

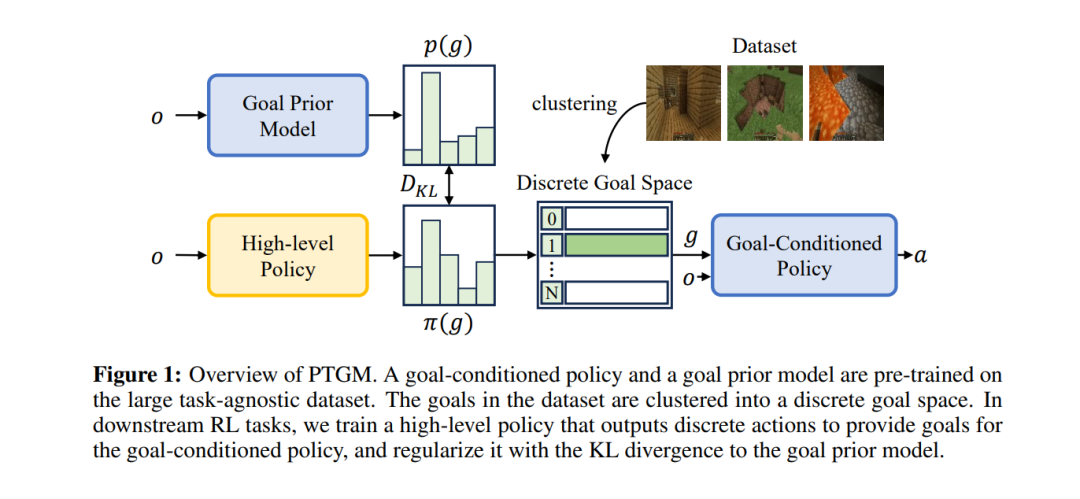
在任务不可知的大型数据集上进行预训练是提高强化学习(RL)在解决复杂任务时样本效率的一种有前景的方法。我们提出了一种名为PTGM的新方法,该方法通过预训练基于目标的模型来增强RL,提供时间抽象和行为规范化。PTGM包括预训练一个低级别、以目标为条件的策略,并训练一个高级别策略为后续RL任务生成目标。为了应对高维目标空间所带来的挑战,同时保持智能体完成各种技能的能力,我们提出了在数据集中对目标进行聚类,形成一个离散的高级别动作空间。此外,我们引入了一个预训练的目标先验模型,以规范化RL中高级别策略的行为,提高样本效率和学习稳定性。在机器人仿真环境和具有挑战性的Minecraft开放世界环境中的实验结果表明,与基线相比,PTGM在样本效率和任务性能方面具有优势。此外,PTGM在获取的低级技能的可解释性和泛化性方面展示了增强的效果。
成为VIP会员查看完整内容

相关内容
Arxiv
224+阅读 · 2023年4月7日


相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日