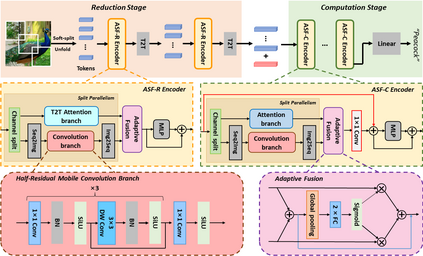
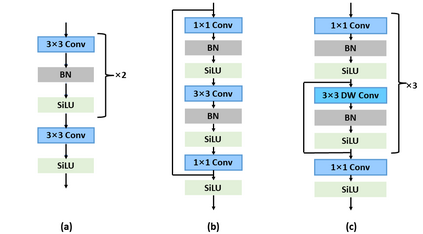
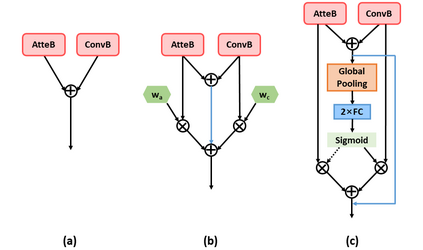
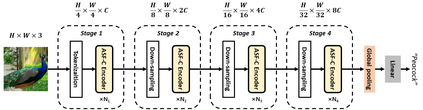
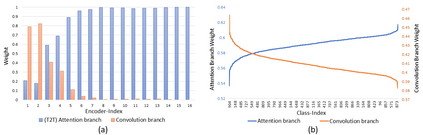
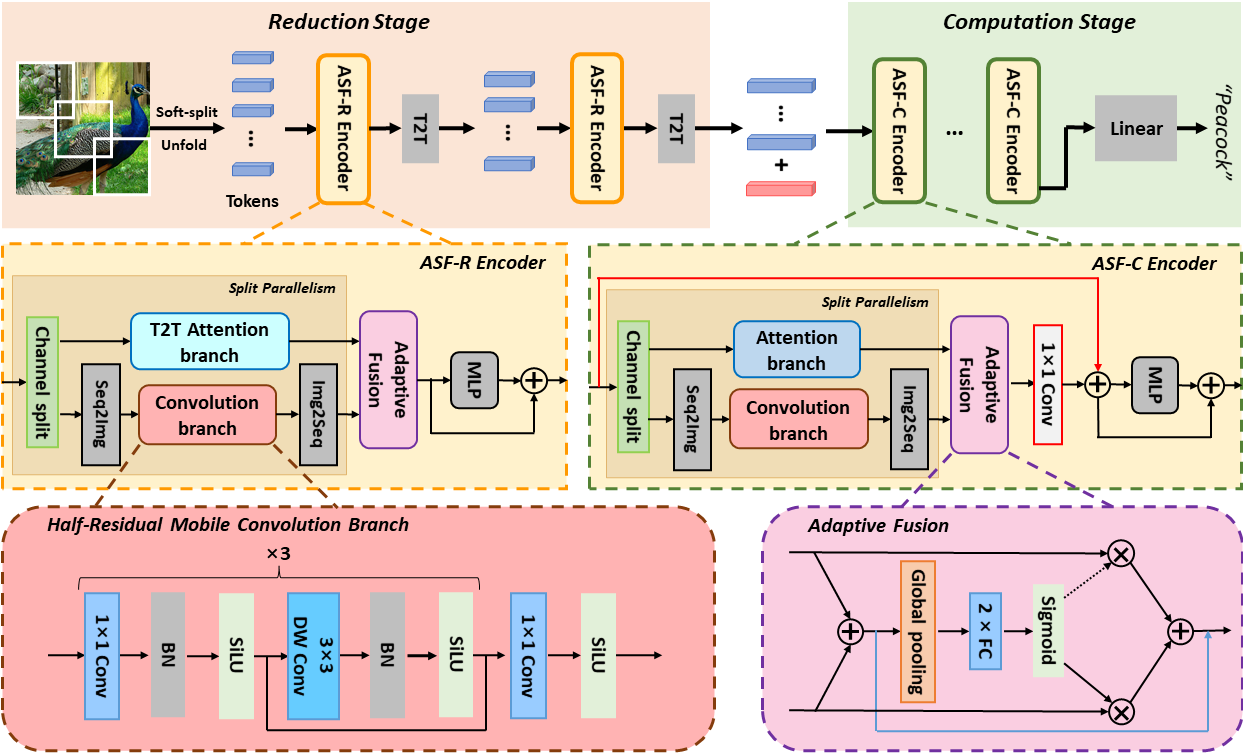
Neural networks for visual content understanding have recently evolved from convolutional ones (CNNs) to transformers. The prior (CNN) relies on small-windowed kernels to capture the regional clues, demonstrating solid local expressiveness. On the contrary, the latter (transformer) establishes long-range global connections between localities for holistic learning. Inspired by this complementary nature, there is a growing interest in designing hybrid models to best utilize each technique. Current hybrids merely replace convolutions as simple approximations of linear projection or juxtapose a convolution branch with attention, without concerning the importance of local/global modeling. To tackle this, we propose a new hybrid named Adaptive Split-Fusion Transformer (ASF-former) to treat convolutional and attention branches differently with adaptive weights. Specifically, an ASF-former encoder equally splits feature channels into half to fit dual-path inputs. Then, the outputs of dual-path are fused with weighting scalars calculated from visual cues. We also design the convolutional path compactly for efficiency concerns. Extensive experiments on standard benchmarks, such as ImageNet-1K, CIFAR-10, and CIFAR-100, show that our ASF-former outperforms its CNN, transformer counterparts, and hybrid pilots in terms of accuracy (83.9% on ImageNet-1K), under similar conditions (12.9G MACs/56.7M Params, without large-scale pre-training). The code is available at: https://github.com/szx503045266/ASF-former.
翻译:暂无翻译