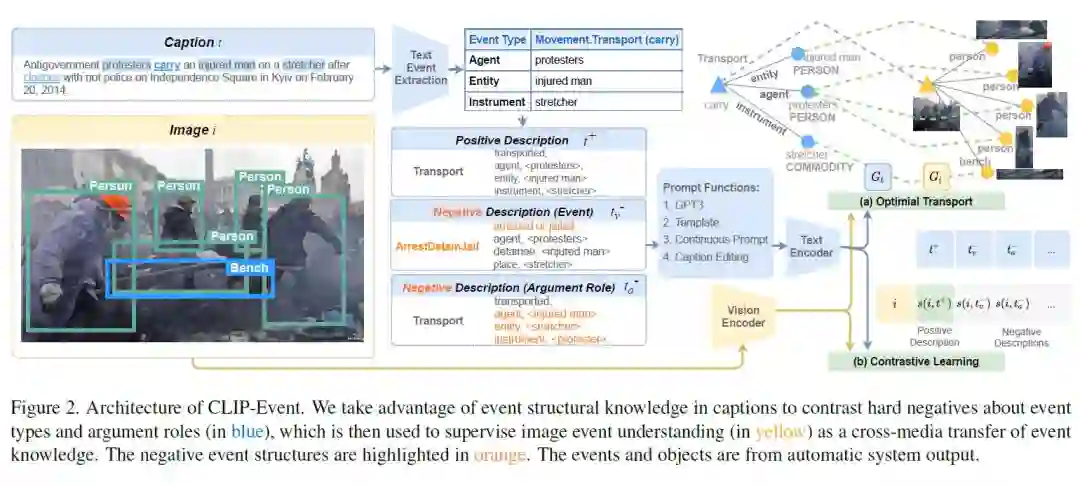
首先,使用Faster R-CNN提取图片中的Objects;对Caption使用SOTA的信息抽取系统提取事件并确定基本事件类型(如果存在多事件,图像更通常地描述了标题的主要事件;选择更接近依赖性解析树、有更多Arguments、更高事件频率以及在CLIP下动词和图片有更高相似度的事件作为基本事件)。然后框架根据提取到的事件类型设计两类Caption负样本(改变事件类别或只改变事件Arg顺序),并根据prompt函数生成结构事件的描述。通过优化图片事件图和正例事件图之间的最优传输距离以及正负样本与图片的相似度来达到多模态信息融合。以下介绍相关细节:
Caption 正负样本生成
负样事件取样:首先计算CLIP在预训练图像-标题数据集上的事件分类器的混淆矩阵(分类器是基于事件类型标签和输入图像i之间的相速度得分,并选择最大的作为预测的事件类别;混淆矩阵通过比较预测的事件类型和图像的主要事件类型而计算的)。然后选择最容易混淆的作为负样本事件类型。
负样本Argument取样:保持事件类型不变,对事件Argument的顺序进行右旋转操作
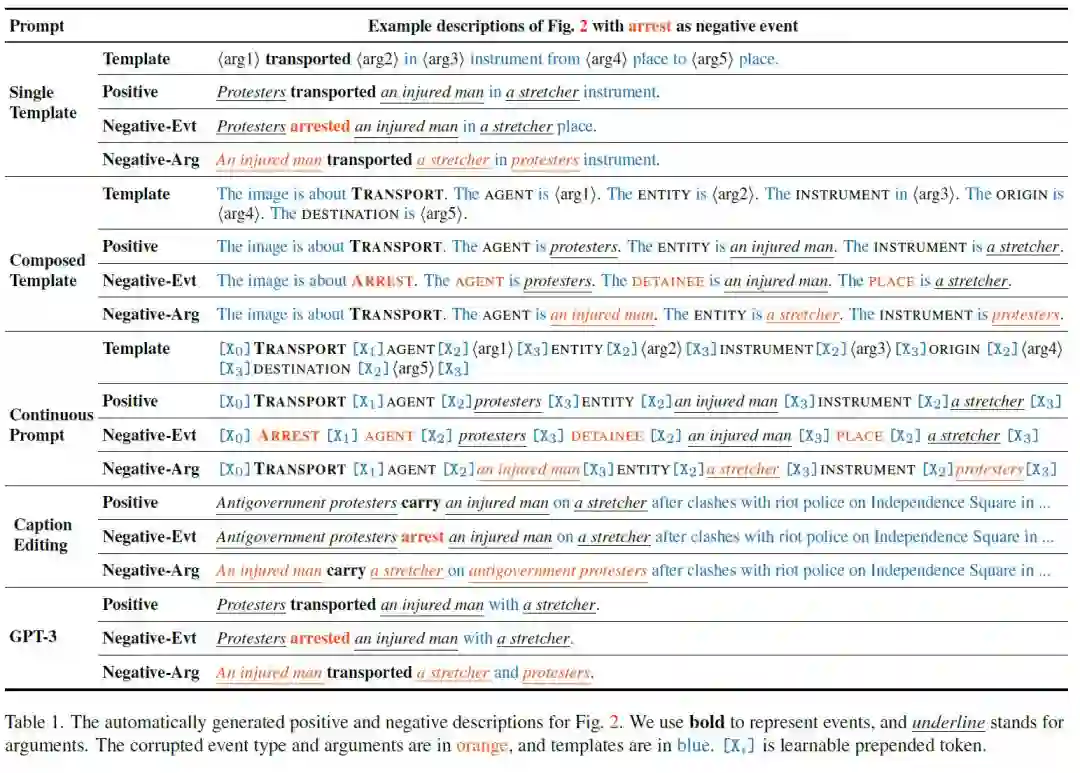
描述生成:为了对提取到的事件结构以及负例事件结构进行encoding,作者设计了多种prompt函数(此处给出生成的例子)
通过Optimal Transport进行事件图对齐
事件及其Arguments可以被组织成以事件节点为根节点,role为边,argument为叶节点的事件图,对齐主要包括三个方面(下图为符号标记解释):

图像级别对齐:计算图片和文本的相似度以及距离(c(.,.) = 1 - cos(.,.))。
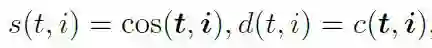
Entity级别对齐:文本Entity与图片object之间余弦距离包含两者的表征相似度以及类别相似度。
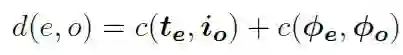
事件级别对齐:为了获得两个图之间的全局对齐分数,作者采用Optimal Transport的方法来获得两个模态事件图之间的最小距离。
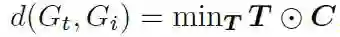
其中C是成本矩阵,事件节点间的成本为:
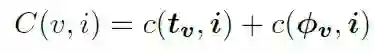
事件Arg节点间的成本为:
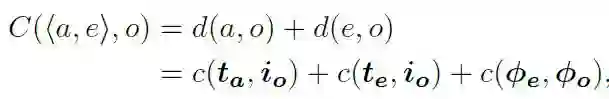
损失函数
(1)优化文本正样本与图片之间的相似性至1,负样本与图片之间相似性至0。
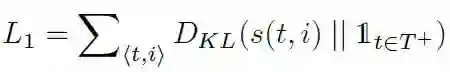
(2)最小化不同模态事件图之间的距离。
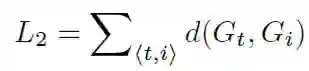
最终损失函数为两者加权。
实验
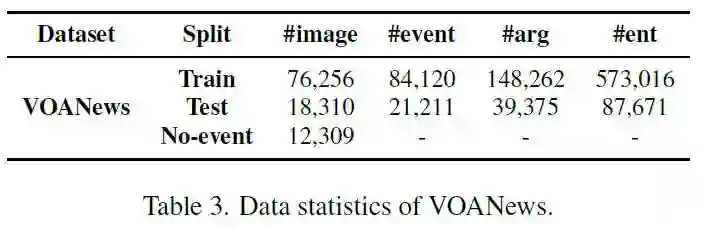
作者使用ViT-B/32的参数作为模型的初始化,在收集的数据集上进行预训练,数据集情况如下:
模型在多模态事件抽取(M2E2)、基础情境识别(GSR)、图片检索(Image Retrieval)等任务上与目前的SOTA模型进行对比评估。
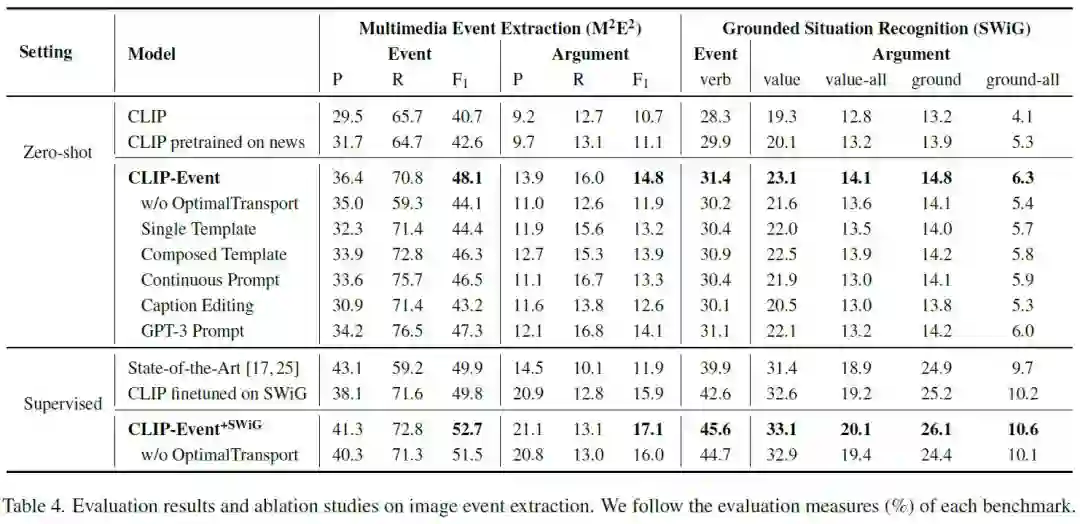
可以看到CLIP-event在Zero-shot和Supervised设定下都取得了SOTA的表现。上图的实验结果也表明在预训练阶段进行事件图对齐有利于模型提取到更好的多模态信息,从而在多模态任务上有更好的表现。

论文动机
视觉语言任务(如视觉问题回答、跨模态检索或生成)非常困难,因为模型需要建立合理的多模态表征将文本和图片的细粒度元素联系起来。在BERT等基于transformer的语言模型成功后,各种基于transformer的多模态预训练模型(如LXMERT、OSCAR、ViTL等)被提出用于得到文本-图片的多模态表征,并且在多模态任务上达到SOTA。但重要的是要了解多模态信息是如何在这些模型学到的表征中编码的,以及它们是如何受到其训练数据的各种bias和属性影响的。Hendricks & Nematzadeh依靠探索任务来研究多模态预训练模型对动词的理解,并确定模型对动词相关的多模态概念的学习少于主语和宾语的学习。在本文中,作者通过特定的一组探索任务来探究VLM的多模态表征能力以及对单模态信息的偏向性。
方法
文章的研究框架如下:
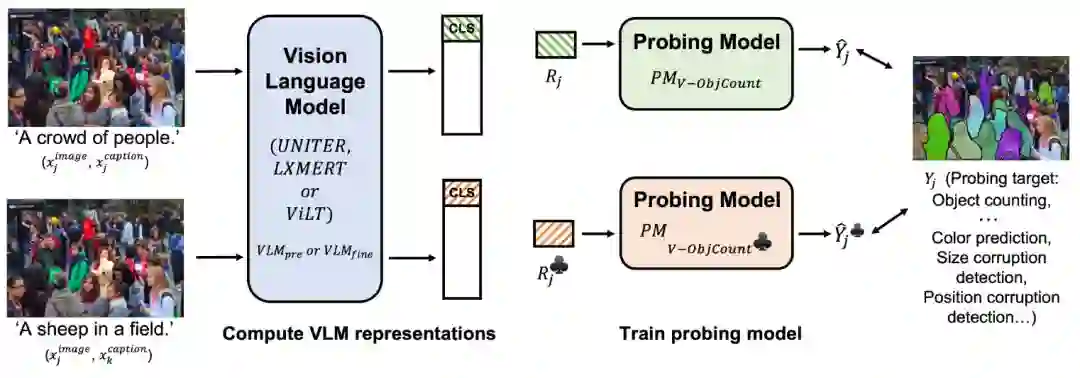
首先将图文匹配和图文不匹配的图文对分别输入到预训练的视觉语言预训练模型 或是fine-tune后的模型 ,得到数据对应的模型最后一层表征;将得到的[CLS]或是WORD级别的token表征 输入到一个未在数据集上训练的线性探测模型 (只能依赖模型在预训练或是fine-tune阶段已经提取到的线性可分离信息)用于反应VLM提取到探索任务p所需信息的能力。
如果p是一个面向语言的任务,其输入数据集为:{(
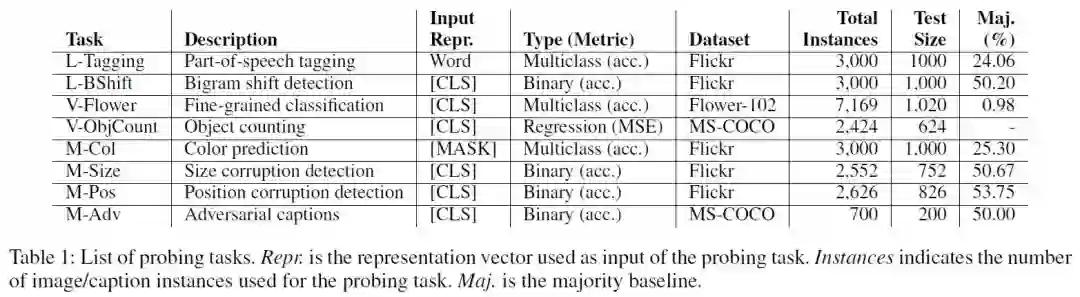
探索任务(Probing Tasks)
探索任务主要分语言、视觉以及多模态三部分进行:语言探索任务包括Part of Speech Tagging(对token进行语义分类,数据集通过en core web sm SpaCy tagger进行构建)、Bigram Shift(确定一个句子中连续的两个词是否被调换);视觉探索任务为Flower identification和Object Counting;在多模态探索任务上,作者主要在描述对象的概念属性方面进行,设计了颜色、大小、位置识别以及Adversarial captions任务并构建了相应的数据集进行评估,以下是“Two men standing behind a tall black fence”在各任务上修改后的caption负例展示。

各探索任务的相关信息如下图所示:
实验设定及结果
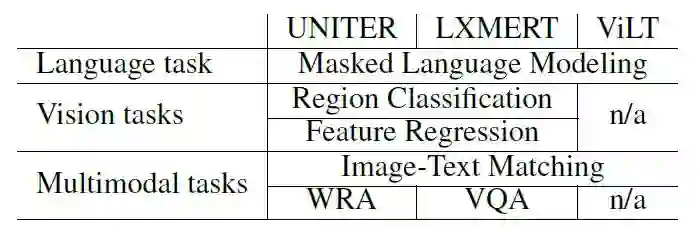
作者选择了三种不同架构且已经预训练好的视觉语言模型:UNITER,LXMERT,ViLT在不同的探索任务上与单模态的SOTA模型进行对比:
Pre-trained 单模态:
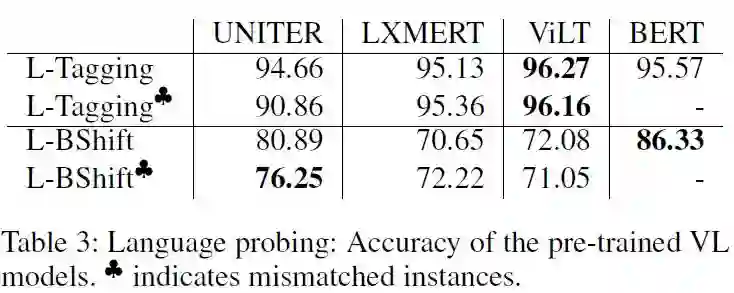
在语言任务上,可以注意到与文本不匹配的图片输入会对UNITER造成负面影响。


在视觉计数任务上(使用RMSE作为评价标准,越小越好),可以发现正确的语言线索可以显著的提高模型的性能。
Pre-trained 多模态:
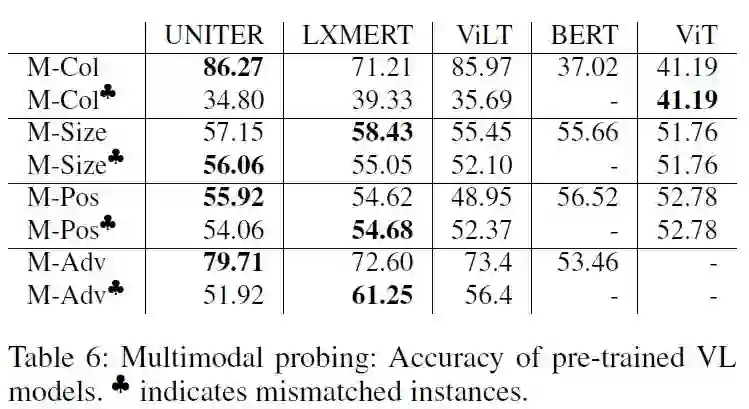
在M-Col和M-Adv任务上,VLM模型达到了比单模态的baseline好得多的性能,多模态信息得到了有效的提取;而在M-Size和M-Pos任务上,VLM的性能并没有得到提升,大小和位置的信息在多模态层次上并没有得到很好的提取。
Fine-tuned单模态:模型经过VQA和NLVR任务上进行fine-tuning后,模型在探索任务上的表现如下。
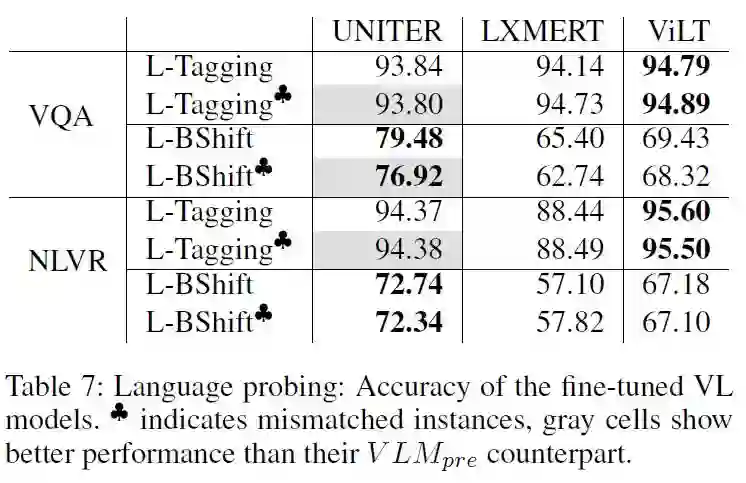
在语言任务上,唯一有提升的是UNITER在负例上的表现,作者将其归结于该模型预训练协议的特殊性。而在NLVR任务上fine-tuned的模型表现出更低的性能可能是因为NLVR任务使用两张图片作为输入,和预训练、探索任务不同;LXMERT经过fine-tuned的性能体现出该模型更容易忘记在预训练阶段学习到的语义知识。

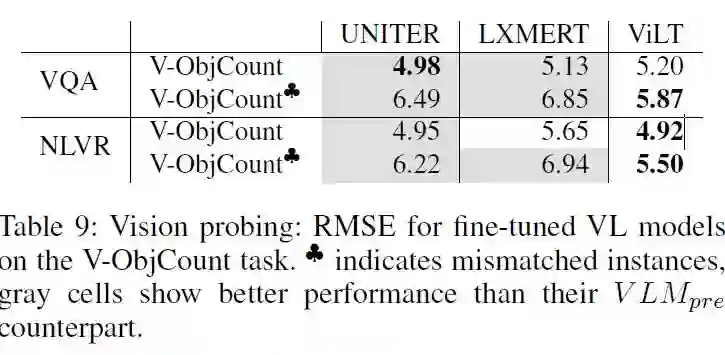
Fine-tuning改善了UMITER和LXMERT的视觉性能。这似乎表明VQA和NLVR依赖视觉信息,而这些信息在预训练模型中不容易获取,同时也表现出两个模型在提取视觉信息上的不足;另一方面Fine-tune并没有提高ViLT提取视觉信息的能力。
Fine-tuned 多模态:
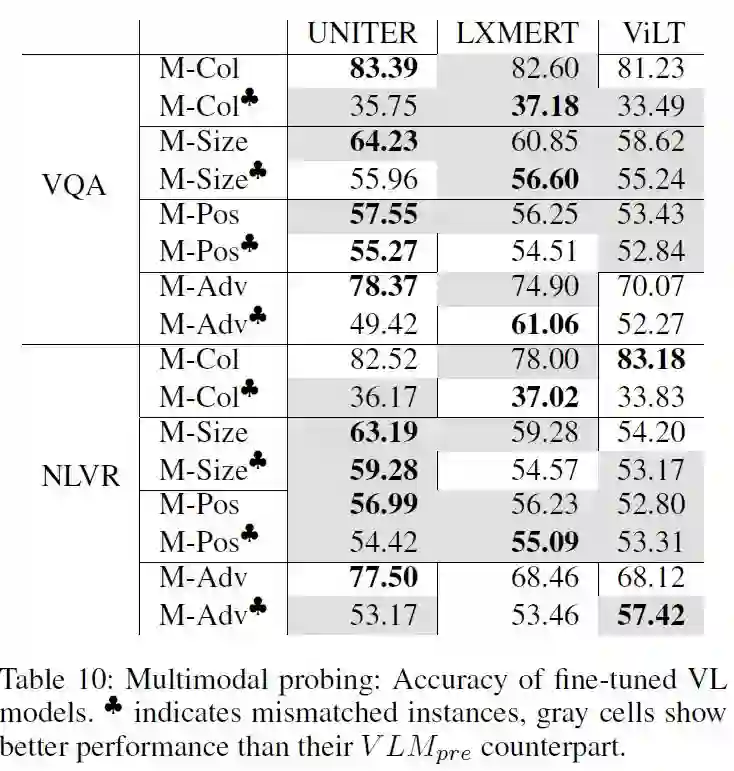
可以发现在M-Size和M-Pos任务上,各模型在fine-tuned后都有了一定的提升,这可能是因为VQA和NLVR任务比预训练更加注重对Size和Position的理解;在M-Col和M-Adv任务上,Fine-tuned的LXMERT模型有了较大的提升。
供稿人:游涛丨本科生四年级丨研究方向:机器学习与跨视觉语言模态丨邮箱:18307110206@fudan.edu.cn



