CVPR 2019 | 视频内容消除新突破——「Deep Flow-Guided」

MIT周博磊——视频场景内容编辑与剪辑,将是下一个研究热点!
AI 科技评论按:视频内容消除的关键在于对视频缺失区域的填充,但由于视频相比图片多了时间维度,因此难以保持视频内容空间与时间的一致性,当前该项技术仍极具挑战性。但本文将展示由香港中文大学的周博磊等研究学者们,提出的一种新型 Deep Flow-Guided 方法进行视频内容消除。该技术不再是直接填充每个帧的 RGB 像素,而是将其转化为像素点扩充问题,这项研究成果被选入 CVPR 2019 论文之列。

图 1 视频内容消除
具体实现步骤
第一步,使用新设计的深度光流场合成神经网络(DFC-Net)在视频帧上合成表示空间与时间关系的光流场,即整个视频图像中各像素点随时间的运动情况;然后将这个光流场作为像素扩充的导向,使其精确填充视频中的缺失区域。DFC-Net 在合成光流场的过程中遵循粗略到精细的细化原则,结合光流量的难样本挖掘,整个神经网络的质量得到了进一步的提高。
最终,以合成光流场作为导向则可精确填充缺失的视频区域。将这个方法在 DAVIS 和 YouTube-VOS 数据集上进行定性和定量评估,结果显示其运行质量和速度都表现出了超常的技术水平。
框架结构
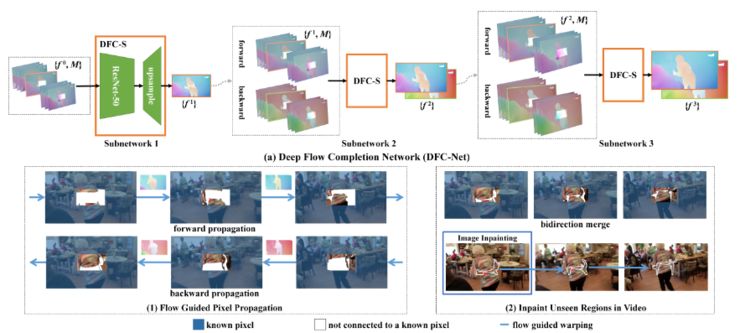
图 2 Flow-Guided Frame Inpainting
此方法框架包含两步——第一步是合成缺失的光流场,第二步是以合成光流场为导向,对像素点进行扩充。
在第一步中,DFC-Net 用来对光流场进行由粗略到精细的合成。DFC-Net 由名为 DFC-S 的三个类似的子网络组成;第一个子网以相对粗略的比例估计光流量,并将它们反馈到第二个和第三个子网络中进一步细化。在第二步中,以合成的光流场为导向,通过不同帧的光流对已知区域中的像素点进行扩充,从而填充大部分缺失区域。然后采用传统的图像修复神经网络来填充在整个视频中剩余的一些细节区域。
正是因为在第一步中这个方法对光流的估计较为精确,所以可以很容易得到部分视频内容消除后连贯的完整视频。
消除结果

图 3 视频消除过程展示
图 3 展示了使用 Deep Flow-Guided 进行视频内容消除的过程。对于每个输入序列(奇数行),图片上显示了带有缺失区域覆盖掩膜的代表帧;在偶数行中则显示了最终的消除结果。

图 4 与其他方法的结果对比
图 4 则向我们展示了 Deep Flow-Guided 方法与 Huang et al 方法进行视频内容消除后的结果对比,可以看出该方法的消除结果更加精准,消除部分的衔接更加自然。
更多内容,AI 科技评论将其整理如下:
原文链接
https://nbei.github.io/video-inpainting.html
论文地址
https://arxiv.org/abs/1905.02884?context=cs
Github 开源地址
https://github.com/nbei/Deep-Flow-Guided-Video-Inpainting
另外,CVPR 2019 还有 10 天就开幕了,想了解更多CVPR的论文推荐与解读,可点击阅读原文进入AI研习社CVPR顶会交流小组查看。
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。

今日限量赠送3张门票优惠码,门票原价1999元,现价仅950元,限量3张,送完即止。(打开以下任意一条链接即可兑换,先到先得)
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8e103
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8de34
https://gair.leiphone.com/gair/coupon/s/5cf4e5cf8db16






