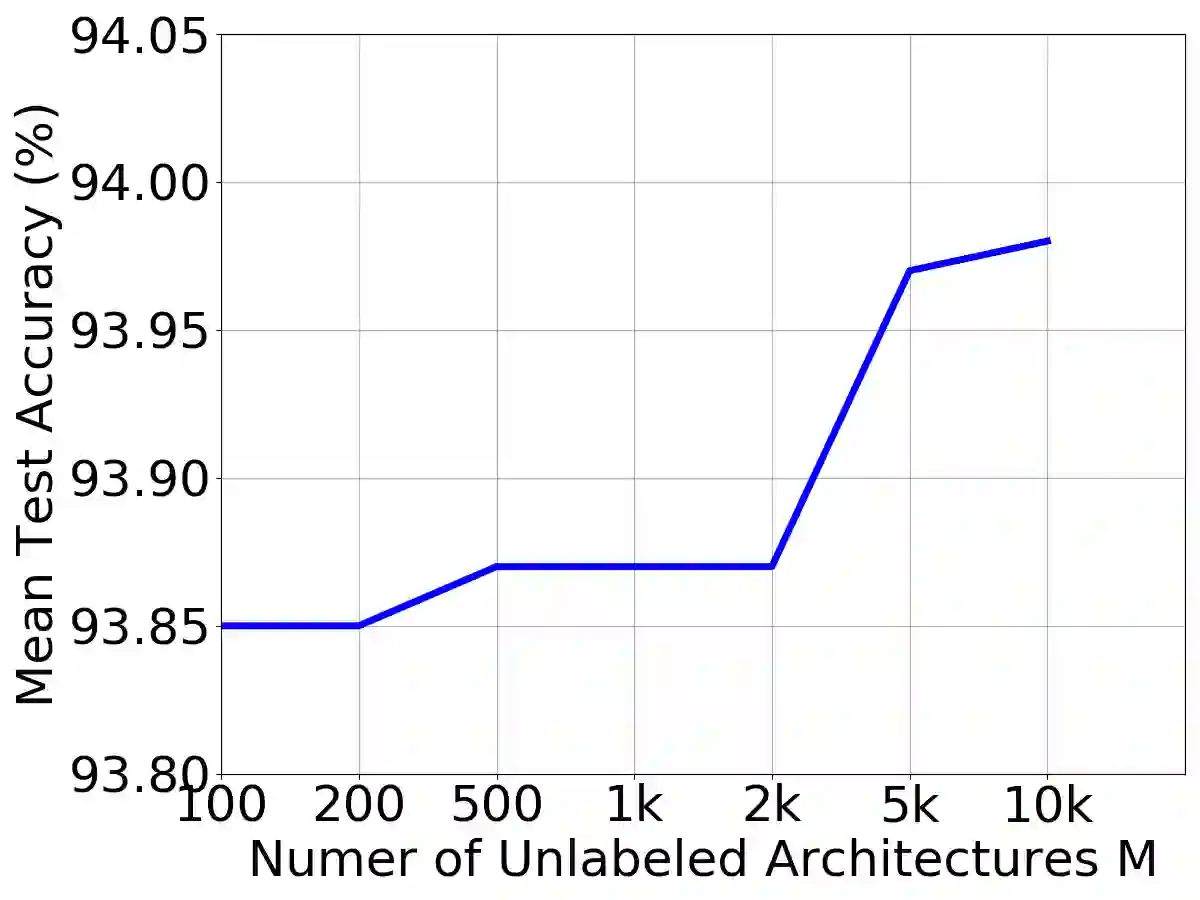
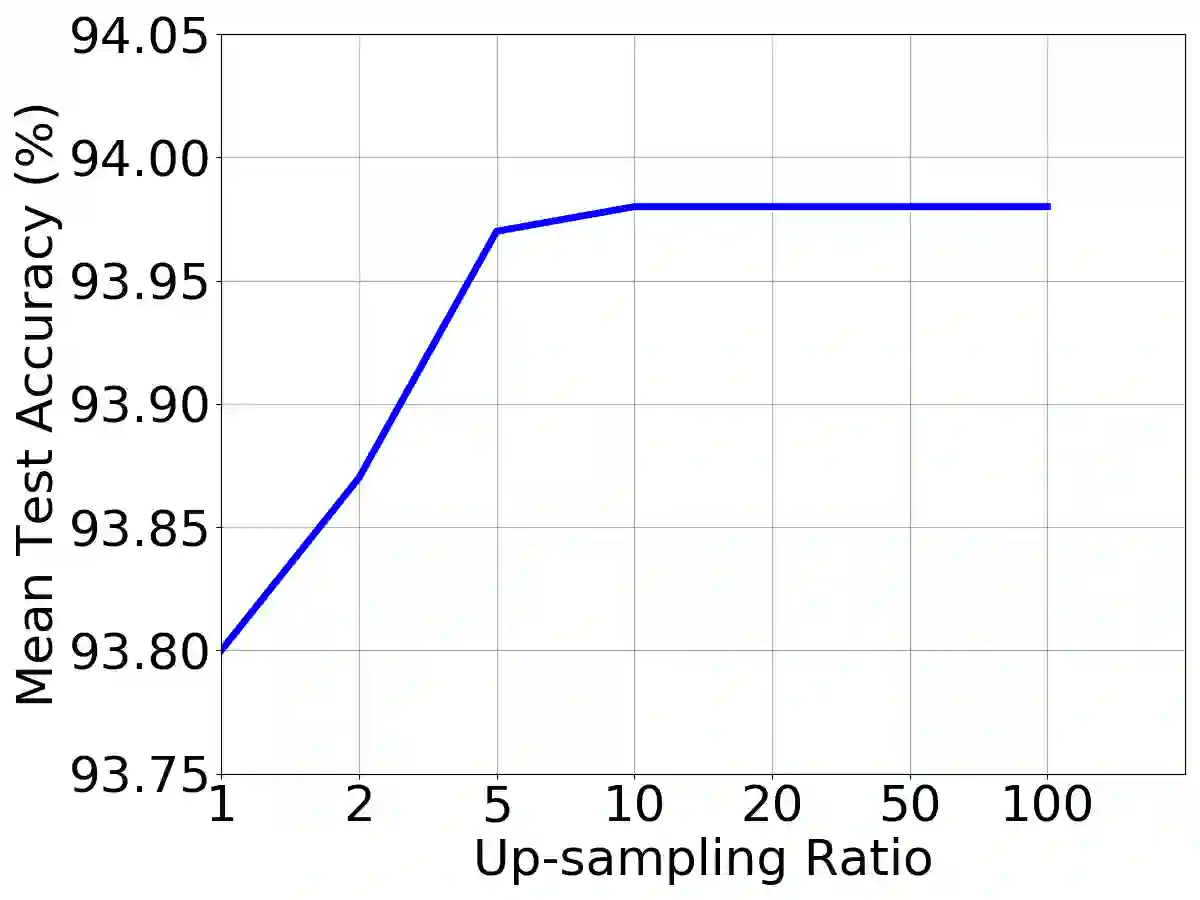
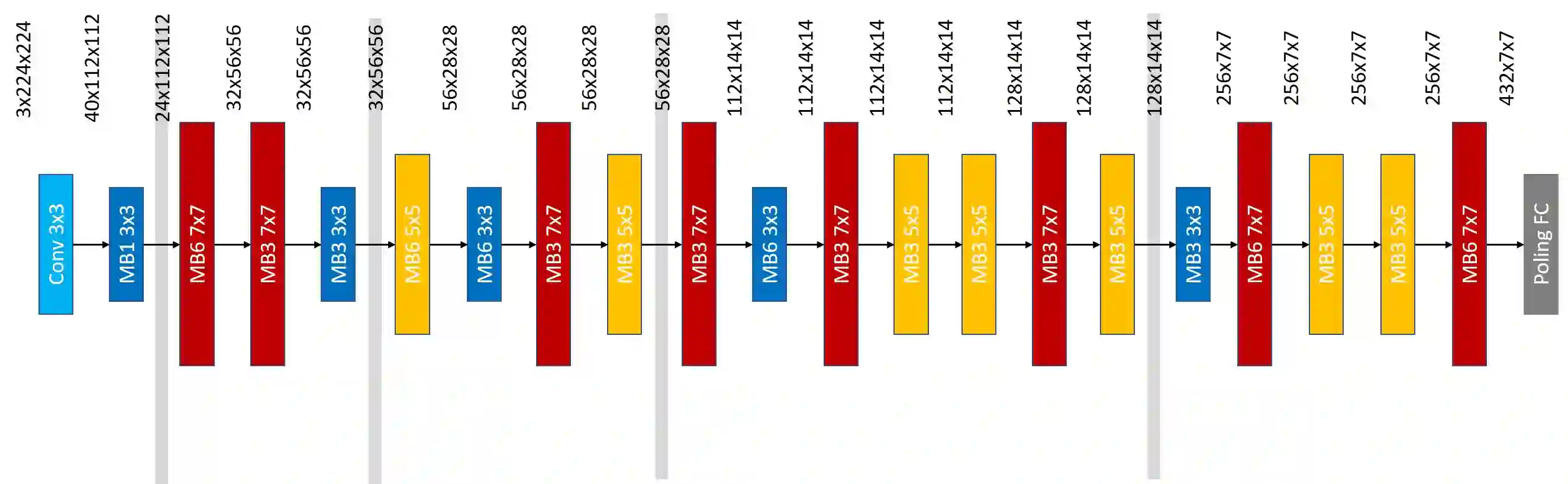
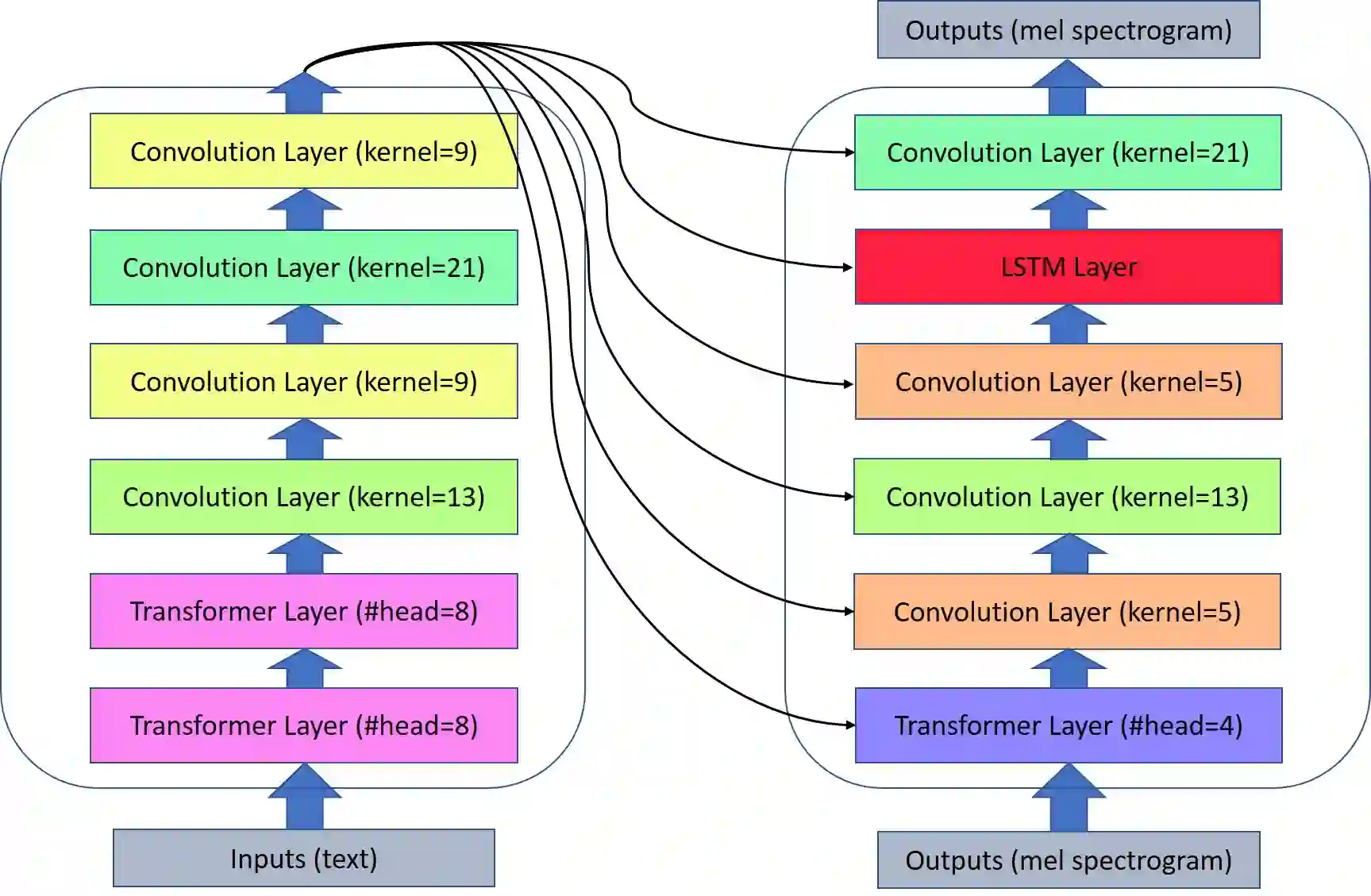
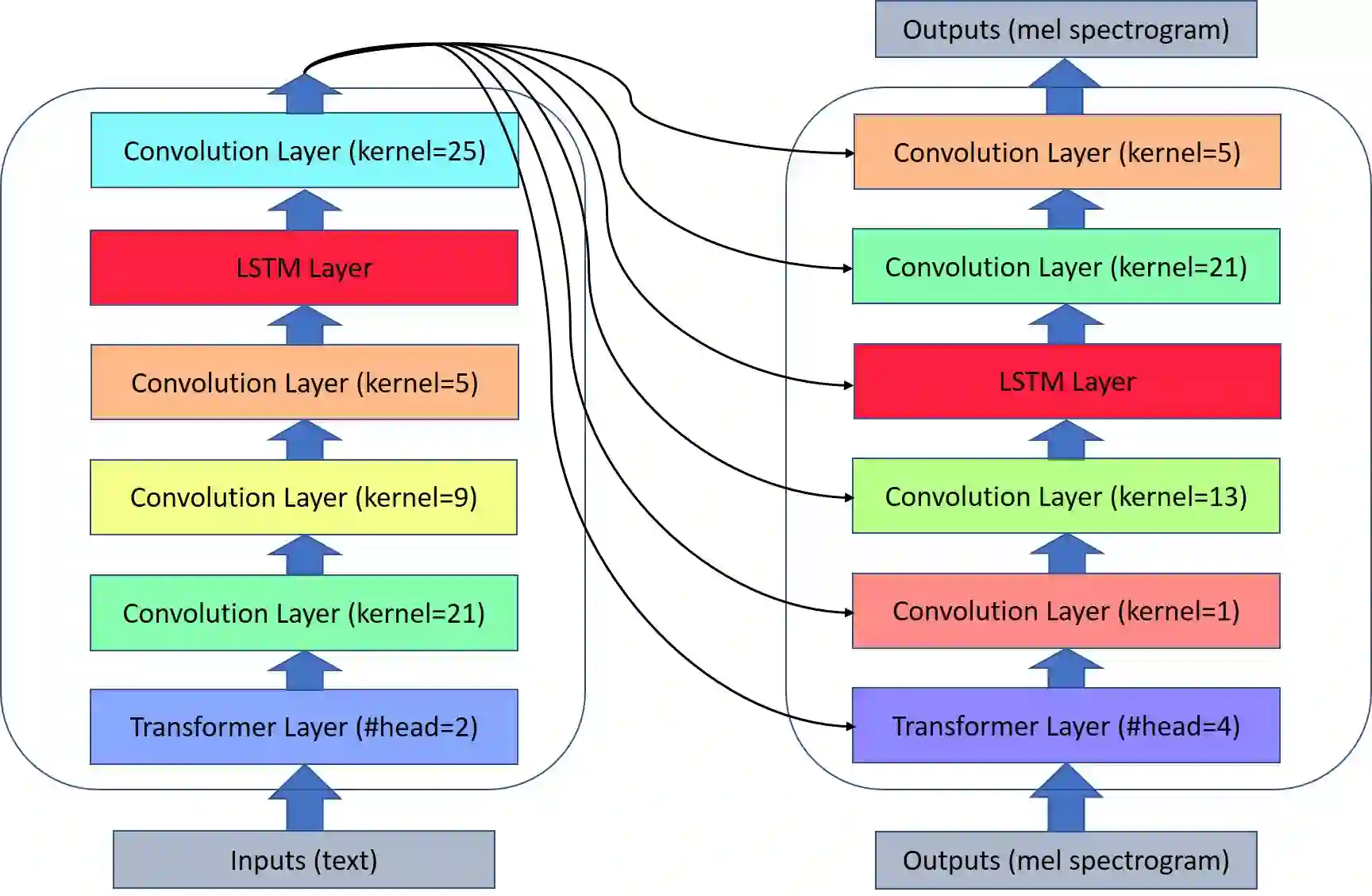
Neural architecture search (NAS) relies on a good controller to generate better architectures or predict the accuracy of given architectures. However, training the controller requires both abundant and high-quality pairs of architectures and their accuracy, while it is costly to evaluate an architecture and obtain its accuracy. In this paper, we propose \emph{SemiNAS}, a semi-supervised NAS approach that leverages numerous unlabeled architectures~(without evaluation and thus nearly no cost) to improve the controller. Specifically, SemiNAS 1) trains an initial controller with a small set of architecture-accuracy data pairs; 2) uses the trained controller to predict the accuracy of large amount of architectures~(without evaluation); and 3) adds the generated data pairs to the original data to further improve the controller. SemiNAS has two advantages: 1) It reduces the computational cost under the same accuracy guarantee. 2) It achieves higher accuracy under the same computational cost. On NASBench-101 benchmark dataset, it discovers a top 0.01% architecture after evaluating roughly 300 architectures, with only 1/7 computational cost compared with regularized evolution and gradient-based methods. On ImageNet, it achieves 24.2% top-1 error rate (under the mobile setting) using 4 GPU-days for search. We further apply it to LJSpeech text to speech task and it achieves 97% intelligibility rate in the low-resource setting and 15% test error rate in the robustness setting, with 9%, 7% improvements over the baseline respectively. Our code is available at https://github.com/renqianluo/SemiNAS.
翻译:神经架构搜索(NAS) 依靠一个良好的控制器来生成更好的架构或预测给定架构的准确性。 然而, 培训控制器需要丰富和高质量的建筑配对及其准确性, 而评估一个架构并获得其准确性的成本是昂贵的。 在本文中, 我们提出 emph{SemNAS}, 这是一种半监督的NAS 方法, 利用许多未标记的架构来改进控制器。 具体地说, SemNAS 1 培训一个初始控制器, 配有一套小型的架构精密性数据配对; 2 使用训练有素的控制器来预测大量架构的准确性; (不进行评价); 和 3 将生成的数据配在原始数据中添加数据以进一步改进控制器。 1) 降低同一精确保证下的计算成本。 2 在 NASBS-101 基准数据集中, 在评估大约300个架构后, 它发现了一个顶级的0.01% 的架构, 仅使用1/7 计算成本, 使用常规的GS- 4Rervial 的系统测试率, 在S 上, 将它设置为最高一级/ 4 。