
摘要
深度半监督学习是一个快速发展的领域,具有一系列的实际应用。
本文从模型设计和无监督损失函数的角度对深度半监督学习方法的基本原理和最新进展进行了全面的综述。
我们首先提出了一种深度半监督学习分类法,该分类法对现有方法进行分类,包括深度生成方法、一致性正则化方法、基于图的方法、伪标记方法和混合方法。然后,我们根据损失类型、贡献和架构差异对这些方法进行了详细的比较。
在总结近年来研究进展的基础上,进一步探讨了现有方法的不足之处,并提出了一些探索性的解决方案。
https://arxiv.org/pdf/2103.00550.pdf
引言
深度学习一直是一个活跃的研究领域,在模式识别[1]、[2]、数据挖掘[3]、统计学习[4]、计算机视觉[5]、[6]、自然语言处理[7]、[8]等领域有着丰富的应用。它利用了大量高质量的标记数据,在[9]、[10]的理论和实践中都取得了巨大的成功,特别是在监督学习场景中。然而,标签样品通常是困难的,昂贵的,或耗时获得。标记过程通常需要专家的努力,这是训练一个优秀的全监督深度神经网络的主要限制之一。例如,在医疗任务中,测量是用昂贵的机器进行的,标签是由多个人类专家耗时分析得出的。如果只有少数标记的样本可用,建立一个成功的学习系统是具有挑战性的。相比之下,未标记的数据通常是丰富的,可以很容易地或廉价地获得。因此,它是可取的利用大量的未标记的数据,以改善学习性能给定的少量标记样本。因此,半监督学习(semi-supervised learning, SSL)一直是近十年来机器学习领域的研究热点。
SSL是一种学习范式,它与构建使用标记数据和未标记数据的模型有关。与只使用标记数据的监督学习算法相比,SSL方法可以通过使用额外的未标记实例来提高学习性能。通过对监督学习算法和非监督学习算法的扩展,可以很容易地获得SSL算法。SSL算法提供了一种从未标记的示例中探索潜在模式的方法,减轻了对大量标记[13]的需求。根据系统的关键目标函数,可以有半监督分类、半监督聚类或半监督回归。我们提供的定义如下:
-
半监督分类。给定一个包含有标记的实例和无标记的实例的训练数据集,半监督分类的目标是同时从有标记的和无标记的数据训练分类器,这样它比只在有标记的数据上训练的有监督分类器更好。
-
半监督聚类。假设训练数据集由未标记的实例和一些关于聚类的监督信息组成,半监督聚类的目标是获得比单独从无标记数据聚类更好的聚类。半监督聚类也称为约束聚类。
-
半监督回归。给定一个包含有标记的实例和没有标记的实例的训练数据集,半监督回归的目标是从一个单独带有标记数据的回归算法改进回归算法的性能,该回归算法预测一个实值输出,而不是一个类标签。
为了更清楚、更具体地解释SSL,我们重点研究了图像分类问题。本调查中描述的思想可以毫无困难地适应其他情况,如对象检测,语义分割,聚类,或回归。因此,在本研究中,我们主要回顾了利用未标记数据进行图像分类的方法。
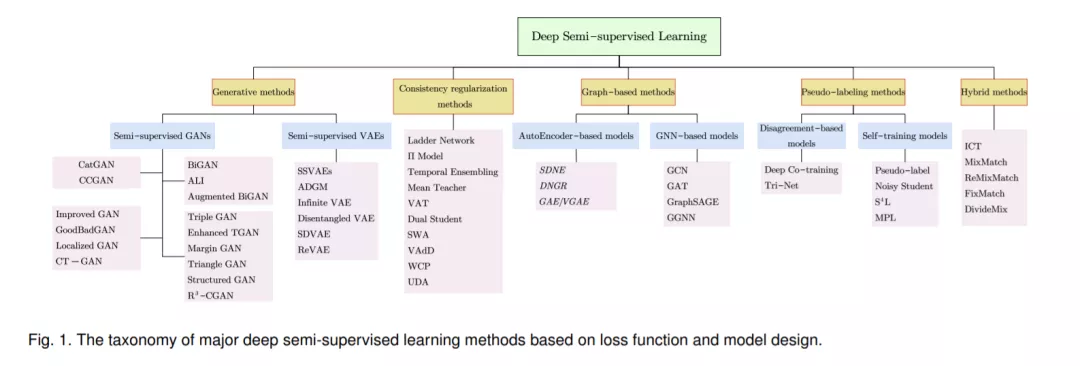
SSL方法有很多种,包括生成模型[14],[15],半监督支持向量机[16],[17],基于图的方法[18],[19],[20],[21]和联合训练[22]。我们向感兴趣的读者推荐[12]、[23],它们提供了传统SSL方法的全面概述。目前,深度神经网络已经在许多研究领域占据主导地位。重要的是要采用经典的SSL框架,并为深度学习设置开发新的SSL方法,这将导致深度半监督学习(DSSL)。DSSL研究了如何通过深度神经网络有效地利用标记数据和未标记数据。已经提出了相当多的DSSL方法。根据半监督损失函数和模型设计最显著的特征,我们将DSSL分为五类,即生成法、一致性正则化法、基于图的方法、伪标记方法和混合方法。本文献使用的总体分类法如图1所示。
在[12],[23]中有很多具有代表性的作品,但是一些新兴的技术并没有被纳入其中,尤其是在深度学习取得巨大成功之后。例如,深度半监督方法提出了新的技术,如使用对抗训练生成新的训练数据。另外,[13]侧重于统一SSL的评价指标,[24]只回顾了SSL的一部分,没有对SSL进行全面的概述。最近,Ouali等人的综述[25]给出了与我们类似的DSSL概念。然而,它不能与现有的方法相比,基于它们的分类,并提供了未来的趋势和存在的问题的观点。在前人研究的基础上,结合最新的研究,我们将对基础理论进行综述,并对深度半监督方法进行比较。总结一下,我们的贡献如下:
我们对DSSL方法进行了详细的回顾,并介绍了主要DSSL方法的分类、背景知识和变体模型。人们可以很快地掌握DSSL的前沿思想。
我们将DSSL方法分为生成方法、一致性正则化方法、基于图形的方法、伪标记方法和混合方法,每一种方法都有特定的类型。我们回顾了每一类的变体,并给出了标准化的描述和统一的示意图。
我们确定了该领域的几个开放问题,并讨论了DSSL的未来方向。

