学界 | 最大化互信息来学习深度表示,Bengio等提出Deep INFOMAX
选自arXiv
作者:R Devon Hjelm、Bengio等
机器之心编译
参与:高璇、刘晓坤
许多表示学习算法使用像素级的训练目标,当只有一小部分信号在语义层面上起作用时是不利的。在这篇论文中,Bengio 等研究者假设应该更直接地根据信息内容和统计或架构约束来学习表示,据此提出了 Deep INFOMAX(DIM)。该方法可用于学习期望特征的表示,并且在分类任务上优于许多流行的无监督学习方法。他们认为,这是学习「好的」和更条理的表示的一个重要方向,有利于未来的人工智能研究。
引言
在意识层面上,智能体并不在像素和其他传感器的层面上进行预测和规划,而是在抽象层面上进行预测。因为语义相关的比特数量(在语音中,例如音素、说话者的身份、韵律等)只是原始信号中总比特数的一小部分,所以这样可能更合适。
然而,大多数无监督机器学习(至少是部分地)基于定义在输入空间中的训练目标。由于无需捕获少数语义相关的比特,就可以很好地优化这些目标,因此它们可能不会产生好的表示。深度学习的核心目标之一是发现「好的」表示,所以我们会问:是否有可能学习输入空间中未定义的训练目标的表示呢?本文探讨的简单想法是训练表示学习函数(即编码器)以最大化其输入和输出之间的互信息。
互信息是出了名的难计算,特别是在连续和高维设置中。幸运的是,在神经估计的最新进展中,已经能够有效计算深度神经网络的高维输入/输出对之间的互信息。而在本项研究中,研究人员利用这些技术进行表示学习。然而,最大化完全输入与其表示之间的互信息(即全局互信息)不足以学习有用的表示,这依赖于下游任务。相反,最大化输入的表示和局部区域之间的平均互信息可以极大地改善例如分类任务的表示质量,而全局互信息在给定表示的重建完整输入上能发挥更大的作用。
表示的作用不仅仅体现在信息内容的问题上,架构等表示特征也非常重要。因此,研究者以类似于对抗性自编码器或 BiGAN 的方式将互信息最大化与先验匹配相结合,以获得具有期望约束的表示,以及良好的下游任务表现。该方法接近 INFOMAX 优化原则,因此研究者们将他们的方法称为深度 INFOMAX(DIM)。
本研究贡献如下:
规范化的深度 INFOMAX(DIM),它使用互信息神经估计(MINE)来明确地最大化输入数据和学习的高级表示之间的互信息。
互信息最大化可以优先考虑全局或局部一致的信息,这些信息可以用于调整学习表示的适用性,以进行分类或风格重建的任务。
研究者使用对抗学习来约束「具有特定于先验的期望统计特征」的表示。
引入了两种新的表示质量的度量,一种基于 MINE,另一种是 Brakel&Bengio 研究的的依赖度量,研究者用它们来比较不同无监督方法的表示。
论文:Learning deep representations by mutual information estimation and maximization

论文地址:https://arxiv.org/abs/1808.06670v2
摘要:许多流行的表示学习算法使用在观察数据空间上定义的训练目标,我们称之为像素级。当只有一小部分信号在语义层面上起作用时,这可能是不利的。我们假设应该更直接地根据信息内容和统计或架构约束来学习和估计表示。为了解决第一个质量问题,研究者考虑通过最大化部分或全部输入与高级特征向量之间的互信息来学习无监督表示。为了解决第二个问题,他们通过对抗地匹配先验来控制表示特征。他们称之为 Deep INFOMAX(DIM)的方法可用于学习期望特征的表示,并且在分类任务按经验结果优于许多流行的无监督学习方法。DIM 开辟了无人监督学习表示的新途径,是面向特定最终目标而灵活制定表征学习目标的重要一步。
实验
我们使用以下指标来评估表示。下面编码器都固定不变,除非另有说明:
使用支持向量机(SVM)进行线性分类。它同时代表具有线性可分性的表示的互信息。
使用有 dropout 的单个隐藏层神经网络(200 个单元)进行非线性分类。这同样代表表示的互信息,其中标签与线性可分性分开,如上面的 SVM 所测的。
半监督学习,即通过在最后一个卷积层(有标准分类器的匹配架构)上添加一个小型神经网络来微调整个编码器,以进一步评估半监督任务(STL-10)。
MS-SSIM,使用在 L2 重建损失上训练的解码器。这代表输入和表示之间的全部互信息,并且可以表明编码的像素级信息的数量。
通过训练参数为ρ的判别器来最大化 KL 散度的 DV 表示,来表示输入 X 和输出表示 Y 之间的互信息神经估计(MINE),I_ρ(X,Y)。
神经依赖度量(NDM)使用第二判别器来度量 Y 和分批再组(batch-wise shuffled)的 Y 之间的 KL 散度,使得不同的维度相互独立。
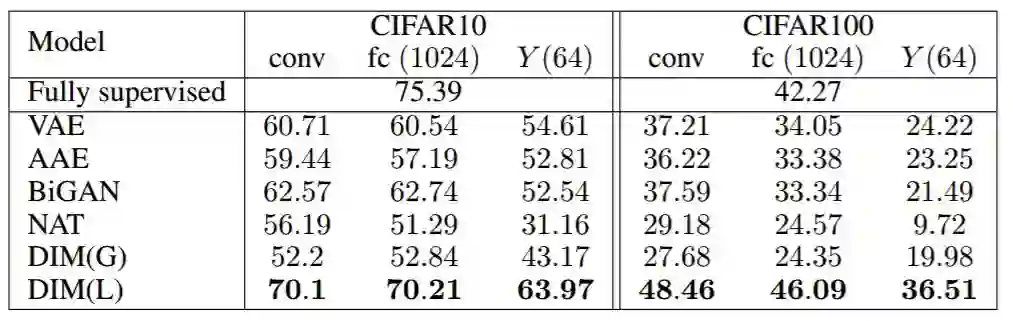
表 1:CIFAR10 和 CIFAR100 的分类准确率(top-1)结果。DIM(L)(仅局部目标)显著优于之前提出的所有其他无监督方法。此外,DIM(L)接近甚至超过具有类似架构的全监督分类器。具有全局目标的 DIM 表现与任务中的某些模型相似,但不如 CIFAR100 上的生成模型和 DIM(L)。表中提供全监督分类结果用于比较。
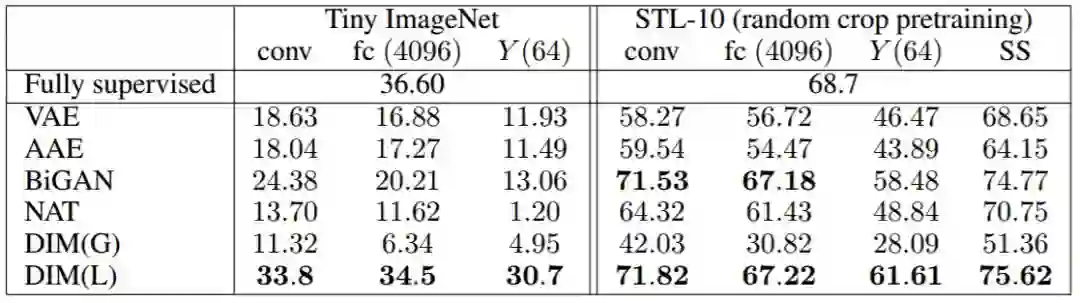
表 2:Tiny ImageNet 和 STL-10 的分类准确率(top-1)结果。对于 Tiny ImageNet,具有局部目标的 DIM 优于所有其他模型,并且接近全监督分类器的准确率,与此处使用的 AlexNet 架构类似。

图 5:使用 DIM(G)和 DIM(L)在编码的 Tiny ImageNet 图像上使用 L1 距离的最近邻。最左边的图像是来自训练集的随机选择的参考图像(查询)以及在表示中测量的来自测试集的最近邻的四个图像,按照接近度排序。来自 DIM(L)的最近邻比具有纯粹全局目标的近邻更容易理解。
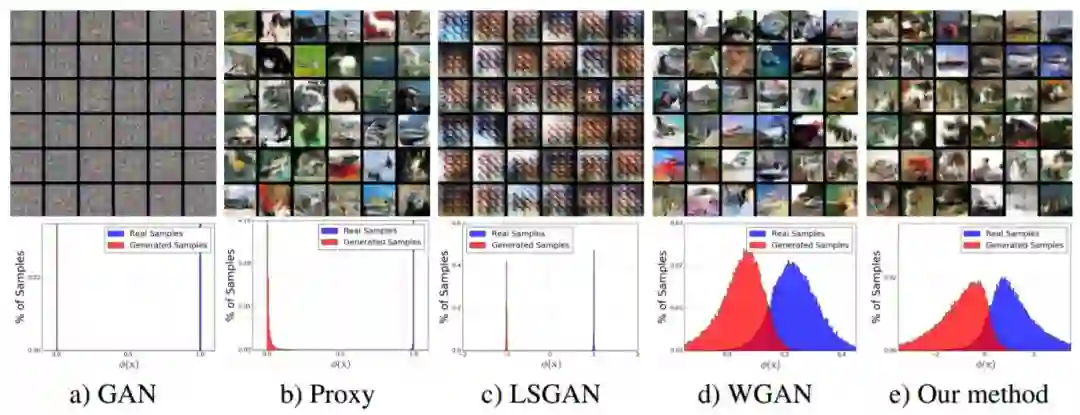
图 7:描绘判别器非归一化输出分布的直方图,分别是标准 GAN、具有-log D 损失的 GAN、最小二乘 GAN、Wasserstein GAN 以及作者提出的以 50:1 训练率训练的方法。
方法:深度 INFOMAX
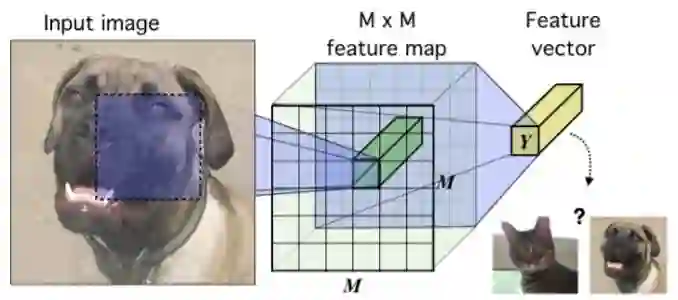
图 1:图像数据上下文中的基本编码器模型。将图像(在这种情况下)编码到卷积网络中,直到有一个 M×M 特征向量的特征图与 M×M 个输入块对应。将这些矢量(例如使用额外的卷积和全连接层)归一化到单个特征向量 Y。目标是训练此网络,以便从高级特征中提取有关输入的相关信息。
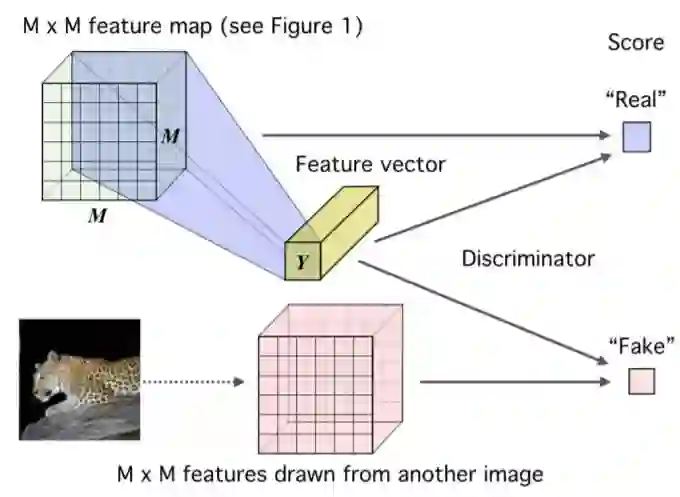
图 2:具有全局 MI(X; Y)目标的深度 INFOMAX(DIM)。研究者通过由额外的卷积层、flattening 层和全连接层组成的判别器来传递高级特征向量 Y 和低级 M×M 特征图(参见图 1)以获得分数。通过将相同的特征向量与来自另一图像的 M×M 特征图结合来绘制伪样本。
结论
在这项研究中,研究者们介绍了 Deep INFOMAX(DIM),这是一种通过最大化互信息来学习无监督表示的新方法。DIM 允许在架构「位置」(如图像中的块)中包含局部一致信息的表示。这提供了一种直接且灵活的方式来学习在各种任务上有优良表现的表示。他们认为,这是学习「好的」和更条理的表示的一个重要方向,这将利于未来的人工智能研究。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



