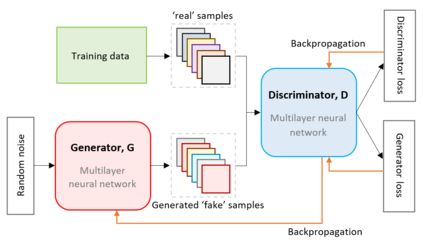
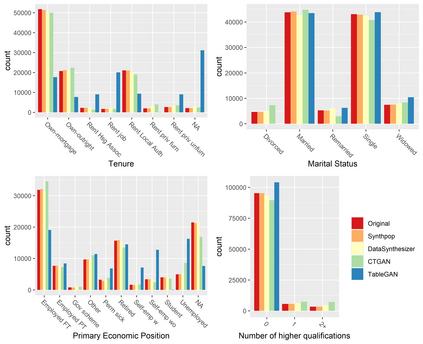
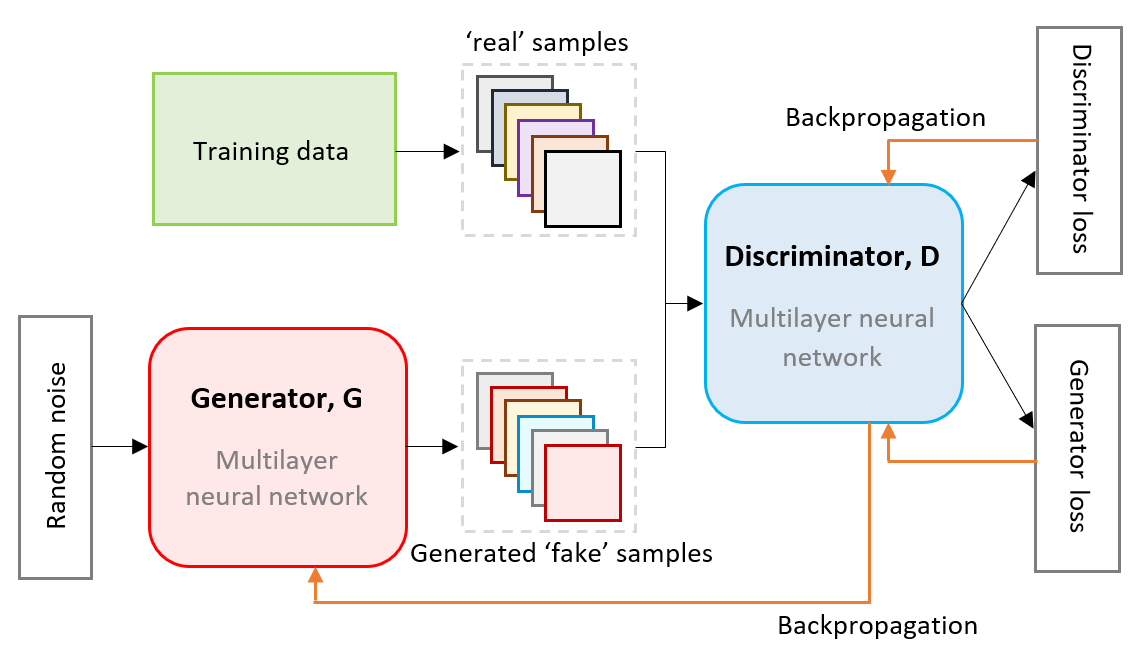
Generative Adversarial Networks (GANs) are gaining increasing attention as a means for synthesising data. So far much of this work has been applied to use cases outside of the data confidentiality domain with a common application being the production of artificial images. Here we consider the potential application of GANs for the purpose of generating synthetic census microdata. We employ a battery of utility metrics and a disclosure risk metric (the Targeted Correct Attribution Probability) to compare the data produced by tabular GANs with those produced using orthodox data synthesis methods.
翻译:作为综合数据的手段,生成反向网络(GANs)日益受到越来越多的关注,迄今为止,这项工作中的大部分应用到使用数据保密领域以外的案例,通常的应用是制作人工图像。我们在这里考虑全球网络可能被用于生成合成普查微观数据。我们使用一套通用指标和披露风险指标(定向正确归因概率),将表格式全球网络生成的数据与使用正统数据合成方法生成的数据进行比较。