MAE同期工作!MSRA新作SimMIM收录CVPR 2022!高达87.1%准确率!掩码图像建模新框架
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:机智勇敢萌刚刚 | 已授权转载(源:知乎)编辑:CVer
https://zhuanlan.zhihu.com/p/435389007
前言
Amusi 注意到去年11月份何恺明一作的MAE收录到CVPR 2022 Oral!详见:何恺明一作MAE收录CVPR 2022 Oral!高达87.8%准确率!自监督领域新代表作,也刚刚注意到:同年11月份MSRA的SimMIM工作也成功收录到了CVPR 2022。目前MIM 方向越来越火热,大家可以关注一波。
概要
本文提出一个用于掩码图像建模(masked image modeling)的简单框架SmiMIM。作者简化了最近提出的方法,而无需任何特殊设计,如利用离散VAE或聚类进行块级别的掩码和分词。为了让掩码图像建模任务能学到更好的表示,作者表示该框架中每个组件的简单设计已经能显示出其优异的学习能力:
采用中等大小的掩码块(如32),对输入图像进行随机掩码,能使之成为强大的代理任务(pretext task)
直接回归预测原始像素RGB值的效果并不比复杂设计的patch分类方法差
预测头可以像线性层一样轻量,性能并不一定比多层的差
使用ViT-B,通过对该数据集进行预训练,该方法在ImageNet-1K上实现了83.8%的top-1微调精度,比之前的最佳方法高出0.6%。将其应用在约6.5亿个参数的更大模型时,SwinV2-H仅使用ImageNet-1K数据可以达到87.1%的top-1精度。作者还利用这种方法来加速3B模型(SwinV2-G)的训练,通过比以前少40倍的数据,在四个具有代表性的视觉基线数据集上达到了SOTA。
>1.论文和代码地址

论文题目:SimMIM: A Simple Framework for Masked Image Modeling
发表单位:微软亚洲研究院
论文:arxiv.org/abs/2111.09886
代码地址(已开源):
https://github.com/microsoft/SimMIM
提交时间:2021年11月18日
>2.动机
“What I cannot create, I do not understand.” — Richard Feynman
全文从诺贝尔物理学奖得主理查德·费曼(Richard Feynman)的经典名言展开,介绍掩码信号建模任务是一种具有创造性的学习任务,即遮住输入图像的一部分并尝试预测遮住的信号。
在NLP中,遵循这一理念,建立在掩码语言建模任务上的自监督学习方法在很大程度上重塑了这一领域,即通过使用巨大的无标签数据来学习非常大规模的语言模型,并被证明可以广泛推广到NLP应用中。而在计算机视觉中,虽然有先驱者利用这一理念进行自监督表示学习,但在发展初期,这方面的工作几乎被对比学习的方法遮挡锋芒。
根据语言和视觉领域的特性,在二者上导致明显差异的原因,作者分析出以下三点:
图像具有更强的局部关系,即相互靠近的像素往往是高度相关的。复制靠近的像素可以很好地完成任务,显然通过语义推理并不容易办到。
视觉信号是原始的、低层次的,而文本分词是由人类产生的高级概念。那么,对低层次信号的预测是否对高层次的视觉识别任务有用?
视觉信号是连续的,而文本分词是离散的。那么,如何利用基于分类的掩码语言建模方法处理连续的视觉信号?
一些近期的工作通过引入特殊的设计尝试弥补模态间的鸿沟,解决该难题,这些工作在很多视觉识别任务上展现了出色的迁移能力。
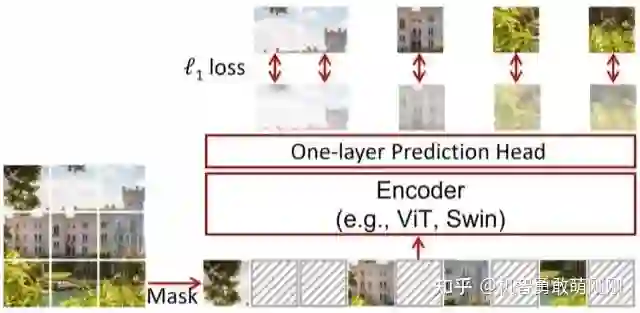
本文丢弃那些额外的特殊设计,提出一个符合视觉信号特点的简单框架SimMIM,与之相比,SimMIM能学到类似甚至更好的表示。SimMIM框架如图1所示,核心设计如下:
将随机掩码应用到图像块(patch)中方便了vision Transformer(ViT)的应用。对于掩码块的像素点而言,更大的patch大小或掩码的更多都可能更难找到附近的可见像素来预测自己。对于掩码大小为32的块(相对的大块)而言,该方法可以在较宽的掩码率范围内(10%-70%)实现极具竞争力的性能。对于掩码大小为8的块(相对的小块)而言,需要高达80%的掩码率才能表现的比较好。这里需要注意,在图像中预设的掩码率与在文本中的有很大的不同,在语言域中,默认掩码率为0.15。作者猜测这种差异来自于两种模态信息冗余的程度不同。
使用原始像素回归任务。回归任务与具有有序性的视觉信号的连续性很好地吻合。这个简单的任务执行起来并不比使用由分词、聚类或离散化专门定义的分类方法差。
采用极轻量的预测头(如线性层),其迁移性能与较繁琐的预测头(如 inverse Swin-B)相似或略好。使用轻量级的预测头在预训练中带来了显著的加速。此外,作者注意到在广阔范围内(例如 12^2-96^2)的目标分辨率与最高到 192^2 的分辨率具有竞争力。虽然较大的头或更高的分辨率通常会导致更强的生成能力,但这种更强的能力不一定有利于下游的微调任务。
虽然简单,但提出的SimMIM方法是非常有效地用于表示学习。ViT-B在ImageNet1K上预训练并在该数据集上实现了83.8%的top-1微调精度,比之前的最佳方法的高出了0.6%。SimMIM还被证明可以扩展到更大的模型:SwinV2-H模型(658M参数)在ImageNet-1K分类上达到87.1%的top-1准确率,这是仅使用ImageNet-1K数据的方法中最好的表现。这一结果鼓励了自监督学习的使用,以解决由于模型容量快速增长而引起的日益严重的数据不足的问题。在SimMIM的帮助下,作者使用比谷歌的JFT-3B数据集小约40×的数据成功训练了一个具有30亿个参数的SwinV2-G模型,并在几个有代表性的基线测试中创造了新的记录:ImageNet-V2分类上的top-1准确率为84.0%,COCO目标检测上达到63.1/54.4 box/mask mAP,ADE20K语义分割上达到59.9 mIoU,Kinetics-400动作识别上的top-1准确率为86.8%。
>3.方法
3.1 整体架构
SimMIM方法通过掩码图像建模来学习表示,该方法对输入图像信号的一部分进行掩码,并预测在掩码区域的原始信号。该框架由4个主要组件组成:
Masking strategy. 给定一张输入图像,该组件负责选择掩码的区域及实现所选区域的掩码。经过掩码后的图像将用作模型输入。
Encoder architecture. 编码器提取掩码图像上潜在的特征表示,然后用来预测掩码区域的原始信号。经过学习的编码器可用于不同的视觉任务。在本文中,主要考虑两种典型的vision Transformer架构: vanilla ViT和Swin Transformer。
Prediction head. 预测头用于潜在的特征表示,表示掩码区域中的原始信号。
Prediction target. 这个组件定义了要预测的原始信号的形式。它可以是原始像素值,也可以是原始像素的变换。另外,定义了损失类型,包括交叉熵分类损失和l1或l2回归损失。
3.2 掩码策略-掩码区域的选择
作者使用可学习的mask token vector代替每个掩码区域,这个token向量维度与其他可见patch经过patch embedding后的维数相同。

Patch对齐的随机掩码策略。 对于Swin Transformer,考虑相同的不同分辨率的补丁大小(4×4 ~ 32×32),默认采用32×32的补丁大小。对于ViT,采用32×32作为默认掩码补丁大小。
其他掩码策略。
①中心区域掩码策略,让其在图像上随机移动;
②块级掩码策略,利用分别为16x16和32x32的两种掩码块进行掩码。
3.3 预测头
预测头的形式和大小可以是任意的,只要其输入与编码器输出一致,其输出达到预测目标即可。一些早期的工作跟随自编码器使用一个繁琐的预测头(解码器)。在这篇文章中,作者证明了预测头可以做得非常轻,就像线性层一样轻量。作者还尝试较重的头部,如2层MLP、inverse Swin-T,inverse Swin-B.
3.4 预测目标
原始像素值回归。
像素值在颜色空间中是连续的。一个直接的想法是通过回归来预测掩码区域的原始像素。一般来说,视觉架构通常生成下采样分辨率的特征图,例如,ViT为16×,其他架构为32×。
为了预测输入图像的全分辨率下的所有像素值,(1)作者将feature map中的每个特征向量映射回原始分辨率,并让该向量负责相应的原始像素的预测。
例如,对于Swin Transformer编码器生成的32×下采样的feature map,作者使用输出维数为3072 = 32×32×3的1×1卷积(线性)层来表示32×32像素的RGB值。对原始图像分别进行{32×, 16×, 8×, 4×, 2×}下采样,考虑分辨率较低的目标。
(2)在掩码像素上使用L1-loss. 在实验中还考虑了L2和smooth-L1损失效果与之类似,默认采用L1损失。

其他预测目标。
①Color clustering. 在iGPT中,利用大量自然图像,通过k-means将RGB值分成512个簇。然后每个像素被分配到最近的簇中心。这种方法需要一个额外的聚类步骤来生成9位调色板。在实验中,作者使用了在iGPT中学习到的512簇中心。
②Vision tokenization. 在BEiT中,采用离散VAE (dVAE)网络将图像patch转换为dVAE tokens。token可用作为分类目标。在这种方法中,需要预训练一个额外的dVAE网络。
③Channel-wise bin color discretization. 将R、G、B通道分别进行分类,每个通道离散为相同的bins,例如实验中使用的8和256 bins。
>4.实验结果
4.1 实验设置
作者采用Swin-B作为消融研究的默认骨干。为了减少实验开销,默认的输入图像大小为192×192,并将窗口大小调整为6以适应改变的输入图像大小。ImageNet-1K图像分类数据集用于预训练和微调。采用数据增强:随机调整大小裁剪,比例范围为[0.67,1],宽高比范围为[3/ 4,4 /3],然后进行随机翻转和颜色归一化步骤。SimMIM组件的默认选项是:一个随机掩码策略,补丁大小为32×32,掩码率为0.6;目标图像大小为192×192的线性预测头;掩码像素预测的L1损失。
4.2 掩码策略
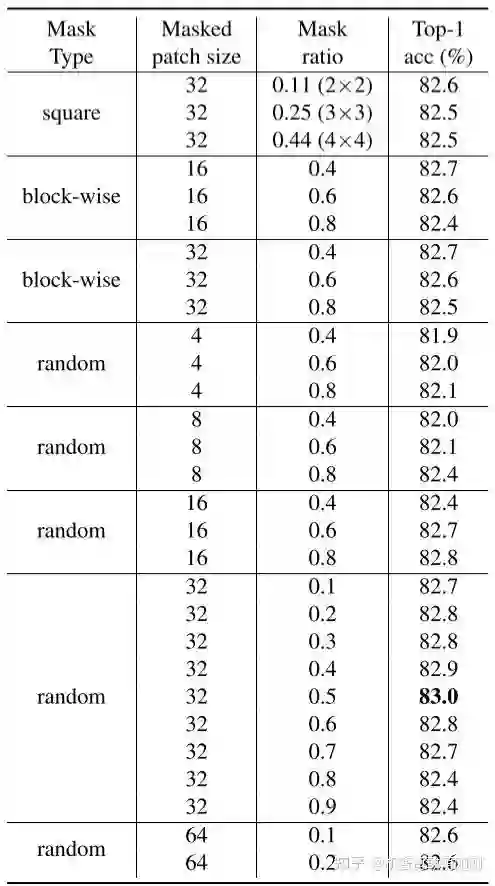
由表1可知,不同掩码策略在不同掩码率的微调精度不同。<结论①>其中简单随机掩码策略最佳精度达到83.0%,比其他更特别的策略的最佳精度高0.3%。<结论②>当采用较大的掩码块(大小为32)时,这种简单的策略在较宽的掩码率范围(10%-70%)上表现稳定。假设一个大遮罩块的中心像素距离可见像素足够远。因此,即使使用了较低的掩码率(如10%)或没有掩码周围的所有补丁,它也会迫使网络学习相对较长的连接。另一种增加预测距离的方法是<结论③>使用更大的掩码率,这也证明了相对较小的patch尺寸有利于微调性能。然而,这些较小的patch的总体精度不如较大的patch(32)的高。进一步将patch大小增加到64的观测精度下降,可能是由于预测距离太大。
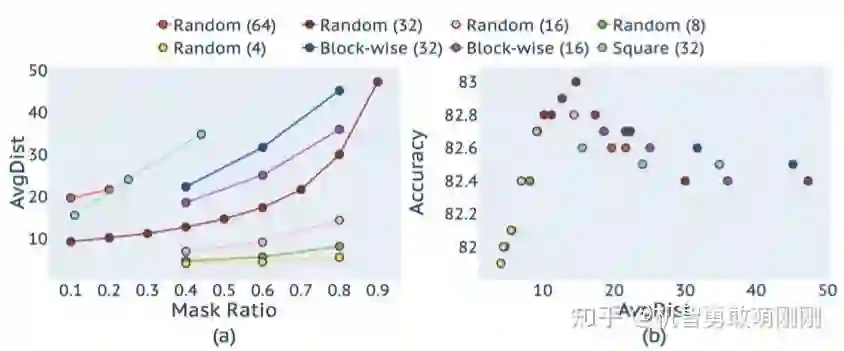
上述观察和分析也可以很好地反映在一个新提出的AvgDist度量,该度量测量掩码像素到最近的可见像素的平均欧氏距离。不同掩码策略与不同掩蔽率的AvgDist如图3(a)所示。从图中可以看出,所有掩码策略的AvgDist都随着掩蔽率的增大而平滑增大。对于随机掩码策略,当补丁大小较小(如4或8)时, AvgDist相对较低,且随着掩码率的增加而增长缓慢。另一方面,当补丁尺寸较大时(如64),很小的掩码率(如10%)仍然会产生较大的AvgDist。中心掩码和块掩码方法产生的AvgDist值与补丁大小为64的同样高。
图3(b)绘制了微调精度和AvgDist测量之间的关系,它遵循山脊形状。微调精度高的条目大致分布在AvgDist的[10,20]范围内,而AvgDist越小或越高的条目表现越差。这表明掩码图像建模中的预测距离应该适中,既不要太大,也不要太小。或许,在掩码预测中,小距离可能会让网络学习到太多的短连接,而大距离可能会让网络很难学习。这些结果也表明,AvgDist可能是一个很好的指标用于检测掩码建模的有效性。
4.3 预测头
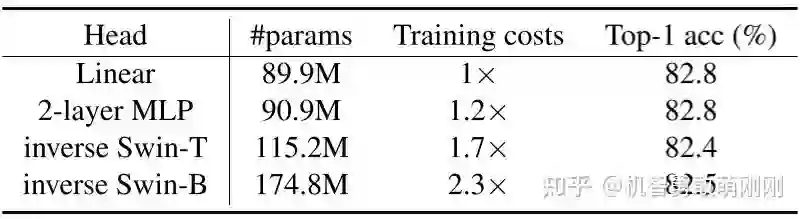
表2给出了不同的预测头的影响。虽然通常复杂的预测头产生的损失略低,但在下游ImageNet-1K任务的迁移性能较低。这表明,<结论①>较强的填涂能力并不一定意味着较好的下游性能。这可能是因为优异的性能很大一部分用于预测头,而不会用于下游任务。<结论②>复杂的预测头带来较高的训练成本。作者证明了SimMIM的单个线性层头在微调度量下已经显示出具有竞争力甚至是最优的迁移性能。这表明,<结论③>如果目标是学习好的特征来进行微调,那么在对比学习方法中对头部设计的重要探索对于掩码图像建模来说可能是不必要的。
4.4 预测分辨率

表3给出了目标分辨率变化的影响。它表明,在 
4.5 预测目标
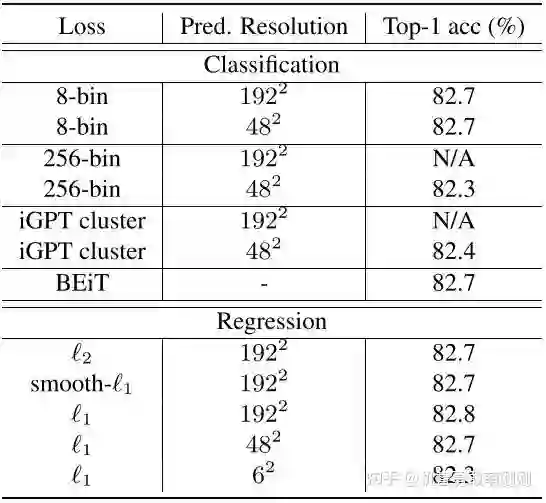
表4比较不同预测目标的效果。结果表明,掩码图像建模的目标不需要与掩码语言建模的分类目标一致。设计与视觉信号本身的性质保持一致的方法效果很好。
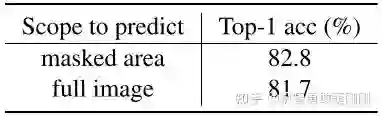
表5比较了两种方法,一种是预测默认设置下的掩码区域,另一种是重建被掩码区域和未被掩码区域。掩蔽区域的预测效果明显优于重建所有图像像素效果。这表明,这两种任务在内部机制上有根本的不同,预测任务可能是一种更有前景的表征学习方法。
4.6 与其他方法比较
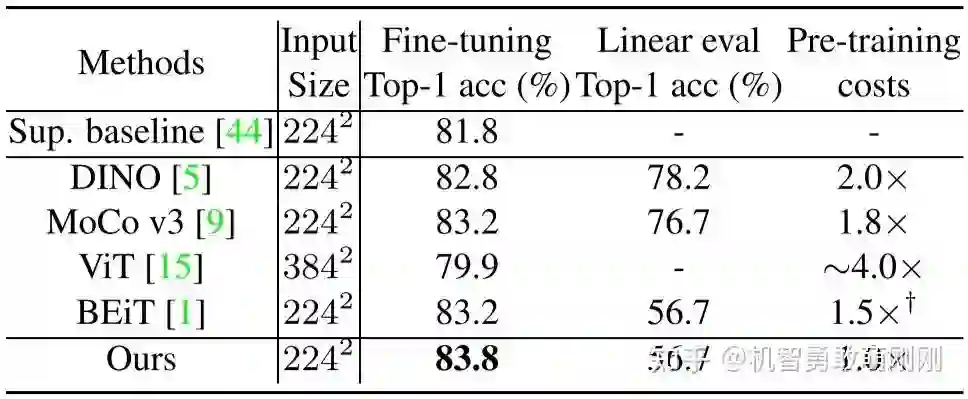
表6比较了SimMIM与使用ViTB进行微调和线性探测的其他方法。SimMIM通过微调达到了83.8%的Top-1准确率,比之前的最佳方法高出了0.6%。SimMIM由于其简单性,保留了最高的训练效率,比DINO、MoCo v3、ViT和BEiT(不包括dVAE训练前的时间)分别高出2.0×、1.8×、~ 4.0×和1.5×。
4.7 可伸缩性实验
作者采用不同模型尺寸的Swin Transformer进行实验,包括Swin-B、Swin-L、SwinV2-H、SwinV2-G。为了减少实验开销,在训练前采用较小的 192^2 的图像尺寸,所有模型都使用ImageNet-1K数据集进行训练,但SwinV2-G使用更大的ImageNet-22K-ext数据集。在微调时,采用较大的 224^2 图像尺寸。对于SwinV2-H,选用更大的分辨率 512^2 。
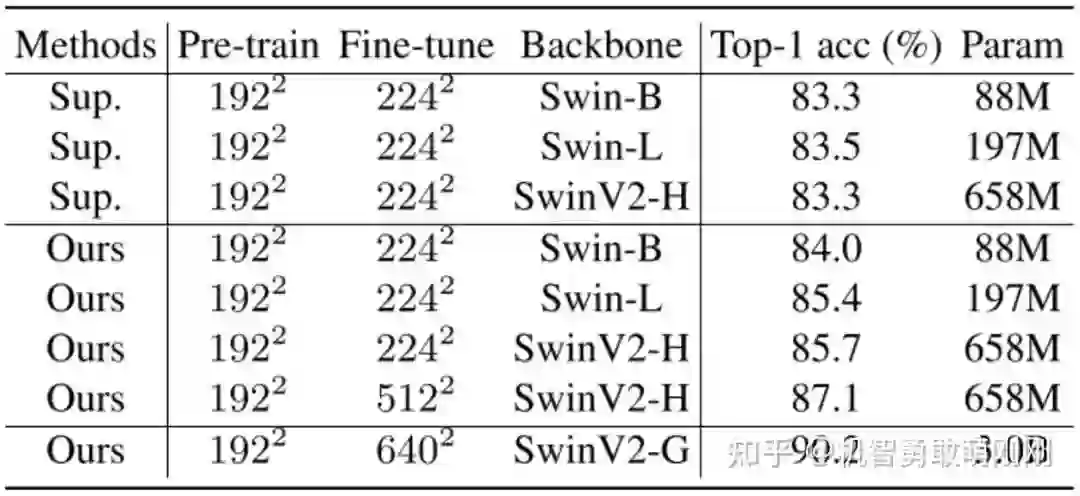
表7列出了SimMIM在不同模型尺寸下的结果,并与有监督的同行进行了比较。在SimMIM预训练下,所有的Swin-B、Swin-L、SwinV2-H的准确率都显著高于有监督的对照组。另外,分辨率为 512^2 的SwinV2-H模型在ImageNet-1K上的top-1精度达到了87.1%,是仅使用ImageNet-1K数据的方法中精度最高的方法。
4.8 可视化结果



>5. 总结
本文提出了一个简单而有效的自监督学习框架,SimMIM,利用掩码图像建模来进行表示学习。这个框架采用尽可能简单的设计,却有着优异的效果:1)带有中等大小的掩码补丁随机掩码图像;2)通过直接回归任务预测原始像素的RGB值;3)预测头可轻如线性层。
上面SimMIM论文和代码下载
后台回复:SimMIM,即可下载论文PDF和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看




