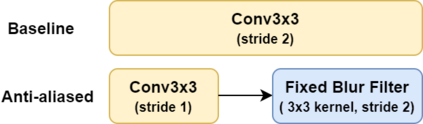
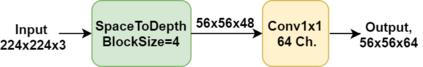Many deep learning models, developed in recent years, reach higher ImageNet accuracy than ResNet50, with fewer or comparable FLOPS count. While FLOPs are often seen as a proxy for network efficiency, when measuring actual GPU training and inference throughput, vanilla ResNet50 is usually significantly faster than its recent competitors, offering better throughput-accuracy trade-off. In this work, we introduce a series of architecture modifications that aim to boost neural networks' accuracy, while retaining their GPU training and inference efficiency. We first demonstrate and discuss the bottlenecks induced by FLOPs-optimizations. We then suggest alternative designs that better utilize GPU structure and assets. Finally, we introduce a new family of GPU-dedicated models, called TResNet, which achieve better accuracy and efficiency than previous ConvNets. Using a TResNet model, with similar GPU throughput to ResNet50, we reach 80.7% top-1 accuracy on ImageNet. Our TResNet models also transfer well and achieve state-of-the-art accuracy on competitive datasets such as Stanford cars (96.0%), CIFAR-10 (99.0%), CIFAR-100 (91.5%) and Oxford-Flowers (99.1%). Implementation is available at: https://github.com/mrT23/TResNet
翻译:近年来开发的很多深层次学习模型比ResNet50的图像网络精确度要高一些,而FLOPS的数值较低或可比较。虽然FLOPs通常被视为网络效率的替代物,但在测量实际的GPU培训和推断输送量时,Vanilla ResNet50通常比其最近的竞争对手快得多,提供了更好的吞吐-准确性交易。在这项工作中,我们引入了一系列旨在提升神经网络准确性、同时保留其GPU培训和推断效率的架构修改。我们首先展示和讨论FLOPs-优化造成的瓶颈。我们然后提出更好的利用GPU结构和资产的替代设计。最后,我们引入了一个新的GPU专用模型系列,称为TRSNet,比以前的ConvNet的准确性和效率更高。我们使用一个类似GPUTT50的模型,我们达到了图像网络上80.7%的顶级-1级精确度。我们的TResNet模型也传输良好,并实现了竞争性数据设置上的最新精确度,例如斯坦福-FAR汽车(99%)、CAR-10 % SA-FAR-ODAR-M(99%)、CIAF-10ers(99%)、CIAR-10ers(99%)。