EMNLP 2022 | 统一指代性表达的生成和理解


简介
指代性表达(Reference Expression,RE)是描述真实场景中一个明确的对象,是人类社会中一种重要的认知行为。人们在日常生活中为一个对象构想一个 RE,并根据一个 RE 来识别一个所指对象,它们分别被命名为指代性表达生成和理解。由于其广阔的研究前景和实际应用,这两项任务引起了自然语言处理、计算机视觉和人机交互领域的广泛兴趣。
指代性表达的生成(REG)和理解(REC)就像同一枚硬币的两侧一样相互依赖。例如,在构思明确的描述之前,人们需要根据脑海中的描述来正确定位对象。但是,之前的研究很少关注解决指代性表达生成和理解的统一建模问题,目前也还没有针对指代性表达生成和理解的统一建模的图像文本预训练研究。
北京邮电大学、字节跳动人工智能实验室以及苏州大学的研究者提出了一个统一的 REG 和 REC 模型(UniRef)。它将这两个任务通过精心设计的图像-区域-文本融合层(Image-Region-Text Fusion layer,IRTF)统一起来,图像-区域-文本融合层通过图像互注意力与区域互注意力来融合图像、区域与文本信息。此外,它可以为 REC 任务生成伪区域输入,以便以统一的方式在 REC 和 REG 之间共享相同的表示空间。
本工作的研究员在三个基准数据集 RefCOCO、RefCOCO+ 和 RefCOCOg 上进行了广泛的实验。实验结果表明,所提出的模型在 REG 和 REC 上都优于以前最先进的方法。

论文地址:

算法介绍
模型由一个视觉编码器、一个语言编码器和一个融合编码器以及两个任务相关的预测头组成。
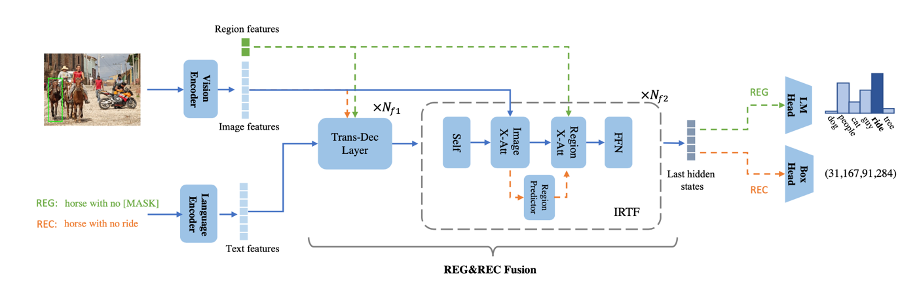
2.1 融合编码器
融合编码器通过用图像-区域-文本融合层替换最后的 个 vanilla Transformer 解码器层来扩展 Transformer 解码器,这些层旨在弥合指代性表达生成和理解之间的差距。其中图像-区域-文本融合层通过添加图像互注意力和区域互注意力扩展了 vanilla Transformer 编码器层,并将图像信息和区域信息与查询进行融合。给定输入,首先应用自注意力来获得查询,然后依次执行图像互注意力和区域互注意力,最后被馈送到前馈网络以获得输出隐藏状态。
执行指代性表达理解时没有区域输入,为了使指代性表达理解的输入与指代性表达生成相同,区域预测器用于生成区域预测来作为图像互注意力的输入。
2.2 预训练目标
为了学习语言建模和视觉定位的能力,该工作的预训练阶段有两个目标,分别对应于指代性表达生成和理解的视觉条件掩蔽语言建模和文本条件区域预测。
1. 视觉条件掩蔽语言建模(Vision-conditioned Masked Language Modeling,VMLM)。给定一个图像-区域-文本三元组,首先屏蔽文本序列中 25% 的标记。该任务旨在根据可见文本、区域和图像来预测看不见的标记。值得注意的是,视觉条件掩蔽语言建模类似于指代性表达生成,但解码顺序和注意掩码有所不同。
2. 文本条件区域预测(Text-Conditioned Region Prediction,TRP)。给定一个图像-文本对,文本条件区域预测的目标是预测文本描述的区域或对象的边界框。损失是广义交并集和距离的总和。在文本条件区域预测中,每个图像-区域-文本融合层都会产生一个区域预测作为区域互注意力的输入,监督信号来自预测和真实标注之间的图像块级二进制交叉熵。这两个损失一起用于训练文本条件区域预测。

实验结果
该研究工作在三个基准数据集 RefCOCO、RefCOCO+ 和 RefCOCOg 进行了广泛的实验。实验结果表明所提出的模型在指代性表达生成和理解上都优于以前最先进的方法。
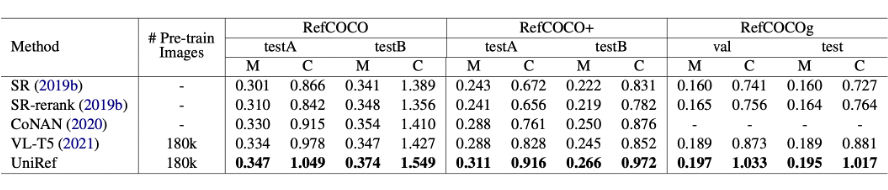
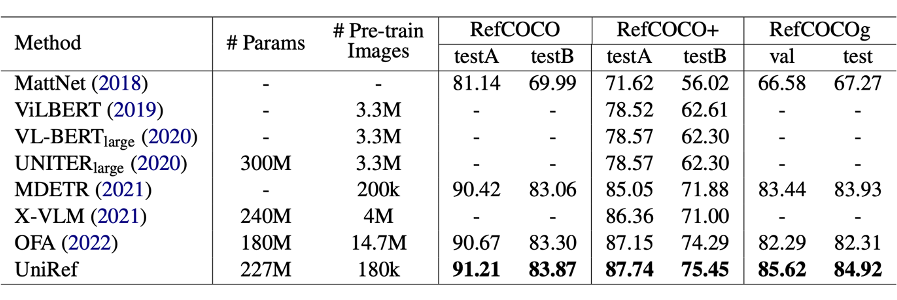
▲ 指代性表达生成和理解的结果
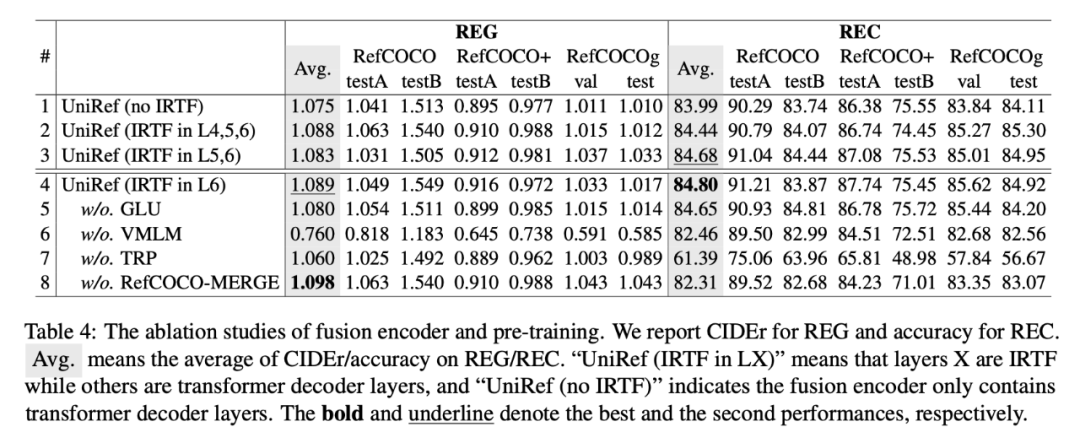
▲ 消融实验结果
消融实验结果如上表所示,可以发现,ITRF 可以提升 REG 和 REC 的性能;在第 6 层中使用 IRTF 优于其他同行;VMLM 和 TRP 使预训练受益;域内数据的预训练显着提高了 REC 的性能,但略微损害了 REG 的性能。
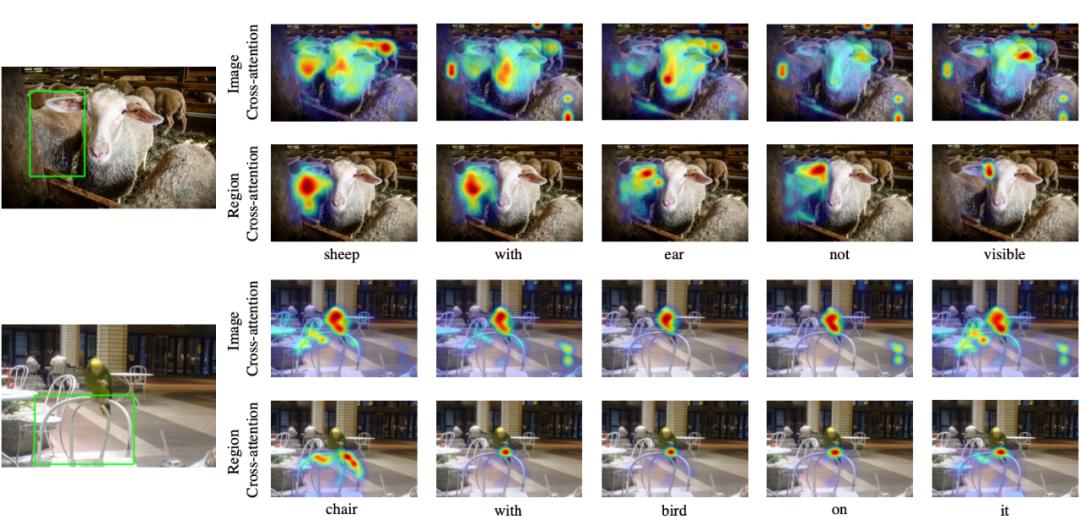
上图可视化了 UniRef 如何利用 REG 中的图像和区域信息。在自回归生成过程中对互注意力图进行可视化,包括图像互注意和区域互注意,通过观察案例发现了两个现象:
1)图像互注意可以关注图像中与目标对象无法区分的其他对象,从而帮助模型生成更具区分性的描述。例如,在第一个实例中,羊的耳朵由图像互注意处理,而耳朵不可见的羊由区域互注意处理,导致描述为“耳朵不可见的羊”。
2)通过关注与目标对象相关的对象,模型可以生成具有关系的描述,例如空间关系。在第二个例子中,模型通过它与不在绿框中的鸟之间的空间关系,明确地描述了绿框中的椅子。

上图可视化了 UniRef 在 REC 中学习的能力,并给出了边界框预测的示例。UniRef 能够处理具有各种属性的描述,例如比较关系(a)、属性识别(b、c)、空间关系(j、k)和计数(d-f)。
但是 REC 中仍然存在挑战。通过分析不良案例,可以总结出所提出的模型面临的一些困难:1)短路径。该模型正确地定位了植物(m),但未能定位到花盆(n)。它首先定位墙上的花朵,然后将这面墙视为花盆。说明模型并没有真正理解什么是花盆,而是通过花来学习短路径;2)小物件。可以发现该模型对于小物体识别不是很好(i、r)。

参考文献
[1] Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A. L., & Murphy, K. 2016. Generation and comprehension of unambiguous object descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition.
[2] Yan Zeng, Xinsong Zhang, and Hang Li. 2021. Multi-grained vision language pre-training: Aligning texts with visual concepts. In Proceedings of the International Conference on Machine Learning.
[3] Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. 2018. Mattnet: Modular attention network for referring expression comprehension. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
[4] Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, and Nicolas Carion. 2021. Mdetr–modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE conference on international conference on computer vision.
[5] Jaemin Cho, Jie Lei, Hao Tan, and Mohit Bansal. 2021. Unifying vision-and-language tasks via text generation. 2021. In Proceedings of the International Conference on Machine Learning.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」


