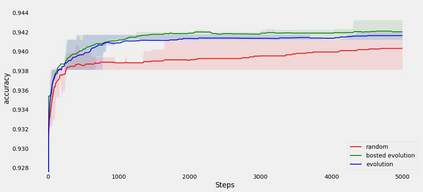
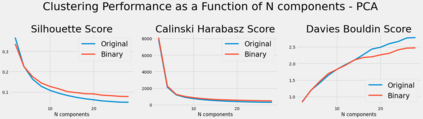
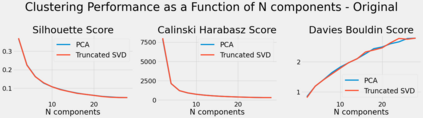
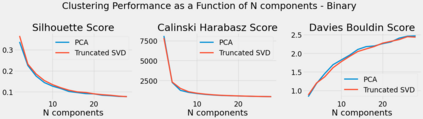
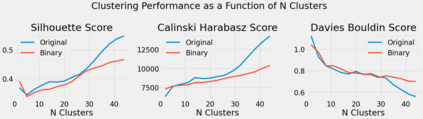
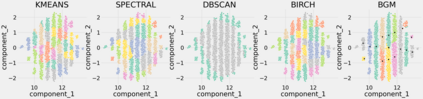
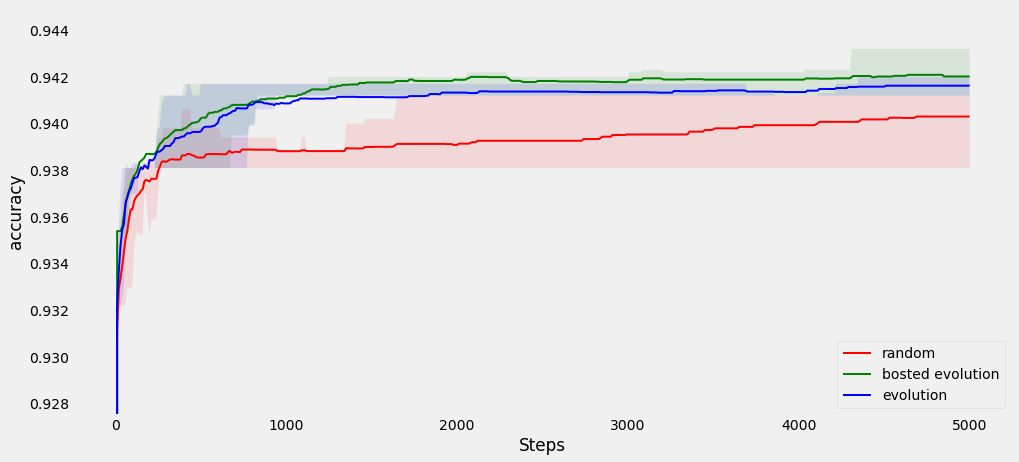
Algorithmic design in neural architecture search (NAS) has received a lot of attention, aiming to improve performance and reduce computational cost. Despite the great advances made, few authors have proposed to tailor initialization techniques for NAS. However, literature shows that a good initial set of solutions facilitate finding the optima. Therefore, in this study, we propose a data-driven technique to initialize a population-based NAS algorithm. Particularly, we proposed a two-step methodology. First, we perform a calibrated clustering analysis of the search space, and second, we extract the centroids and use them to initialize a NAS algorithm. We benchmark our proposed approach against random and Latin hypercube sampling initialization using three population-based algorithms, namely a genetic algorithm, evolutionary algorithm, and aging evolution, on CIFAR-10. More specifically, we use NAS-Bench-101 to leverage the availability of NAS benchmarks. The results show that compared to random and Latin hypercube sampling, the proposed initialization technique enables achieving significant long-term improvements for two of the search baselines, and sometimes in various search scenarios (various training budgets). Moreover, we analyze the distributions of solutions obtained and find that that the population provided by the data-driven initialization technique enables retrieving local optima (maxima) of high fitness and similar configurations.
翻译:神经结构搜索(NAS)的算法设计引起了人们的极大关注,目的是提高性能和降低计算成本。尽管取得了巨大进步,但很少有作者提议为NAS定制初始化技术。然而,文献表明,一套良好的初始解决方案有助于寻找opima。因此,在本研究中,我们提议了一种数据驱动技术,以启动基于人口的NAS算法。特别是,我们建议了一个两步方法。首先,我们对搜索空间进行了校准组合分析,第二,我们提取了核子并使用它们来初始化NAS算法。我们用随机和拉丁超立方取样法初始化方法对使用三种基于人口的算法,即基因算法、进化算法和CIFAR-10的老化演化方法进行了衡量。更具体地说,我们使用NAS-Bench-101来利用以人口为基础的NAS算法。结果显示,与随机和拉丁超立方体取样相比,拟议的初始化技术能够使两个搜索基线实现重大的长期改进,有时在各种搜索假设情景(各种培训预算)中,我们用三种基于本地技术的模型来进行数据配置,我们还分析了高水平技术。