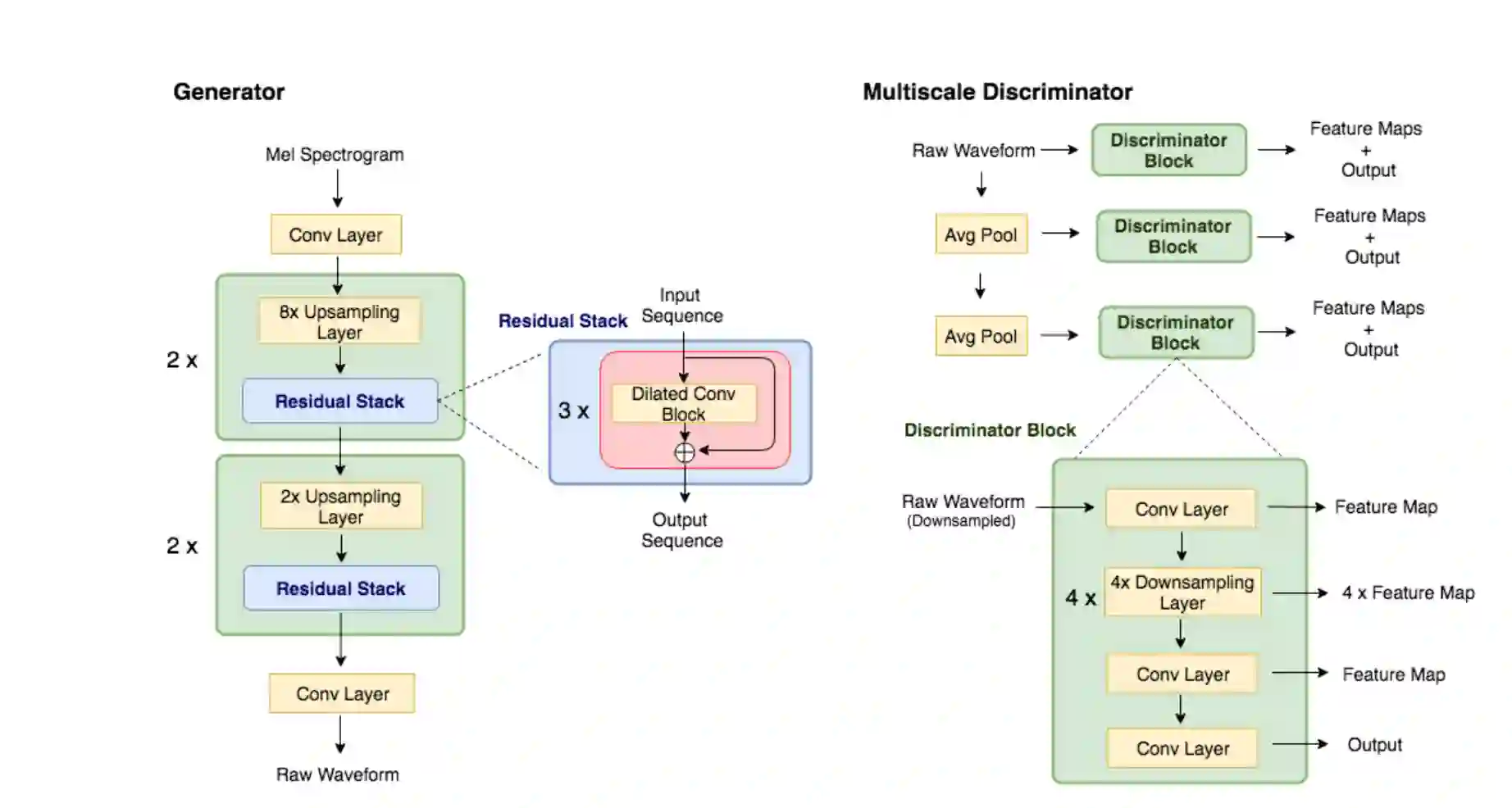
Previous works \citep{donahue2018adversarial, engel2019gansynth} have found that generating coherent raw audio waveforms with GANs is challenging. In this paper, we show that it is possible to train GANs reliably to generate high quality coherent waveforms by introducing a set of architectural changes and simple training techniques. Subjective evaluation metric (Mean Opinion Score, or MOS) shows the effectiveness of the proposed approach for high quality mel-spectrogram inversion. To establish the generality of the proposed techniques, we show qualitative results of our model in speech synthesis, music domain translation and unconditional music synthesis. We evaluate the various components of the model through ablation studies and suggest a set of guidelines to design general purpose discriminators and generators for conditional sequence synthesis tasks. Our model is non-autoregressive, fully convolutional, with significantly fewer parameters than competing models and generalizes to unseen speakers for mel-spectrogram inversion. Our pytorch implementation runs at more than 100x faster than realtime on GTX 1080Ti GPU and more than 2x faster than real-time on CPU, without any hardware specific optimization tricks. Blog post with samples and accompanying code coming soon.
翻译:之前的作品 \ citep{donahue2018 对抗性, engel2019gansynth} 发现, 与 GANs 生成一致的原始声波成形是具有挑战性的。 在本文中, 我们显示, 通过引入一系列建筑变化和简单培训技术, 可靠地培训 GANs 生成高质量一致的波形。 主观评价度量( MEan Visional C分数, 或 MOS) 显示高质量Mel- pectrocrogro 反转的拟议方法的有效性。 为了确定拟议技术的普遍性, 我们展示了在语音合成、 音乐域翻译 和 无条件的音乐合成 方面模型的质量效果。 我们通过减缩研究来评估模型的各个组成部分, 并为有条件的序列合成任务提出一套设计通用导体和生成器的指导方针。 我们的模型是非引力性、 完全革命性的, 其参数比相竞相的模型要少得多, 以及普通的演讲者对Mel- pectrographrogrogram 。 我们在GTX 1080TGPPPPPU 上比实时要快100x 。