

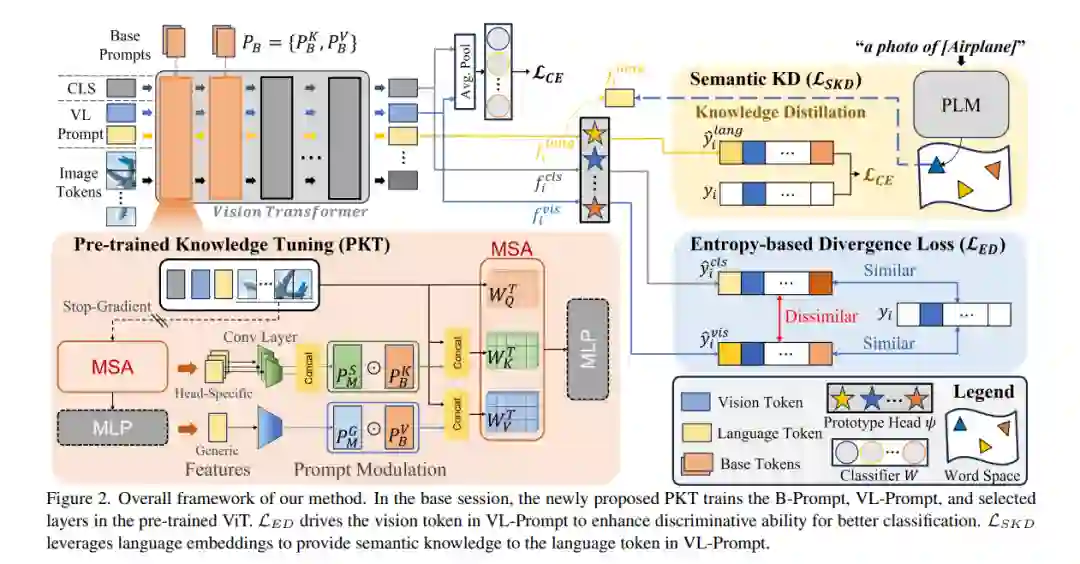
少样本增量类学习(FSCIL)是一项要求模型在只给出每个类的少数样本时递增地学习新类别而不遗忘的任务。FSCIL 面临两个重大挑战:灾难性遗忘和过拟合,这些挑战推动了以往研究主要依赖于浅层模型,如 ResNet-18。尽管它们有限的容量可以减轻遗忘和过拟合问题,但它导致在少次增量会话期间知识转移不足。在本文中,我们认为在大型数据集上预训练的大型模型,如视觉和语言变换器,可以是出色的少样本增量学习者。为此,我们提出了一种名为 PriViLege 的新型 FSCIL 框架,即带有提示功能和知识蒸馏的预训练视觉和语言变换器。我们的框架通过新的预训练知识调整(PKT)和两种损失:基于熵的散度损失和语义知识蒸馏损失,有效地解决了大型模型中的灾难性遗忘和过拟合挑战。实验结果表明,提出的 PriViLege 框架显著优于现有的最先进方法,例如,在 CUB200 中提高了9.38%,在 CIFAR-100 中提高了20.58%,在 miniImageNet 中提高了13.36%。我们的实现代码可在以下链接获取:https://github.com/KHU-AGI/PriViLege。
成为VIP会员查看完整内容
相关内容
Arxiv
225+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
225+阅读 · 2023年4月7日