一篇文章了解视频对象分割

更多干货内容请关注微信号“AI 前线”,ID:ai-front

DAVIS-2016 视频对象分割数据集中带注释的真值帧本篇文章是关于视频对象分割算法技术发展水平的两篇系列文章中的第一篇。第一部分介绍视频对象分割算法中的一系列问题和“经典的”解决方案。这篇文章将简要介绍:
问题、数据集、挑战赛
我们今天要将一个新的数据集公布给大家!
DAVIS-2016 的两种主要方法:MaskTrack 和 OSVOS。所有其它视频分割算法也都以此算法为基础。
在第二部分,笔者提出了一个比较所有现有的用来应对 DAVIS-2017 视频对象分割挑战赛的方法的表格,总结和突出叙述一些精品算法,并指出新的趋势和方向。文中假定研究人员熟悉计算机视觉和深度学习中的一些概念,这些概念很容易理解。笔者希望能将此计算机视觉挑战赛介绍给大家,并让新手能快速地熟悉它。
计算机视觉中有三个传统经典的任务:分类、检测和分割。分类可以回答“是什么”之类的问题,检测和分割可以回答“在何处”的问题,分割的目的在于使其准精度可达到象素级。
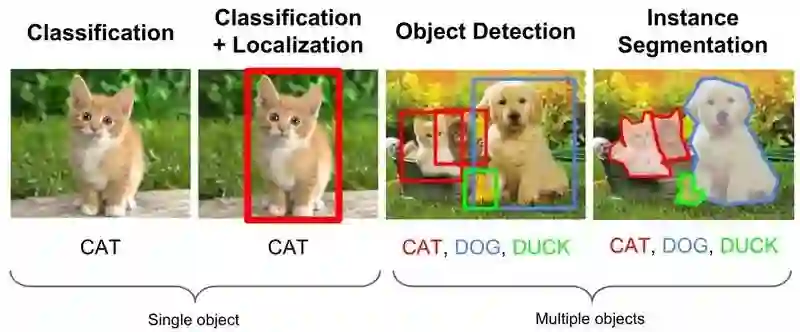
经典的计算机视觉任务(选自斯坦福大学 cs231n 课程幻灯片图像)
2016 年,我们观察到语义分割已经发展成熟,甚至现有的数据集可能开始饱和。同时,2017 年可以说是视频对象分割相关对象如动作分类、动作(时间)分割、语义分割取得突破性成就的一年。在这些文章中,我们将重点讨论视频对象分割。
假设读者熟悉语义分割,视频对象分割的任务基本上多了两个差异:
我们要对一般的非语义对象进行分割。
增加了一个时间因素:我们的任务是在视频的每个连续帧中找到相关的对象相对应的像素。
这也可以被看作是一个像素级的对象跟踪问题。
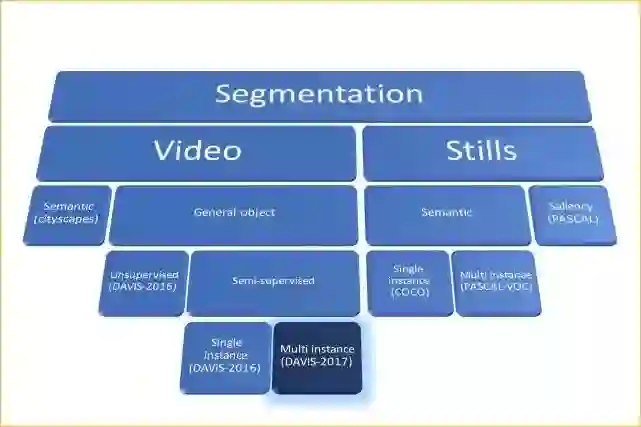
分割:即空间的子分区。对图中的每一叶节点均给出了一个示例数据集。
在视频制作中,我们可以将问题分为两类:
非监督式任务(又名视频显著性检测):任务是在视频中找到并分割主要对象。也就是说算法本身应该决定“主要”对象是什么。
半监督任务: 第一帧的给定真值分割掩膜(只)作为输入,在每个连续帧中分割带注释的对象。
在半监督的情况下,可将其扩展到多目标分割中,正如在 DAVIS-2017 挑战赛中看到的那样。

DAVIS-2016 (左) 和 DAVIS-2017 (右) 的主要区别:多实例分割
正如您所看到的,DAVIS 是一个具有优质像素的数据集,并且该数据集带有注释性的真值。它的目的是重现真实的视频场景:如相机抖动、背景杂波、闭塞和其他复杂情形。
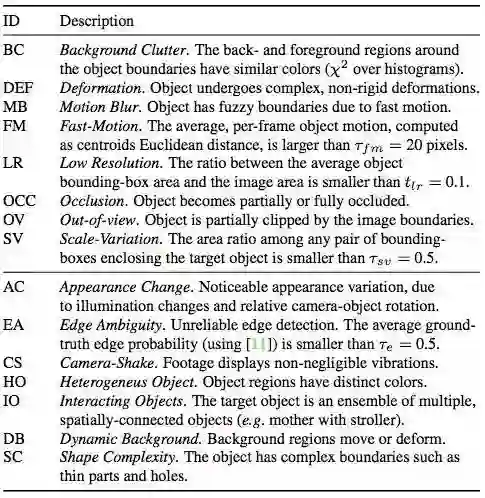
衡量分割成功与否有两个主要指标:
区域相似度是掩码 M 与真值 G 之间的交集
区域相似性: 即预估分割与地面真值掩模的交并比。轮廓精度是轮廓的 F 值,该值以查全率和查准率为基础
轮廓精度: 它把掩码作为一组封闭的轮廓,计算轮廓的 F 值,了解查全率和查准率。
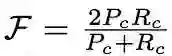
直观 - 区域相似性测量误标记像素的数量,而轮廓精度测量分割边界的精度。
公布一个新的数据集!GyGO:Visualead 提出的电子商务视频对象分割
我们将在接下来的几周发布 GyGO,GyGO 是一个数据集,主要关注于视频对象分割的特定、简单的应用实例如电子商务。其中包括的短视频大约有 150 个。
https://github.com/ilchemla/gygo-dataset
一方面,一组镜头的处理非常简单,因为它们几乎没有被遮挡、快速运动或发生上面提到的许多其他复杂的情形。另一方面,与 DAVIS-2016 数据集相比,这些视频对象有更多不同的类别,其中许多组镜头包含已知的语义类别(人、车等)。GyGO 数据集专门应用于智能手机捕获的视频,它的帧相对稀疏(带标注的视频速度是~5 fps))。
https://youtu.be/4RQff9bfJsk
GyGO 电子商务视频对象分割数据集:Teaser
我们公开发布主要有两个目标:
解决目前视频对象分割数据严重缺乏的问题。虽然只有几百个带注释的视频,但我们相信每一次贡献都有可能提高其性能。在分析中,我们已经表明,GyGO 和 DAVIS 数据集的联合训练能完善推理结果。
促进更开放、共享的文化,鼓励其他研究人员加入我们一起努力:)DAVIS 数据集和研究生态系统给了我们很大帮助。我们希望社区也能发现我们的数据集非常有用。
随着单个对象视频分割 DAVIS-2016 数据集的发布,两个主流方法出现了:MaskTrack 和 OSVOS. 观察一下 DAVIS-2017 挑战赛的竞争者,似乎每一个团队的解决方案中都用到了其中一个方法 ,这使它们立即成为了经典。 让我们看看这两种方法的工作原理:
一次视频对象分割
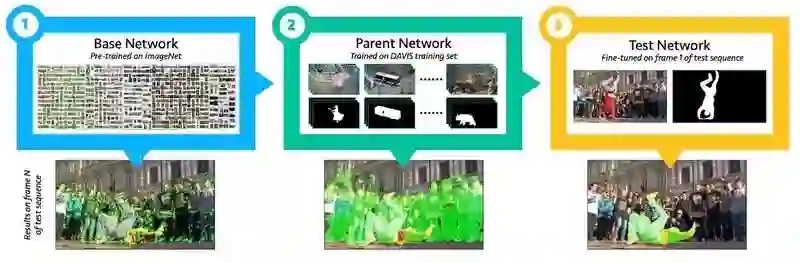
OSVOS 背后的概念简单但有效:
OSVOS 训练流水线
以在 imagenet 上预先训练的网络 (如 VGG-16) 分类为例。
首先,将它转换成一个完全的卷积网络,如 FCN,以保存空间信息:
删除底端的 FC 层。
插入一个新的损失:像素 sigmoid 均衡的交叉熵(HED 以前使用过)。现在每个像素分别被分为前景和背景。
在 DAVIS-2016 训练集上训练该完全卷积网络训练。
一次训练:在推理期间,给定一个用于分割的新的输入视频,和给第一帧的真值标注(记住,这是一个半监督的问题),创建一个新的模型,用 [ 3 ] 中训练的权重将其初始化,并在第一帧上进行微调。
这个过程将生成一个独特的模型,每一个新视频都只使用一次该模型,根据第一帧注释,该模型对于每个视频都是过度拟合的。因为对于大多数视频来说,对象和背景的外观并没有完全改变,这个模型产生了很好的效果。当然,这种模型对其他随机视频镜头来说效果较差。
注:OSVOS 方法分类的帧是独立的,它没有使用视频中的时间信息。
OSVOS 独立地对视频的每一帧进行改进,MaskTrack 亦考虑到了其中包含的时间信息:
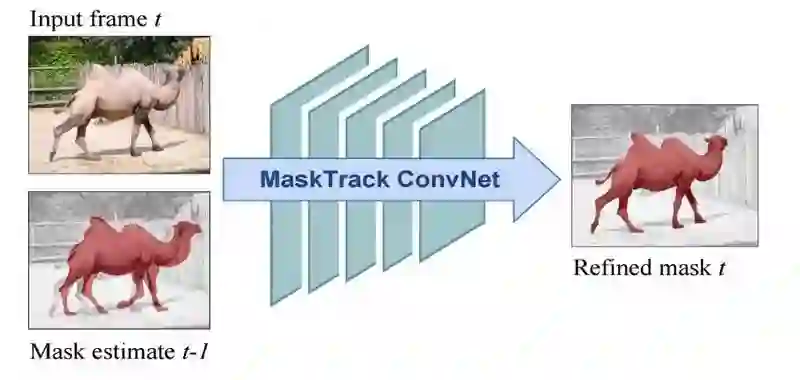
MaskTrack 掩模传播模块
每个帧都将前一帧的预测掩码作为附加信息输入到网络中,输入现在有 4 个路径(RGB 加以前的掩码)。用第一帧给出的真值注释初始化此过程。
该网络最初是以 DeepLab VGG-16(模块)为基础的,对其进行的训练是从语义分割和图像显著性数据集两个方面开始的。前一个掩模路径的输入是由每个静止图像的真值注释转换人工合成的。
添加相同的第二个以光流输入为基础的流网络。模型的权重与 RGB 流相同。取两个流的结果的平均值。
线上训练:使用第一帧真值注释合成额外的特定的视频的训练数据。
注意:这两种方法都依赖于静止图像训练(与视频相反,数据集数据集小且稀少)。
总之,在这篇介绍性的文章中,我们已经描述了视频对象分割的问题,并在 2016 年提出了解决这个问题的主要方法。有了这方面的知识,我们准备好进行二次改进,以便在 2017 年提出最先进的算法。
我想对 DAVIS 数据集和挑战赛背后的出色团队以及他们所付出的辛勤劳动表示感谢。没有你们,这一切都不会存在。
本文中所描述和分析的主要文件如下所述。
视频对象分割的基准数据集与评价方法:F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung, Computer Vision and Pattern Recognition (CVPR) 2016
2017 DAVIS 视频对象分割挑战赛:J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool, arXiv:1704.00675, 2017
从静态图像中研究视频对象分割:F. Perazzi, A. Khoreva, R. Benenson, B. Schiele, A. Sorkine-HornungCVPR 2017, Honolulu, USA.
一次视频对象分割:S. Caelles, K.K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, and L. Van Gool, Computer Vision and Pattern Recognition (CVPR), 2017
计算机视觉和机器学习。Visualead 研究主管。关键词: 理性、创业公司、摄影和游戏。查看英文原文:
https://techburst.io/video-object-segmentation-the-basics-758e77321914




