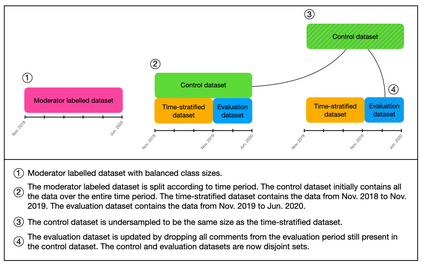
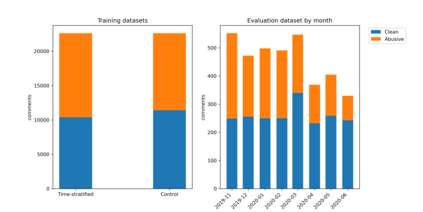
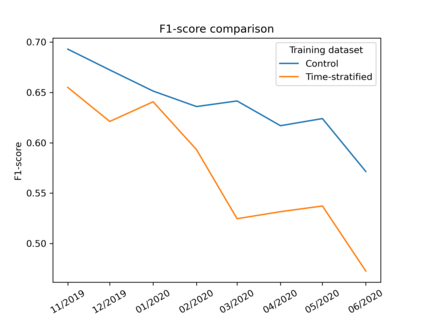
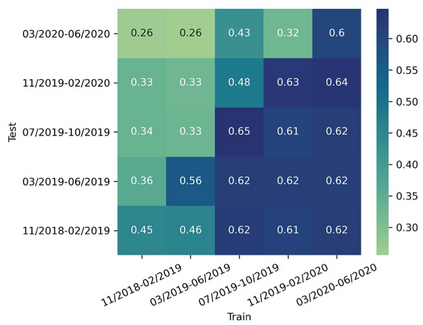
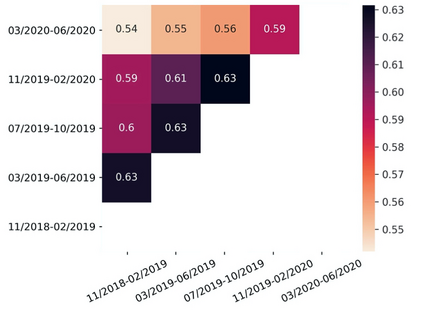
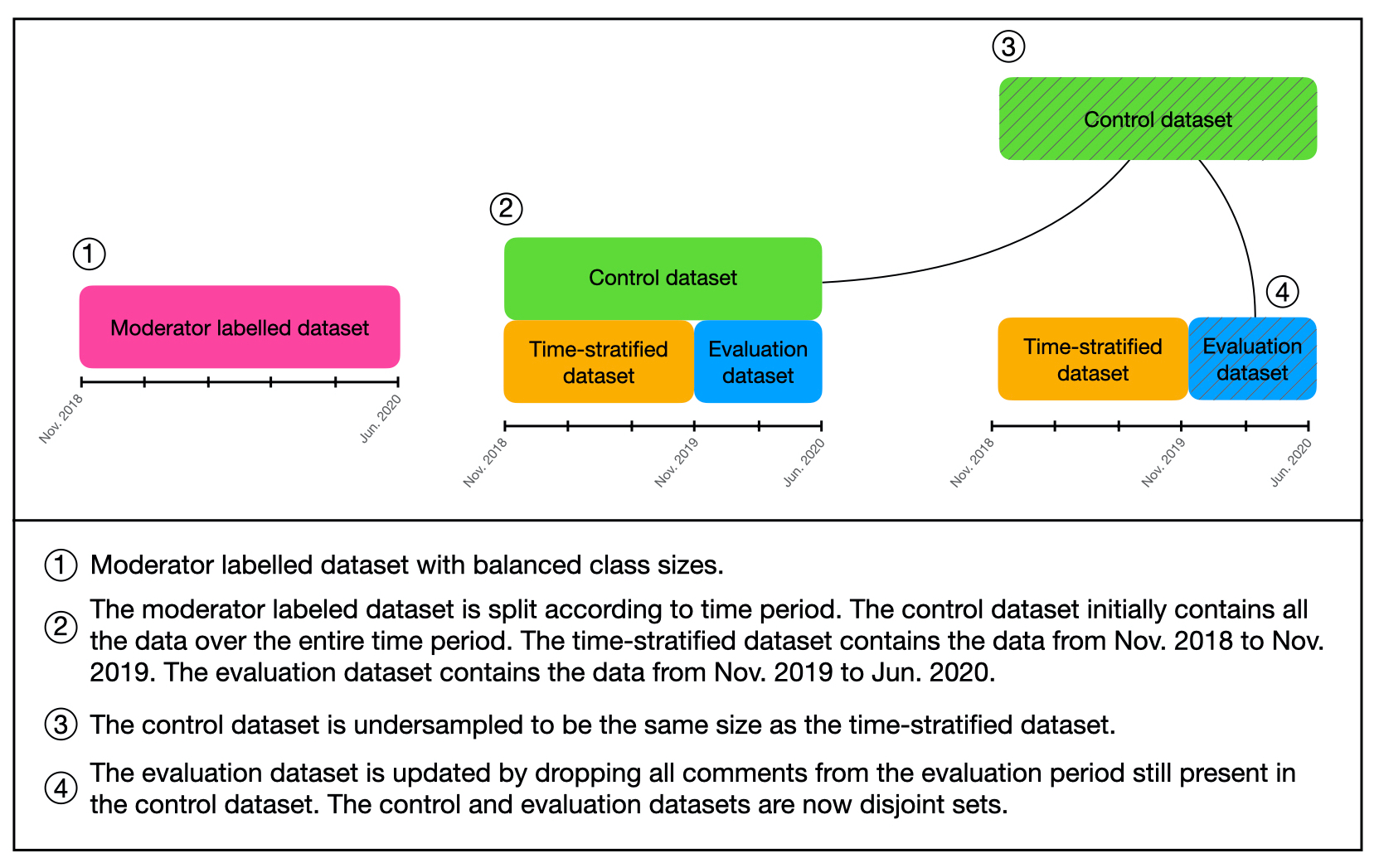
The spread of online hate has become a significant problem for newspapers that host comment sections. As a result, there is growing interest in using machine learning and natural language processing for (semi-) automated abusive language detection to avoid manual comment moderation costs or having to shut down comment sections altogether. However, much of the past work on abusive language detection assumes that classifiers operate in a static language environment, despite language and news being in a state of constant flux. In this paper, we show using a new German newspaper comments dataset that the classifiers trained with naive ML techniques like a random-test train split will underperform on future data, and that a time stratified evaluation split is more appropriate. We also show that classifier performance rapidly degrades when evaluated on data from a different period than the training data. Our findings suggest that it is necessary to consider the temporal dynamics of language when developing an abusive language detection system or risk deploying a model that will quickly become defunct.
翻译:网上仇恨的蔓延已成为主办评论部分的报纸的一个严重问题。 因此,人们越来越有兴趣使用机器学习和自然语言处理来进行(半自动的)自动滥用语言检测,以避免人工评论温和成本,或不得不完全关闭评论部分。然而,过去关于滥用语言检测的大量工作假设,分类人员在静态的语言环境中运作,尽管语言和新闻处于不断变动的状态。 在本文中,我们用德国报纸的新评论数据集显示,受过天真的ML技术培训的分类人员,如随机测试列车分裂,将在未来数据方面表现不佳,而时间分层的评估则更为合适。我们还表明,在对数据进行评估时,分类人员的表现在与培训数据不同的时期迅速下降。 我们的研究结果表明,在开发滥用语言检测系统时,有必要考虑语言的时间动态,或者在部署将很快失效的模式时,需要考虑语言的时间动态。