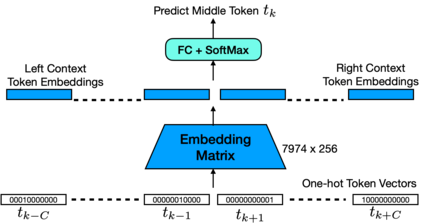
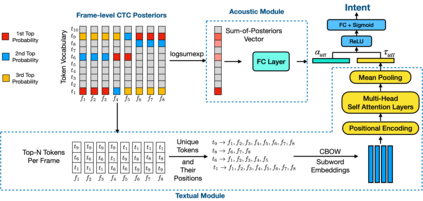
Accurate prediction of the user intent to interact with a voice assistant (VA) on a device (e.g. on the phone) is critical for achieving naturalistic, engaging, and privacy-centric interactions with the VA. To this end, we present a novel approach to predict the user's intent (the user speaking to the device or not) directly from acoustic and textual information encoded at subword tokens which are obtained via an end-to-end ASR model. Modeling directly the subword tokens, compared to modeling of the phonemes and/or full words, has at least two advantages: (i) it provides a unique vocabulary representation, where each token has a semantic meaning, in contrast to the phoneme-level representations, (ii) each subword token has a reusable "sub"-word acoustic pattern (that can be used to construct multiple full words), resulting in a largely reduced vocabulary space than of the full words. To learn the subword representations for the audio-to-intent classification, we extract: (i) acoustic information from an E2E-ASR model, which provides frame-level CTC posterior probabilities for the subword tokens, and (ii) textual information from a pre-trained continuous bag-of-words model capturing the semantic meaning of the subword tokens. The key to our approach is the way it combines acoustic subword-level posteriors with text information using the notion of positional-encoding in order to account for multiple ASR hypotheses simultaneously. We show that our approach provides more robust and richer representations for audio-to-intent classification, and is highly accurate with correctly mitigating 93.3% of unintended user audio from invoking the smart assistant at 99% true positive rate.
翻译:对用户在设备上(例如电话上)与语音助理(VA)互动的意图作出准确的预测,对于实现自然、接触和与VA进行以隐私为中心的互动至关重要。为此,我们提出一种新颖的方法来预测用户的意图(用户对设备是否说话),直接来自通过端到端 ASR 模型获得的子词符号编码和文字信息。与模拟多种语音和/或全字相比,直接建模子词符号具有至少两个优点:(一) 它提供了独特的词汇表达方式,其中每个符号都具有语义意义,与电话级别的表达方式相比, (二) 每个子字符号都有可重复使用的“子”词声学模式,这导致词汇空间大大缩小到整个词的完整。为了学习我们从声到意向分类的子词句表达方式,我们摘录:(一) 从E2E-ASR 模型的音义表示方式,其中每个符号都有语义表达的语义含义, 与SOMA的直线级缩缩缩缩图比,我们用SOM 的音阶级排序,我们用SOM级缩缩缩缩的音阶前的亚表示。