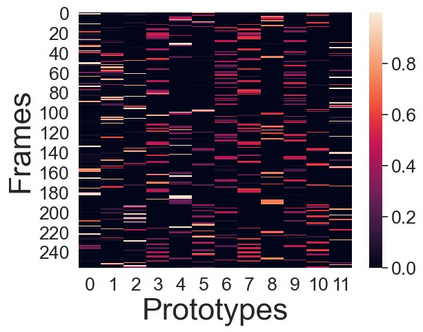
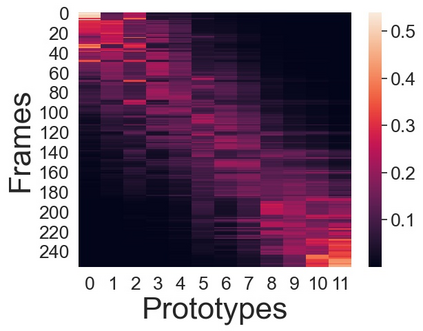
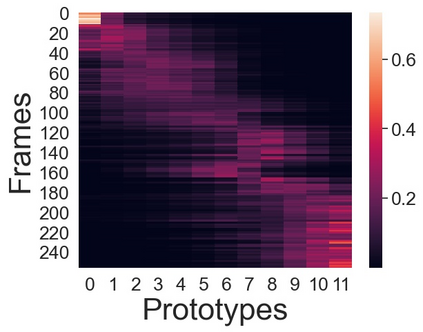
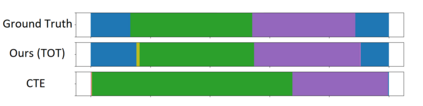
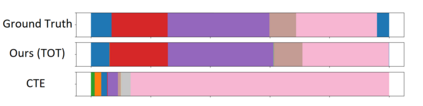
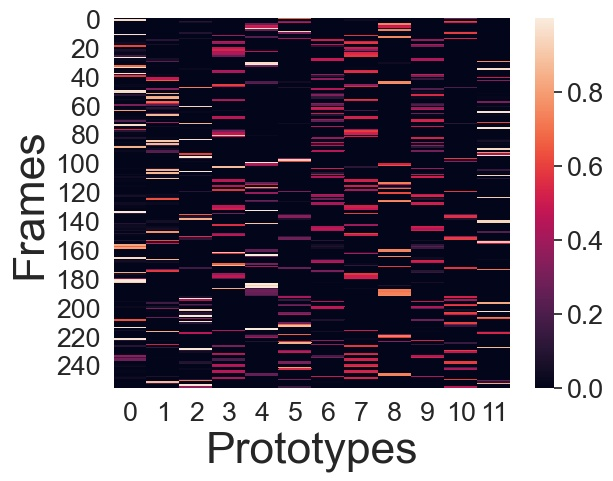
We present a novel approach for unsupervised activity segmentation, which uses video frame clustering as a pretext task and simultaneously performs representation learning and online clustering. This is in contrast with prior works where representation learning and online clustering are often performed sequentially. We leverage temporal information in videos by employing temporal optimal transport and temporal coherence loss. In particular, we incorporate a temporal regularization term into the standard optimal transport module, which preserves the temporal order of the activity, yielding the temporal optimal transport module for computing pseudo-label cluster assignments. Next, the temporal coherence loss encourages neighboring video frames to be mapped to nearby points while distant video frames are mapped to farther away points in the embedding space. The combination of these two components results in effective representations for unsupervised activity segmentation. Furthermore, previous methods require storing learned features for the entire dataset before clustering them in an offline manner, whereas our approach processes one mini-batch at a time in an online manner. Extensive evaluations on three public datasets, i.e. 50-Salads, YouTube Instructions, and Breakfast, and our dataset, i.e., Desktop Assembly, show that our approach performs on par or better than previous methods for unsupervised activity segmentation, despite having significantly less memory constraints.
翻译:我们为不受监督的活动分类提供了一种新颖的活动分类方法,即将视频框架分组用作借口,同时进行代表学习和在线分类。这与以往常常按顺序进行代表学习和在线分组的工作形成对照。我们在视频中利用时间信息,采用时间最佳交通方式和时间一致性损失。特别是,我们在标准的最佳运输模块中纳入一个时间正规化术语,以保持活动的时间顺序,为计算假标签集群任务生成一个时间最佳运输模块。接着,时间一致性损失鼓励将相邻视频框架映射到附近地点,而远处的视频框架则被绘制到更远的嵌入空间。这两个组成部分的结合导致有效展示未受监督的活动分类。此外,以往的方法要求在将整个数据集以离线方式组合之前,先将其存储学到的特征,而我们的方法则以在线方式处理一个小型组合,对三个公共数据集进行广泛的评价,即50-萨拉德、YouTube指令和早餐,以及我们的数据设置,即桌面大会,显示我们尽管以往的记忆度比以往的活动要好,但我们的记忆度比以往的缩略度要低得多。