

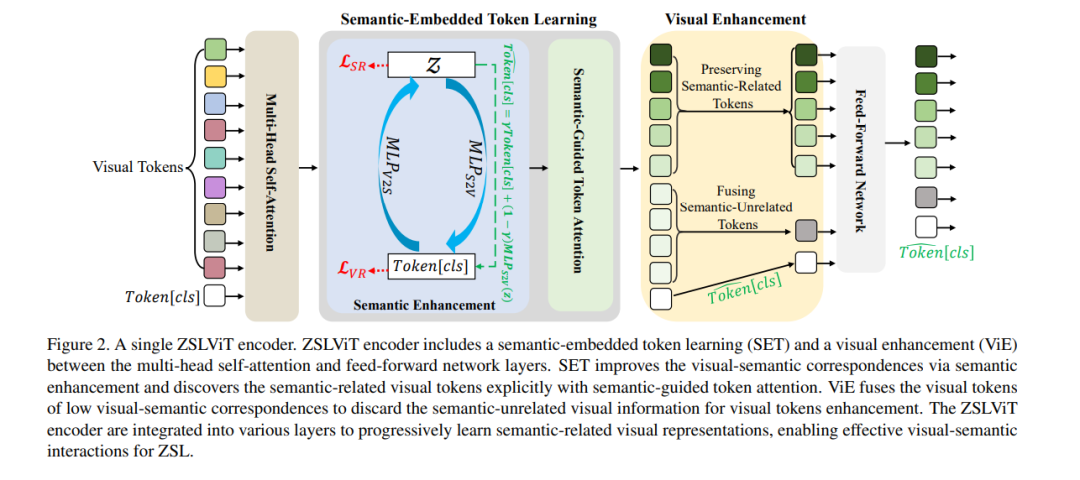
零样本学习(ZSL)通过进行视觉-语义交互来识别未见类别,将语义知识从已见类别传递到未见类别,这一过程得到了语义信息(例如,属性)的支持。然而,现有的ZSL方法仅使用预训练的网络主干(即CNN或ViT)提取视觉特征,由于缺乏语义信息的指导,这些方法未能学习匹配的视觉-语义对应关系来表示与语义相关的视觉特征,导致视觉-语义交互不理想。为解决这一问题,我们提出了一个渐进式语义引导视觉变换器用于零样本学习(简称ZSLViT)。ZSLViT主要考虑了整个网络中的两个属性:一是显式地发现与语义相关的视觉表征,二是丢弃与语义无关的视觉信息。具体来说,我们首先引入了语义嵌入的token学习,通过语义增强和语义引导的token注意力来改善视觉-语义对应关系,并显式地发现与语义相关的视觉token。然后,我们融合低视觉-语义对应关系的视觉token以丢弃与语义无关的视觉信息,用于视觉增强。这两种操作被整合到各种编码器中,以便在ZSL中逐步学习与语义相关的视觉表征,以实现精确的视觉-语义交互。广泛的实验表明,我们的ZSLViT在三个流行的基准数据集上,即CUB、SUN和AWA2,取得了显著的性能提升。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日