【泡泡图灵智库】EAST:一种有效且准确的自然场景文本检测器(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:EAST: An Efficient and Accurate Scene Text Detector
作者:Xinyu Zhou, Cong Yao, He Wen, Yuzhi Wang, Shuchang Zhou, Weiran He, and Jiajun Liang
来源:CVPR 2017
编译:刘小亮
审核:黄文超
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——EAST:一种有效且准确的自然场景文本检测器,该文章发表于CVPR2017。
先前的自然场景文本检测方法已可以很好的完成各种基准测试。然而,在处理一些具有挑战性的场景时,即使它们也使用了深度神经网络模型,但它们还是能力不足,其中因为整体性能应取决于管道中多个阶段和组件的相互作用。在本工作中,我们提出一个简单且强有力的管道,使其可以在自然场景中快速和准确地进行文本检测。此管道使用一个简单的神经网络,直接预测整个图像中任意方向和四边形形状的单词或文本行,消除了中间不必要的步骤,例如候选框聚合和单词划分。由于管道的简单,使得可以集中精力在设计损失函数和神经网络架构上面。最后实验在标准数据集ICDAR2015,COCO-Text和MSRA-TD500,实验表明本文所提的算法在准确性和速率方面明显优于目前最先进的方法。其中,在ICDAR2015数据集,在720p分辨率下可以以13.2fps速率运行,且F分数达到0.7820。
主要贡献
1、本文提出一种由两阶段组成的自然场景文本检测方法:一个全卷积网络和一个NMS合成阶段。FCN(全卷积网络)直接产生文本区域,避免冗余且耗时的中间步骤。
2 、本文管道可以灵活产生字母级或文本行级的预测,且根据不同的应用,几何形状可以是旋转的矩形框或四边形。
3 、本文所提的算法在准确度和速率上明显优于目前最先进的方法。
算法流程
1、下图为本文管道设计和其他方法对比,可以看出本文管道由两阶段组成,避免的中间一些不必要的冗余。
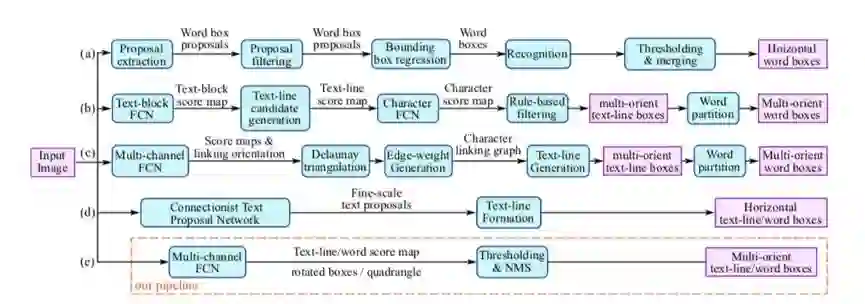
图1 自然场景文本检测几种近期工作的管道比较:(a)水平字母检测和识别管道,来自Jaderberg et al. [12] ;(b)面向多文本检测管道,来自Zhang et al. [48];(c)面向多文本检测管道,来自Yao et al. [41];(d)使用CTPN的水平文本检测,来自Tian et al. [34];(e)本文方法,避免多个中间步骤,仅仅由两部分组成,相比于先前的方法简单很多。
2、本文的神经网络设计如下图。该模型为全卷积网络,由特征提取层,特征融合层和输出层组成。最后输出层可选ROBX或QUAD。
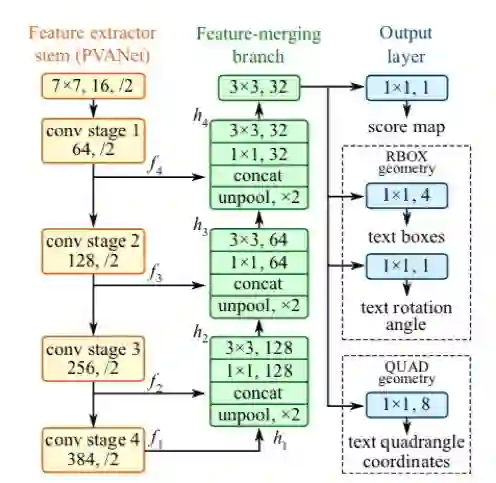
图2 本文文本检测FCN的结构
3、 局部感知NMS(非极大值抑制),与标准的NMS相比,主要在于多了一个合并阶段。迭代两两候选框,如果两个候选框高于某个权值,进行一个加权的合并操作。合并完再做一个标准的NMS。算法如下:

主要结果
本文实验在标准数据集ICDAR2015,COCO-Text和MSRA-TD500上面。
1、定性结果:图3展示了所提算法的几个检测示例。可以看出,它可以处理各种具有挑战性的场景,如不均匀照明,低分辨率,方向变化和透视失真。图4展示所提方法的中间结果。可以看出,经过训练的模型可以产生高精度的几何框和score map,而且可以检测各个不同方向的文本。

图3 所提算法的定性结果。(a)ICDAR 2015;(b)MSRA-TD500;(c)COCO-Text

图4 所提算法的中间结果。(a)从d1和d4中估计几何框;(b)从d2和d3中估计集合框(c)从文本实例中估计角度;(d)从文本实例中预测旋转矩阵框。(a),(b)和(c)中的映射用颜色编码。 注意,只有前景像素的值有效。其中d1,d2,d3和d4分别表示一个像素到其对应矩形的顶部,右侧,底部和左侧边界的距离。
2、定量结果:在ICDAR2015数据集,本文方法在多尺度情况下F-score为0.8072,比先前最好的方法【41】多0.16左右,(0.8072vs0.6477)。同样在COCO-Text和MSRA-TD500也达到相对比较好的结果。
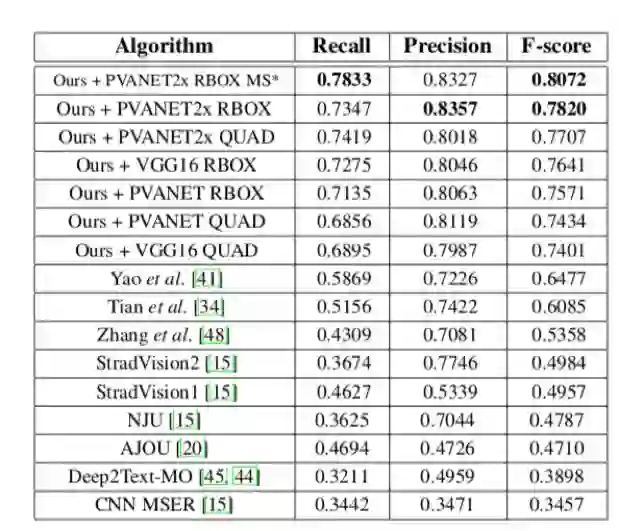
表1 在ICDAR 2015 挑战4:自然场景文本定位任务下的结果。MS:多尺度测试。
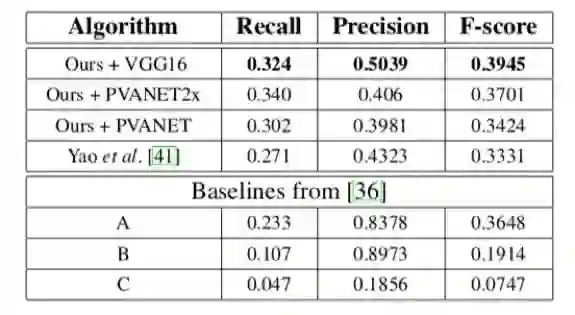
表2 在COCO-Text下的结果
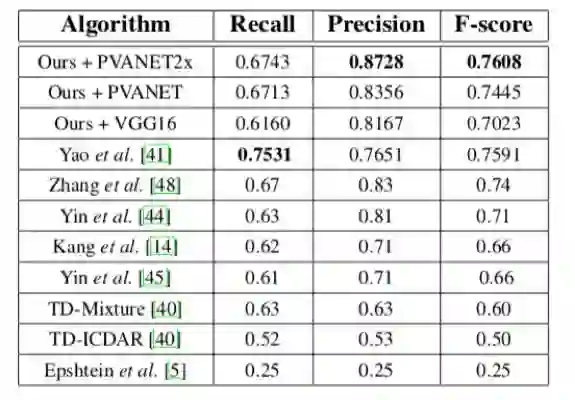
表 3 在MSRA-TD500下的结果
3、速率比较结果: 在ICDAR2015数据集上的运行500张图片的平均速率,硬件条件为:单NVIDIA Titan X ,Intel E5-2670 v3 @ 2.30GHz CPU 。本文方法最快可以达到16.8FPS。
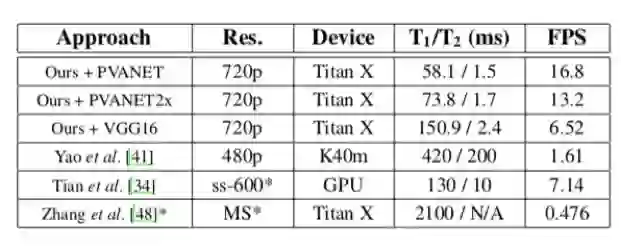
表4 不同方法下时间损耗的比较:T1是网络预测时间,T2是后期处理所用时间。其中Tian et al. [34],ss-600意思是短边为600,130ms包括两个网络的时间。对于Zhang et al. [48],MS意思是使用200,500,1000三种尺度且使用在MSRA-TD500上面。对于PVANET,PVANET2x和VGG16,本文对于三个模型的每像素理论触发器分别为18KOps,44.4KOps和331.6KOps。

Abstract
Previous approaches for scene text detection have already achieved promising performances across various benchmarks. However, they usually fall short when dealing with challenging scenarios, even when equipped with deep neural network models, because the overall performance is determined by the interplay of multiple stages and components in the pipelines. In this work, we propose a simple yet powerful pipeline that yields fast and accurate text detection in natural scenes. The pipeline directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images, eliminating unnecessary intermediate steps (e.g., candidate aggregation and word partitioning), with a single neural network. The simplicity of our pipeline allows concentrating efforts on designing loss functions and neural network architecture. Experiments on standard datasets including ICDAR 2015, COCO-Text and MSRA-TD500 demonstrate that the proposed algorithm significantly outperforms state-of-the-art methods in terms of both accuracy and efficiency. On the ICDAR 2015 dataset, the proposed algorithm achieves an F-score of 0.7820 at 13.2fps at 720p resolution.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com

