
摘要
与批量学习不同的是,在批量学习中所有的训练数据都是一次性可用的,而持续学习代表了一组方法,这些方法可以积累知识,并使用序列可用的数据连续学习。与人类的学习过程一样,不断学习具有学习、融合和积累不同时间步的新知识的能力,被认为具有很高的现实意义。因此,持续学习在各种人工智能任务中得到了研究。本文综述了计算机视觉中持续学习的最新进展。特别地,这些作品是根据它们的代表性技术进行分组的,包括正则化、知识蒸馏、记忆、生成重放、参数隔离以及上述技术的组合。针对每一类技术,分别介绍了其特点及其在计算机视觉中的应用。在概述的最后,讨论了几个子领域,在这些子领域中,持续的知识积累可能会有帮助,而持续学习还没有得到很好的研究。
https://www.zhuanzhi.ai/paper/a13ad85605ab12d401a6b2e74bc01d8a
引言
人类的学习是一个渐进的过程。在人类的一生中,人类不断地接受和学习新知识。新知识在发挥自身积累作用的同时,也对原有知识进行补充和修正。相比之下,传统的机器学习和深度学习范式通常区分知识训练和知识推理的过程,模型需要在有限的时间内在预先准备好的数据集上完成训练,然后使用这些数据集进行推理。随着相机和手机的广泛普及,每天都有大量新的图片和视频被捕捉和分享。这就产生了新的需求,特别是在计算机视觉领域,模型在推理过程中要连续不断地学习和更新自己,因为从头开始训练模型以适应每天新生成的数据是非常耗时和低效的。
由于神经网络与人脑的结构不同,神经网络训练不易从原来的批量学习模式转变为新的连续学习模式。特别是存在两个主要问题。首先,按照序列学习多个类别的数据容易导致灾难性遗忘的问题[1,2]。这意味着,在从新类别的数据更新模型参数后,模型在先前学习类别上的性能通常会急剧下降。其次,当按顺序从同一类别的新数据中学习时,也会导致概念漂移问题[3,4,5],因为新数据可能会以不可预见的方式改变该类别的数据分布[6]。因此,持续学习的总体任务是解决稳定性-可塑性困境[7,8],这就要求神经网络在保持学习新知识的能力的同时,防止遗忘之前学习过的知识。
近年来,在计算机视觉的各个子领域中提出了越来越多的持续学习方法,如图1所示。此外,2020年和2021年还举办了若干与计算机视觉中的持续学习有关的比赛[9,10]。因此,本文综述了计算机视觉中持续学习的最新进展。我们将这一概述的主要贡献总结如下。(1)系统地综述了计算机视觉中持续学习的最新进展。(2)介绍了用于不同计算机视觉任务的各种持续学习技术,包括正则化、知识提取、基于记忆、生成重放和参数隔离。(3)讨论了计算机视觉中持续学习可能有所帮助但仍未得到充分研究的子领域。
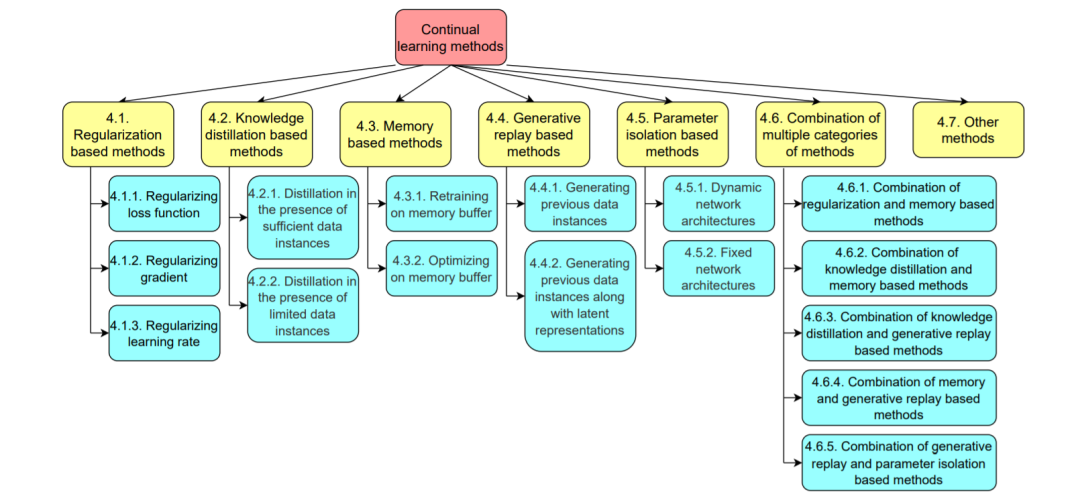
本文的其余部分组织如下。第二节给出了持续学习的定义。第3节介绍了这一领域常用的评估指标。第4节讨论了各种类型的持续学习方法及其在计算机视觉中的应用。在第5节中讨论了计算机视觉中没有很好地利用持续学习的子领域。最后,第六部分对全文进行总结。

