主题: Efficient Processing of Deep Neural Networks: from Algorithms to Hardware Architectures
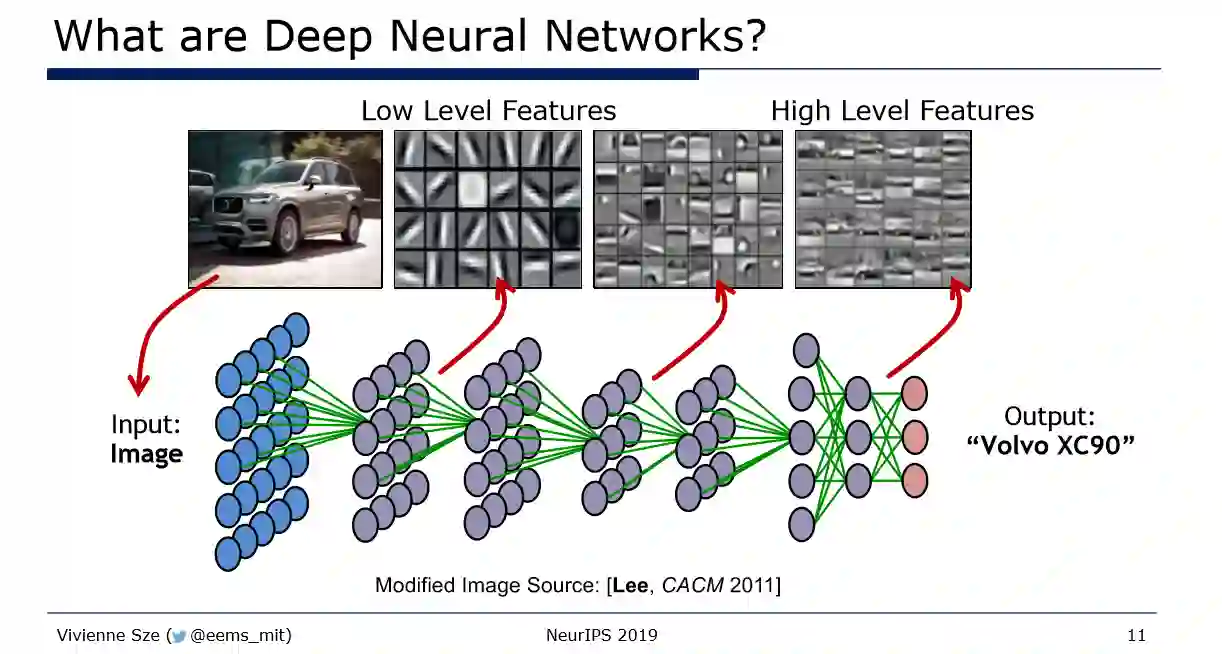
简介: 本教程介绍了用于高效处理深度神经网络(DNN)的方法,这些方法已在许多AI应用程序中使用,包括计算机视觉,语音识别,机器人等。DNN以高计算复杂度为代价,提供了一流的准确性和结果质量。因此,为深度神经网络设计有效的算法和硬件架构是朝着在人工智能系统(例如,自动驾驶汽车,无人机,机器人,智能手机,可穿戴设备,物联网等)中广泛部署DNN迈出的重要一步。在速度,延迟,功耗/能耗和成本方面有严格的限制。 在本教程中,我们将简要概述DNN,讨论支持DNN的各种硬件平台的权衡,包括CPU,GPU,FPGA和ASIC,并重点介绍基准测试/比较指标和评估DNN效率的设计注意事项。然后,我们将从硬件体系结构和网络算法的角度描述降低DNN计算成本的最新技术。最后,我们还将讨论如何将这些技术应用于各种图像处理和计算机视觉任务。
嘉宾介绍: Vivienne Sze是麻省理工学院电气工程和计算机科学系的副教授。她的研究兴趣包括能量感知信号处理算法,便携式多媒体应用的低功耗电路和系统设计,包括计算机视觉,深度学习,自主导航和视频编码。在加入MIT之前,她是TI研发中心的技术人员,在那里她设计了用于视频编码的低功耗算法和体系结构。在高效视频编码(HEVC)的开发过程中,她还代表TI参加了ITU-T和ISO / IEC标准机构的JCT-VC委员会,该委员会获得了黄金时段工程艾美奖。她是《高效视频编码(HEVC):算法和体系结构》(Springer,2014年)的合编者,也是即将出版的《深度神经网络的高效处理》(Morgan&Claypool)的合著者。她是2020年机器学习和系统会议(MLSys)的计划共同主席,并教授MIT设计高效深度学习系统的专业教育课程。