
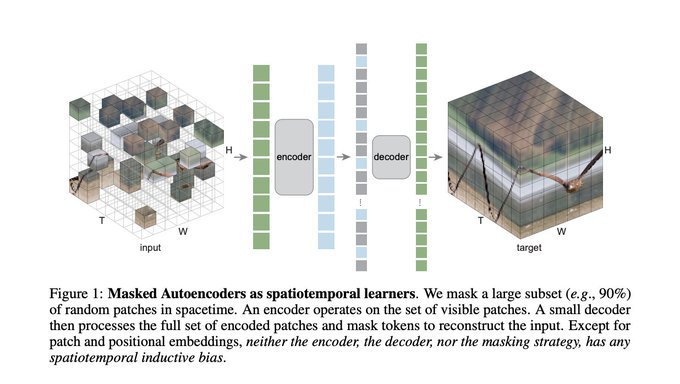
本文研究了一种概念简单的掩码自编码器(MAE)扩展到视频的时空表示学习。我们随机屏蔽视频中的时空块,并学习自动编码器以像素重建它们。有趣的是,我们的MAE方法可以在几乎没有时空诱导偏差的情况下学习强表示(只有补丁和位置嵌入除外),而时空无关的随机掩蔽性能最好。我们观察到最优掩蔽比高达90%(图像上为75%),支持了该比例与数据信息冗余有关的假设。高掩蔽比导致大的加速,例如,在挂钟时间> 4x甚至更多。我们使用vanilla 视觉Transformers报告了几个具有挑战性的视频数据集的实验结果。我们观察到,MAE可以大大超过监督预训练的表现。我们进一步报告了在真实世界、未经整理的Instagram数据上训练的令人鼓舞的结果。我们的研究表明,掩码自编码的一般框架(BERT、MAE等)可以成为一个统一的方法,以最小的领域知识进行表示学习。
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯
相关论文