
题目: Random Features for Kernel Approximation: A Survey in Algorithms, Theory, and Beyond
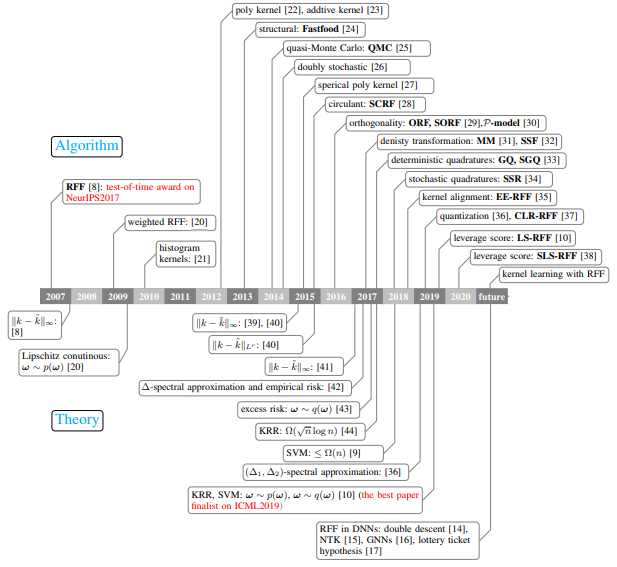
摘要: 随机特征是统计机器学习中最受欢迎的研究课题之一。相关作品获得2017年NeurIPS test-of-time奖和2019年ICML最佳论文入围。然而,关于这一主题的全面研究似乎缺失,从而导致不同的、有时相互矛盾的说法。在这项综述中,我们试图全面和系统地回顾过去十年在算法和理论方面的随机特征的工作。首先,根据具有代表性的随机特征算法的采样方法、学习过程、方差约简和训练数据的利用,总结了这些算法的基本特征、主要动机和贡献。其次,我们回顾了随机特征的理论结果,以回答关键问题:在学习估计器中,需要多少随机特征才能保证高近似质量或不损失经验风险和预期风险。第三,在多个大规模基准数据集上,综合评价了常用的基于随机特征的算法在分类和回归方面的逼近质量和预测性能。最后,通过研究随机特征与当前超参数化深度神经网络(DNNs)之间的关系,利用随机特征分析超参数化网络,以及现有理论结果的差距,将随机特征与当前超参数化深度神经网络(DNNs)联系起来。因此,这项综述可以作为一个温和的使用指南,让从业者遵循这个主题,应用有代表性的算法,并掌握各种技术假设下的理论结果。我们认为,这项综述有助于促进对这一主题正在进行的问题的讨论,特别是,它阐明了有前途的研究方向。
成为VIP会员查看完整内容
相关内容

专知会员服务
58+阅读 · 2020年5月21日
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
148+阅读 · 2019年12月28日
专知会员服务
46+阅读 · 2019年11月15日

相关VIP内容
专知会员服务
58+阅读 · 2020年5月21日
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
148+阅读 · 2019年12月28日
专知会员服务
46+阅读 · 2019年11月15日
相关资讯
相关论文