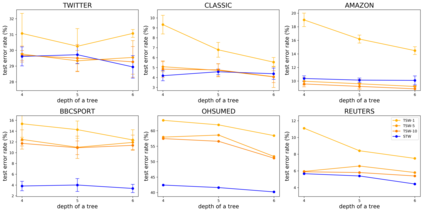
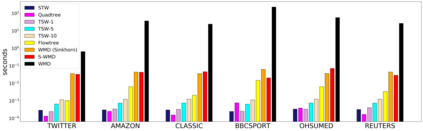
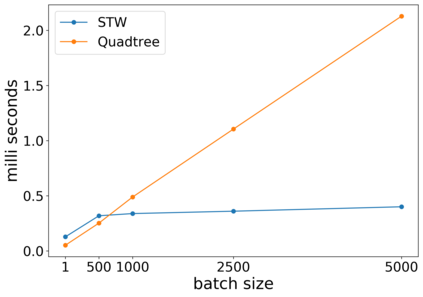
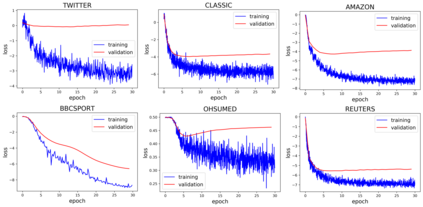
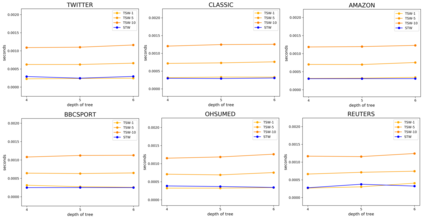
To measure the similarity of documents, the Wasserstein distance is a powerful tool, but it requires a high computational cost. Recently, for fast computation of the Wasserstein distance, methods for approximating the Wasserstein distance using a tree metric have been proposed. These tree-based methods allow fast comparisons of a large number of documents; however, they are unsupervised and do not learn task-specific distances. In this work, we propose the Supervised Tree-Wasserstein (STW) distance, a fast, supervised metric learning method based on the tree metric. Specifically, we rewrite the Wasserstein distance on the tree metric by the parent-child relationships of a tree, and formulate it as a continuous optimization problem using a contrastive loss. Experimentally, we show that the STW distance can be computed fast, and improves the accuracy of document classification tasks. Furthermore, the STW distance is formulated by matrix multiplications, runs on a GPU, and is suitable for batch processing. Therefore, we show that the STW distance is extremely efficient when comparing a large number of documents.
翻译:为了测量文件的相似性,瓦森斯坦距离是一个强大的工具,但它需要很高的计算成本。最近,为了快速计算瓦森斯坦距离,提出了使用树度测量仪来接近瓦森斯坦距离的方法。这些以树为基础的方法可以快速比较大量文件;然而,它们不受监督,不学习特定任务距离。在这项工作中,我们建议采用以树度量为基础的监督树-瓦塞尔斯坦(STW)距离(STW),这是一种快速的、受监督的计量学习方法。具体地说,我们用树的父子关系在树测量仪上重写瓦西斯坦距离,并用对比性损失来把它设计成一个持续优化的问题。我们实验性地表明,STW距离可以快速计算,提高文件分类任务的准确性。此外,STW距离是由矩阵乘法设计的,在GPU上运行,适合批量处理。因此,我们表明,在比较大量文件时,STW距离非常高效。