业界 | Uber提出SBNet:利用激活的稀疏性加速卷积网络
选自Uber
作者:Mengye Ren、Andrei Pokrovsky、Bin Yang、Raquel Urtasun
机器之心编译
参与:Panda
自动驾驶系统有非常高的实时性需求。近日,Uber 的研究人员提出了一种可以在改善检测准确度的同时极大提升速度的算法 SBNet 并在其工程开发博客上对该研究进行了介绍。机器之心对该介绍文章进行了编译,更多详情请参阅原论文。另外,本项目的代码也已在 GitHub 上发布。
论文地址:https://arxiv.org/abs/1801.02108
代码地址:https://github.com/uber/sbnet
为了实现更安全和更可靠的交通运输解决方案,Uber ATG Toronto 的研究者正致力于开发应用了卷积神经网络(CNN)和其它深度学习技术的技术。
CNN 在分析来自激光雷达(LiDAR)传感器的视觉图像和数据上有着广泛的应用。在自动驾驶领域,CNN 能让自动驾驶车辆看见其它汽车和行人、确定它们的准确位置以及解决许多之前无法使用传统算法解决的其它难题。为了确保我们的自动系统是可靠的,这样的 CNN 必须以非常快的速度在 GPU 上运行。在降低使用 CNN 的设备成本和功耗的同时开发改善响应时间和准确度的有效方式一直以来都是一个研究重点。
作为这种努力的一部分,我们开发了一个用于 TensorFlow 的开源算法——稀疏块网络(SBNet:Sparse Blocks Network),该算法可通过利用 CNN 激活中的稀疏性来加速推理。我们的研究表明,当 SBNet 与残差网络(ResNet)架构结合使用时,有可能带来一个数量级的提速。SBNet 允许使用更深和更宽的网络配置进行实时的推理,从而能在降低计算负载的情况下实现准确度的提升。
在这篇文章中,我们将讨论我们构建 SBNet 的方法,并将展示该算法在我们的自动驾驶 3D LiDAR 物体检测器中的实际应用,其实现了显著的时钟加速和检测准确度提升。
背景
传统的深度 CNN 是在数百层上一致为所有的空间位置应用卷积算子,这需要每秒执行数万亿次运算。在我们最新的研究中,我们基于这样一个认识进行了开发——很多运算都浪费在了对无关信息的过度分析上。在一个典型的场景中,仅有少部分被观测数据是重要的;我们将这个现象称为稀疏性(sparsity)。在自然界中,视觉皮层等生物神经网络根据周边视觉(peripheral vision)检测到的运动和减少视网膜周边部分中的密度和颜色信息,从而可以通过聚焦视网膜中央凹视觉来利用稀疏性。
在人工神经网络中,激活稀疏的 CNN 之前已经在手写识别等小规模任务上有研究发现了,但与高度优化的密集卷积实现相比还没有实现真正的加速。
但是,我们的研究表明通过在 CNN 激活中利用我们所说的块稀疏性(block sparsity),可以实现高达一个数量级的实际加速。如图 1 所示:
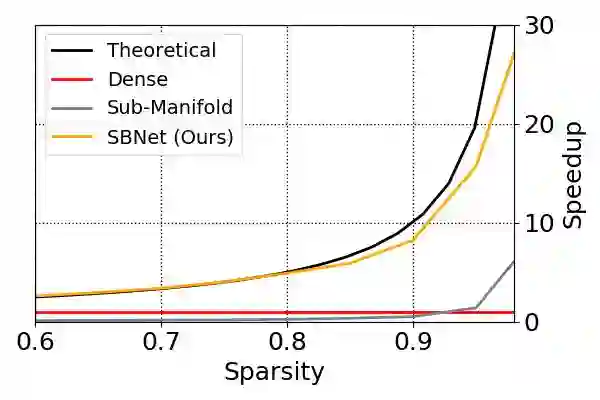
图 1:在激活大小为 700×400,具有 96 个输入通道和 24 个输出通道时,单个稀疏的残差网络块相对于稀疏度的加速,这个结果是在一个英伟达 GTX 1080Ti 上使用 TensorFlow 1.21 + cuDNN 6.0 测得的。
SBNet 介绍
根据这些见解,我们开发了 SBNet,这是一个用于 TensorFlow 的开源算法,能够利用 CNN 的激活中的稀疏性,因此能显著提升推理速度。
为了实现我们算法的目标,我们根据表示激活非零的位置的掩码定义了块稀疏性(block sparsity)。这种掩码可以来自对该问题的之前已有的知识,或者可以直接根据对平均激活进行阈值化来得到。为了利用经过高度优化的密集的卷积算子,我们定义了两个运算操作来将稀疏的激活变换成仅包含非零元素的更小的特征图。
首先通过使用来自输入张量的重叠块来在注意掩码上执行池化运算,然后将其转换成一个传递给块收集操作的索引列表,SBNet 实现了这一目标,如图 2 所示:
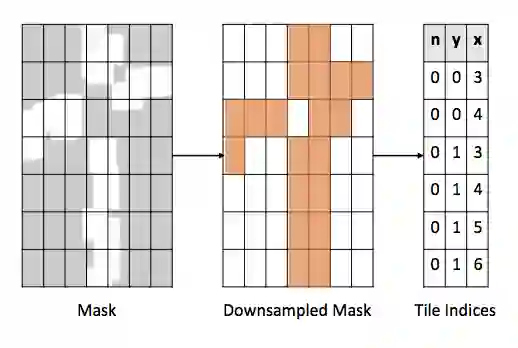
图 2:为了利用 CNN 激活中的稀疏性,SBNet 首先将计算掩码转换成 tile 索引列表
然后聚(gather)操作会将 tile 沿批(batch)维度堆叠在一起,形成一个新的张量。然后使用已有的优化过的密集卷积实现,然后一个自定义的散(scatter) 操作会执行一个反向的运算并将结果写在原始密集输入张量之上。下面的图 3 给出了我们提出的使用了稀疏 gather/scatter 操作的稀疏卷积机制:
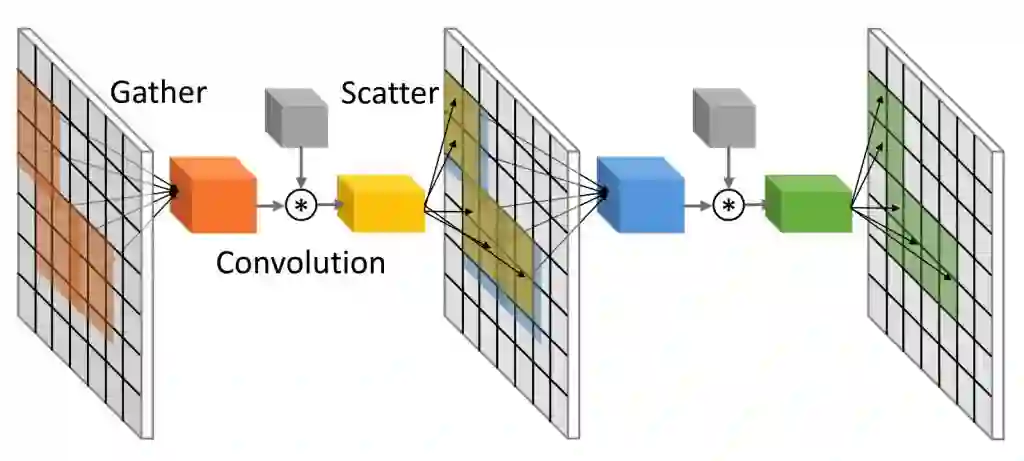
图 3:我们提出的稀疏卷积层能利用稀疏 gather/scatter 操作来加速推理
当我们为 SBNet 设计稀疏操作 API 时,我们希望能将其轻松地整合到流行的 CNN 架构(比如 ResNet 和 Inception)和其它定制的 CNN 构造模块中。为了实现这一目标,我们为我们引入的三种基本操作(reduce_mask、sparse_gather 和 sparse_scatter)发布了 CUDA 实现(和 TensorFlow wrapper。使用这些低层面的运算,我们能为不同的 CNN 架构和配置增加块稀疏性。
下面我们提供了一个 TensorFlow 示例,演示了如何使用SBNet API进行单层稀疏卷积运算:
## A minimal sample implementing a single sparse convolution layer with synthetic data using SBNet primitives.#import numpy as npimport tensorflow as tfsbnet_module = tf.load_op_library('../libsbnet.so')def divup(a, b):return (a+b-1) // b# Specify input tensor dimensions and block-sparsity parametersbatch = 4hw = 256channels = 64blockSize = [16, 16]blockStride = [14, 14]blockOffset = [0, 0]blockCount = [divup(hw, blockStride[0]), divup(hw, blockStride[1])]# build kwargs to simplify op callsinBlockParams = { "bsize": blockSize, "boffset": blockOffset, "bstride": blockStride }outBlockParams = { "bsize": [blockSize[0]-2, blockSize[1]-2], "boffset": blockOffset, "bstride": blockStride }# create a random mask representing attention/a priori sparsity# threshold the mask to a specified percentile sparsitymask = np.random.randn(batch, blockCount[0], blockCount[1], channels).astype(np.float32)threshold = np.percentile(mask, 90)sparseMask = np.greater(mask, threshold).astype(np.float32)# upsample the mask to full resolutionupsampledMask = sparseMask.repeat(blockStride[0], axis=1).repeat(blockStride[1], axis=2)# create a random input tensorx = tf.constant( np.random.randn(batch, hw, hw, channels).astype(np.float32) )# create a random weight tensorw = tf.constant( np.random.randn(3, 3, channels, channels).astype(np.float32) )# reduce the mask to indices by using a fused pooling+indexing operationindices = sbnet_module.reduce_mask(mask, blockCount, tol=0.5, **inBlockParams)# stack active overlapping tiles to batch dimensionblockStack = sbnet_module.sparse_gather(x, indices.bin_counts, indices.active_block_indices, transpose=True, **inBlockParams)# perform dense convolution on a sparse stack of tilesconvBlocks = tf.nn.conv2d(blockStack, w, strides=[1, 1, 1, 1], padding='VALID', data_format='NCHW')# write/scatter the tiles back on top of original tensor# note that the output tensor is reduced by 1 on each side due to 'VALID' convolutionvalidX = x[:, 1:hw-1, 1:hw-1, :]y = sbnet_module.sparse_scatter(convBlocks, indices.bin_counts, indices.active_block_indices,validX, transpose=True, add=False, atomic=False, **outBlockParams)sess = tf.Session()y_output, = sess.run([y])
更多示例请参阅我们的 GitHub 库:https://github.com/uber/sbnet,其中还包含一个完整的 ResNet 模块实现。
接下来,我们将讨论如何将 SBNet 用于训练 Uber ATG 的 3D 车辆检测系统。
应用:根据 LiDAR 点检测 3D 车辆
在 Uber ATG Toronto,我们在根据 LiDAR 点检测 3D 车辆的任务上验证了 SBNet;由于这个任务需要稀疏的输入并且对推理的时间限制要求挺高,所以是一个有效的用例。在我们的模型中,LiDAR 能以每秒 10 次径向扫描的速度产生周围环境的 3D 点云。对于每一次扫描,我们都会采用人工的方式为周围的所有车辆标注 3D 边界框。除了点云和 3D 标签,我们也有从地图提取的道路布局信息。
图 4 给出了数据、车辆标签和道路地图的一张鸟瞰图:
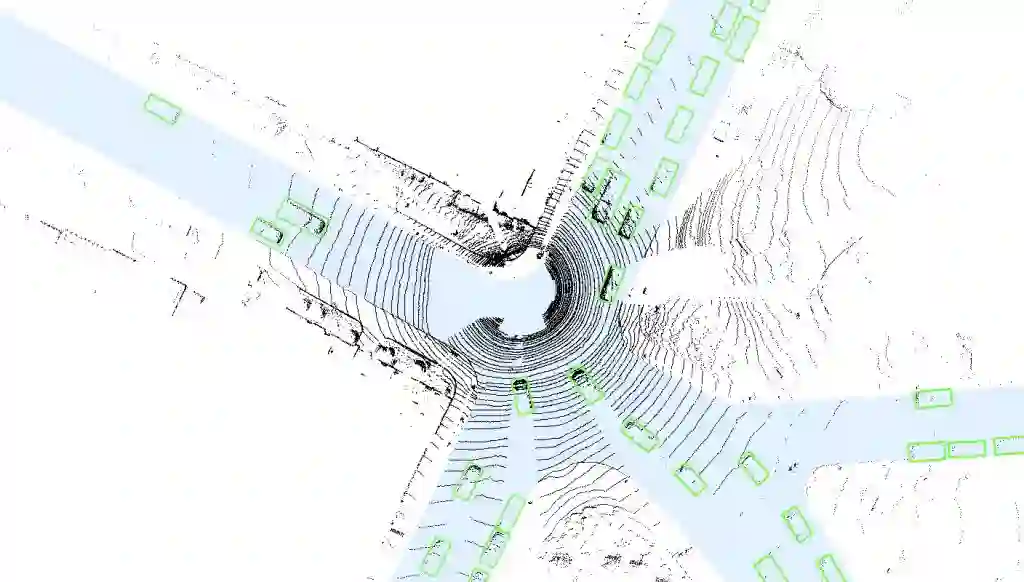
图 4:我们的 LiDAR 3D 车辆检测使用了道路地图作为计算掩码(蓝色),ground-truth 用方框表示(绿色)
首先,我们应用了一个基于 CNN 的方法来解决这一任务,并且从一个俯视视角以每像素 0.1m 的分辨率对该 LiDAR 点云进行了离散化;结果数据表征展现出了超过 95% 的稀疏度。然后,这些数据被输入了一个基于 ResNet 的单发检测器(ResNet-based single-shot detector)。(有关我们的基准检测器的更多详情,请参阅我们的研究论文)。
我们根据一个传统的密集卷积的基准检测器,对 SBNet 的两种变体进行了基准评估——我们将其中的所有层都替换成了对应的块稀疏的版本。这些变体基于两个不同的稀疏性信息来源:一个使用了预计算的道路地图(事先已知),另一个使用了预测得到的前景掩码。道路地图可以从离线的地图中提取,这不会给检测器增加计算时间。预测得到的前景掩码是使用另一个低分辨率 CNN 生成的,并且比道路地图都更高的稀疏度。
在使用 SBNet 时,我们测量了两种变体相对于基准检测器的显著提速。在下面的图 5 中,我们给出了输入数据在不同稀疏程度下测得的速度提升。
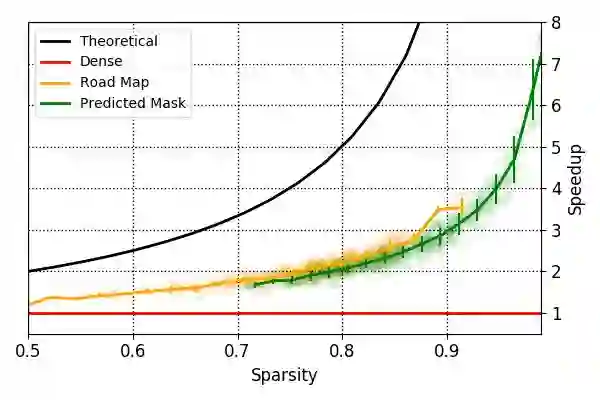
图 5:使用 SBNet,我们的全 3D 车辆检测器网络实现了提速。这是在英伟达 Titan X Pascal 上使用 TensorFlow 1.2.1 和 cuDNN 6.0 得到的结果。
使用道路地图的变体平均有 80% 的稀疏度,对应实现了 2 倍的加速;使用预测掩码的变体平均有大约 90% 的稀疏度,对应实现了 3 倍的加速.
在检测准确度方面,使用 SBNet 架构重新训练检测器会在平均精度上得到 2 个百分点的增益。这说明使用数据稀疏性能够通过减少噪声和方差来使模型训练稳定化,从而在更快的推理时间之外还能得到更准确的 3D 车辆检测。
接下来
我们相信 SBNet 能够广泛应用于各种深度学习架构、模型、应用和稀疏源,我们期待看到深度学习研究社区通过不同的方式使用这些架构构建模块。有关 SBNet 和我们的研究的更详细解释,我们希望你能阅读我们的论文。
对最近这项成果的总结请参看下面的视频:
扩展阅读
M. Ren, A. Pokrovsky, B. Yang, R. Urtasun,「SBNet: Sparse Blocks Network for Fast Inference,」arXiv preprint arXiv:1801.02108, 2018. (GitHub)
Y. LeCun, L. Bottou, Y. Bengio, P. Haffner,「Gradient-based learning applied to document recognition,」in Proceedings of the IEEE, 86 (11): 2278–2324, doi:10.1109/5.726791, 1998.
Abadi et al,「TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems,」arXiv preprint arXiv:1603.04467, 2016.
B. Graham and L. van der Maaten,「Submanifold sparse convolutional networks,」arXiv preprint, arXiv:1706.01307, 2017.
K. He, X. Zhang, S. Ren, J. Sun,「Deep residual learning for image recognition,」in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2017.
A. Lavin and S. Gray,「Fast algorithms for convolutional neural networks,」in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016.

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com

