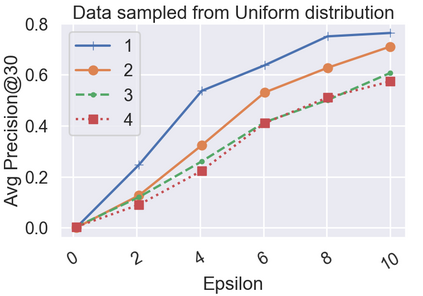
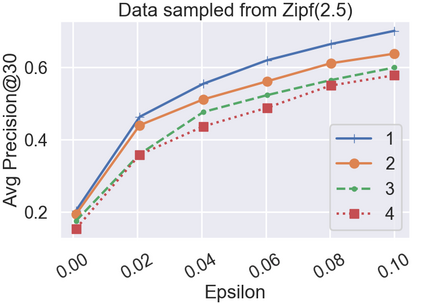
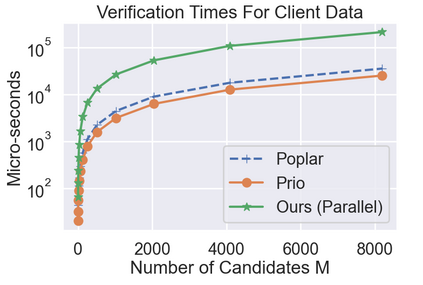
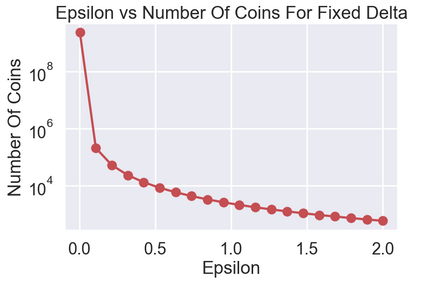
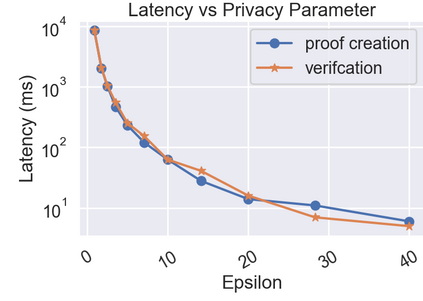
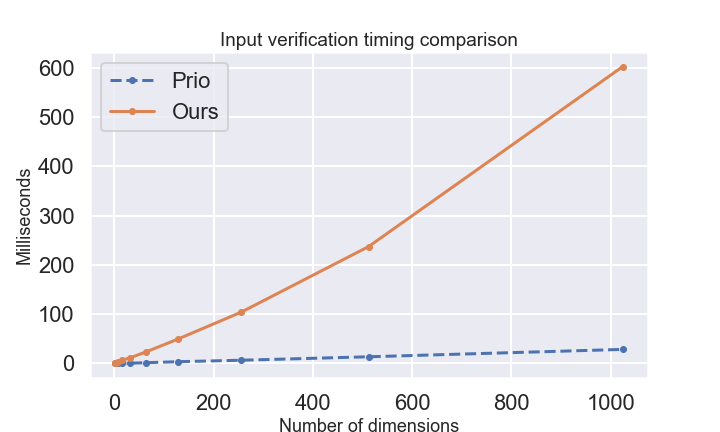
Differential Privacy (DP) is often presented as a strong privacy-enhancing technology with broad applicability and advocated as a de-facto standard for releasing aggregate statistics on sensitive data. However, in many embodiments, DP introduces a new attack surface: a malicious entity entrusted with releasing statistics could manipulate the results and use the randomness of DP as a convenient smokescreen to mask its nefariousness. Since revealing the random noise would obviate the purpose of introducing it, the miscreant may have a perfect alibi. To close this loophole, we introduce the idea of \textit{Verifiable Differential Privacy}, which requires the publishing entity to output a zero-knowledge proof that convinces an efficient verifier that the output is both DP and reliable. Such a definition might seem unachievable, as a verifier must validate that DP randomness was generated faithfully without learning anything about the randomness itself. We resolve this paradox by carefully mixing private and public randomness to compute verifiable DP counting queries with theoretical guarantees and show that it is also practical for real-world deployment. We also demonstrate that computational assumptions are necessary by showing a separation between information-theoretic DP and computational DP under our definition of verifiability.
翻译:差异隐私(DP)通常被描述为具有广泛适用性的强力隐私增强技术,并被提倡为释放敏感数据综合统计数据的“非字面标准”,然而,在许多化体中,DP引入了一个新的攻击面:受委托发布统计数据的恶意实体可以操纵结果,利用DP的随机性作为方便的烟幕掩盖其邪恶性。由于随机噪音的暴露将排除引入目的,错误隐蔽者可能有完美的不在犯罪现场。为了堵住这一漏洞,我们引入了“可变差异隐私”的概念,要求出版实体输出一个零知识证明,使一个有效的验证员相信产出是DP和可靠的。这样的定义可能似乎无法实现,因为核查员必须证实DP随机性是忠实产生的,而没有了解任何随机性本身。我们解决了这一矛盾,将私人和公共随机性混杂性混在一起,用理论保证来计算可核实的DP计数问题,并表明它对于现实世界部署也是实用的。我们还表明,计算假设是必要的,根据我们的信息-理论性DP和计算定义,显示在信息-理论性DP和计算上是分的。