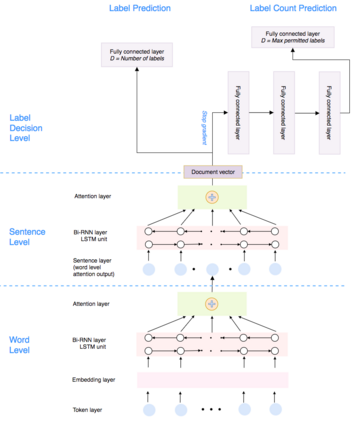
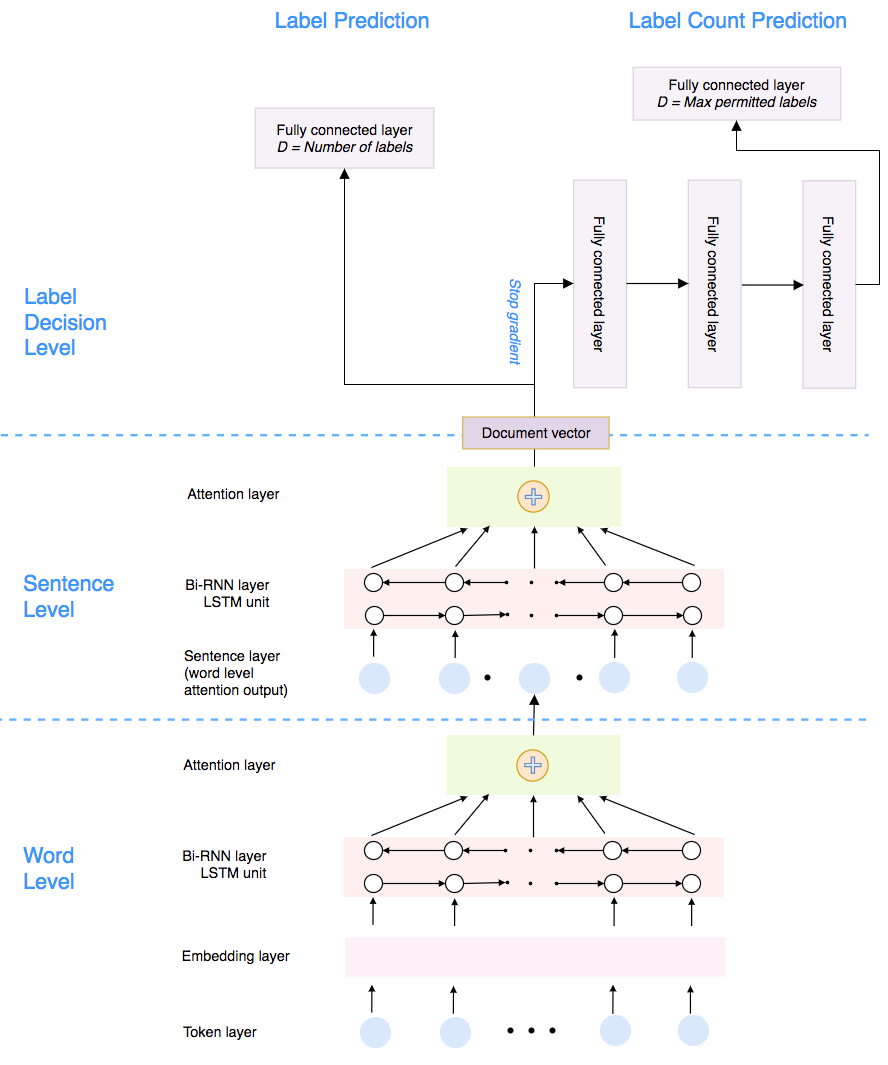
In multi-label text classification, each textual document can be assigned with one or more labels. Due to this nature, the multi-label text classification task is often considered to be more challenging compared to the binary or multi-class text classification problems. As an important task with broad applications in biomedicine such as assigning diagnosis codes, a number of different computational methods (e.g. training and combining binary classifiers for each label) have been proposed in recent years. However, many suffered from modest accuracy and efficiency, with only limited success in practical use. We propose ML-Net, a novel deep learning framework, for multi-label classification of biomedical texts. As an end-to-end system, ML-Net combines a label prediction network with an automated label count prediction mechanism to output an optimal set of labels by leveraging both predicted confidence score of each label and the contextual information in the target document. We evaluate ML-Net on three independent, publicly-available corpora in two kinds of text genres: biomedical literature and clinical notes. For evaluation, example-based measures such as precision, recall and f-measure are used. ML-Net is compared with several competitive machine learning baseline models. Our benchmarking results show that ML-Net compares favorably to the state-of-the-art methods in multi-label classification of biomedical texts. ML-NET is also shown to be robust when evaluated on different text genres in biomedicine. Unlike traditional machine learning methods, ML-Net does not require human efforts in feature engineering and is highly efficient and scalable approach to tasks with a large set of labels (no need to build individual classifiers for each separate label). Finally, ML-NET is able to dynamically estimate the label count based on the document context in a more systematic and accurate manner.
翻译:在多标签文本分类中,每个文本文档都可以指定一个或多个标签。由于这种性质,多标签文本分类任务通常被认为比二进制或多级文本分类问题更具挑战性。作为生物医学广泛应用的重要任务,例如分配诊断代码,近年来提出了若干不同的计算方法(例如,培训和结合每个标签的二进制分类方法)。然而,许多文件的准确性和效率都很低,实际使用的成功程度有限。我们提议ML-Net,这是一个新的深入学习框架,用于生物医学文本的多标签分类。作为一个端对端系统,ML-Net将标签预测网络与自动标签计数预测机制相结合,以产生一套最佳的标签,办法是利用每个标签的预测信任度和目标文件中的背景资料。我们用三种独立、公开可得的文本组合进行评价:生物医学文献和临床标签任务。评价,例如基于精度、回顾和F-计量的生物医学文本分类方法,在高端至端的服务器上,ML-Net-网络工作需要用一种竞争性的基线方法来进行对比。ML-Net-al-al-al-al-lax mal-lax mna lax lax lax a lax lax lax mal lax lax lax lax lax lax lax lax lax lax lax lax mal dal lax laxal lax laxal maxal madal laxal 。在高的计算方法中,要用一种可进行一项可比较。Mdal lax