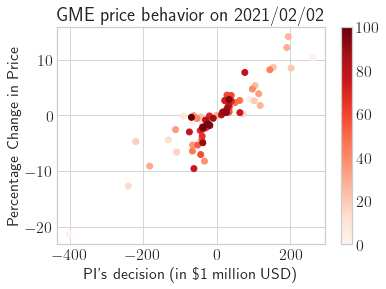
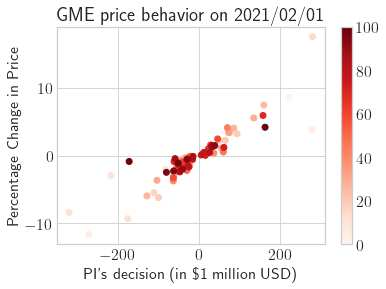
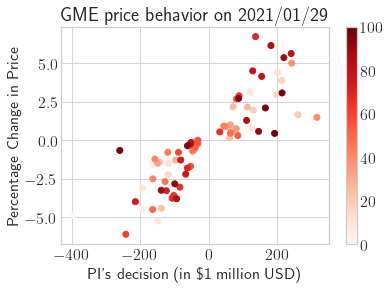
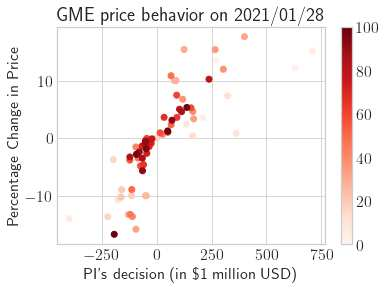
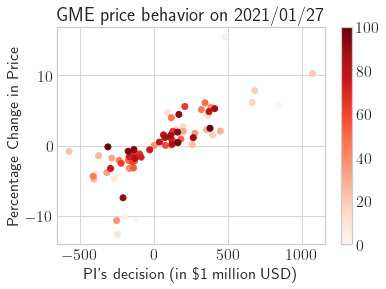
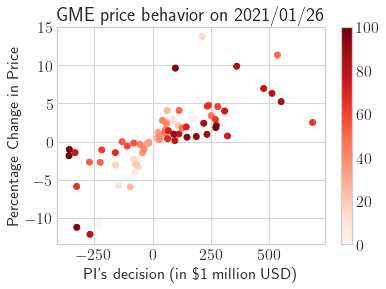
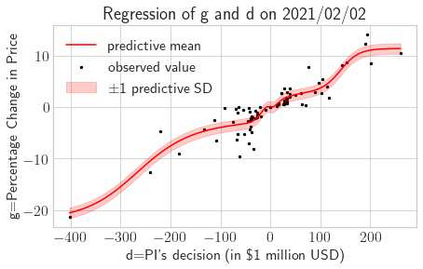
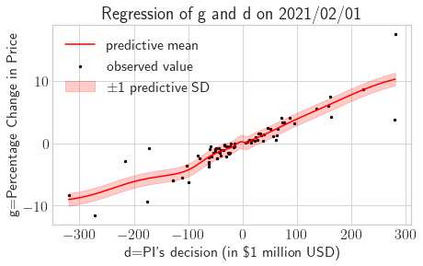
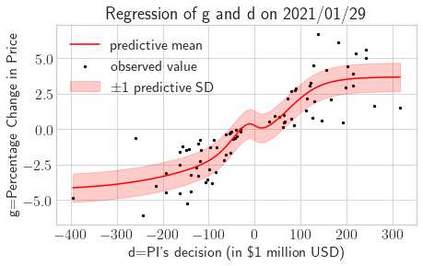
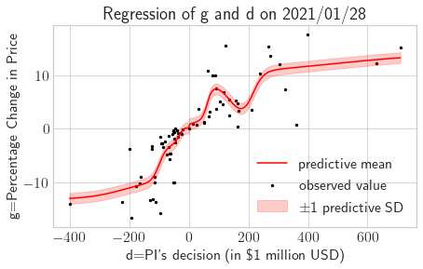
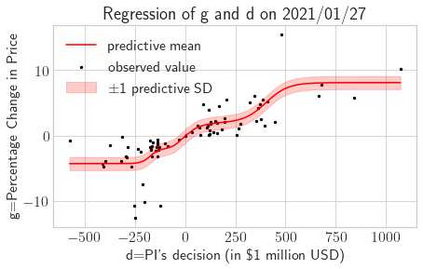
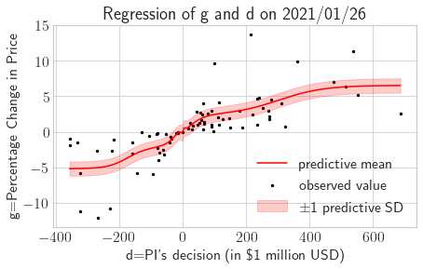
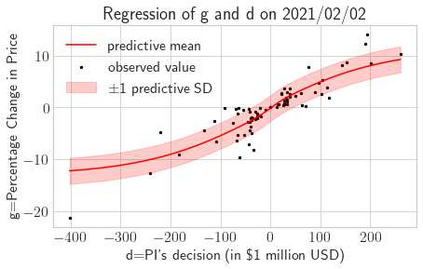
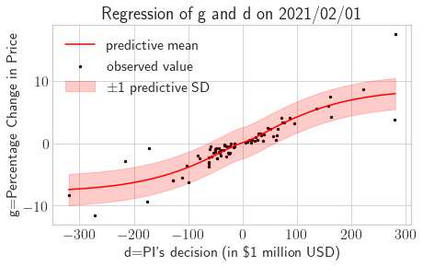
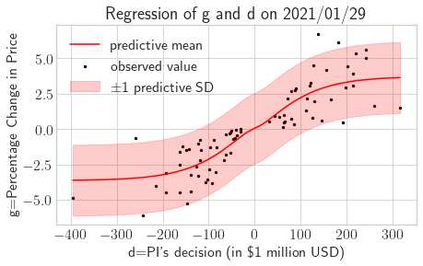
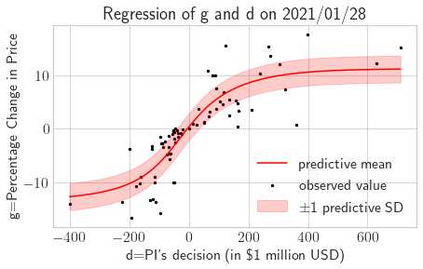
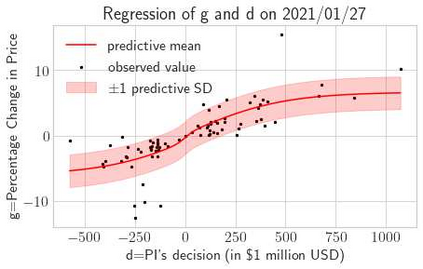
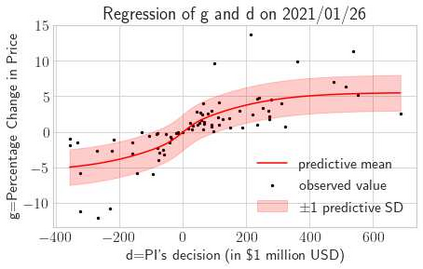
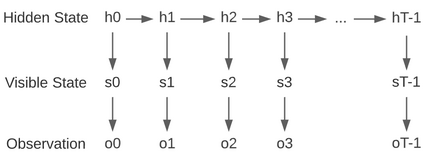
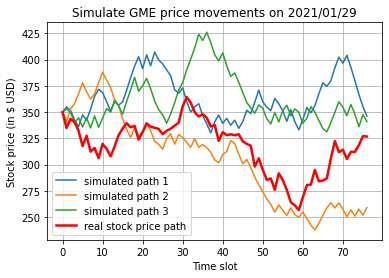
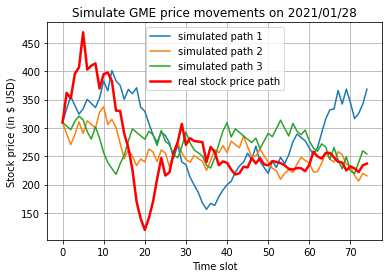
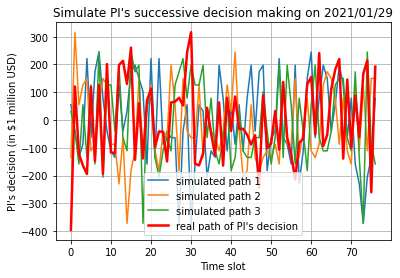
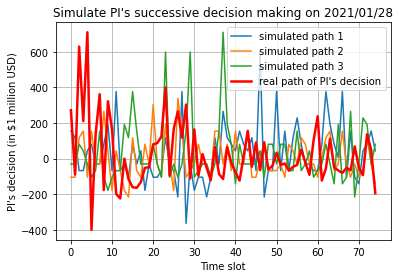
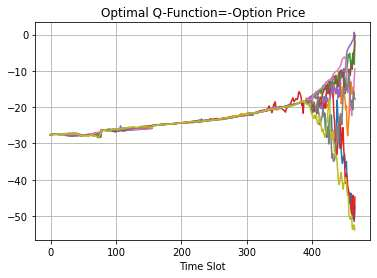
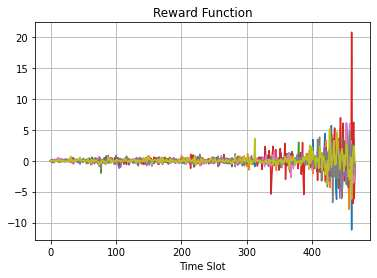
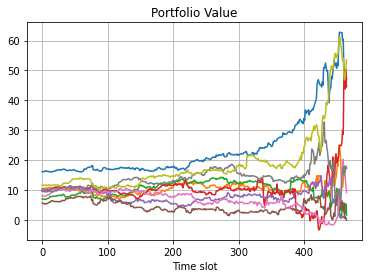
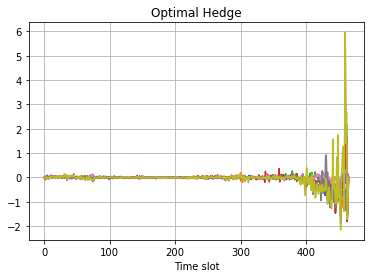
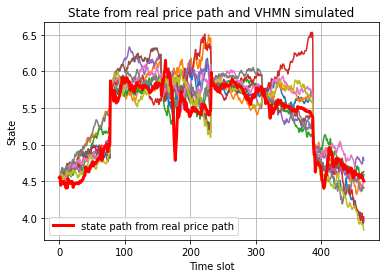
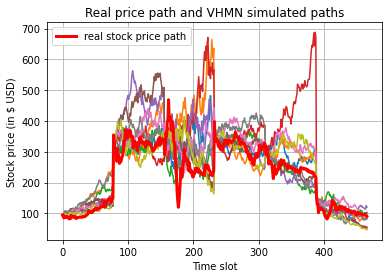
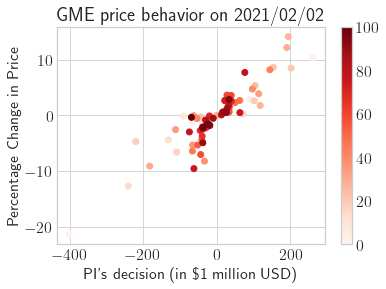
This paper presents a framework of imitating the principal investor's behavior for optimal pricing and hedging options. We construct a non-deterministic Markov decision process for modeling stock price change driven by the principal investor's decision making. However, low signal-to-noise ratio and instability that are inherent in equity markets pose challenges to determine the state transition (stock price change) after executing an action (the principal investor's decision) as well as decide an action based on current state (spot price). In order to conquer these challenges, we resort to a Bayesian deep neural network for computing the predictive distribution of the state transition led by an action. Additionally, instead of exploring a state-action relationship to formulate a policy, we seek for an episode based visible-hidden state-action relationship to probabilistically imitate the principal investor's successive decision making. Unlike conventional option pricing that employs analytical stochastic processes or utilizes time series analysis to model and sample underlying stock price movements, our algorithm simulates stock price paths by imitating the principal investor's behavior which requires no preset probability distribution and fewer predetermined parameters. Eventually the optimal option price is learned by reinforcement learning to maximize the cumulative risk-adjusted return of a dynamically hedged portfolio over simulated price paths.
翻译:本文提供了一个仿照主要投资者最佳定价和套期保值选择行为的框架。 我们为模拟主要投资者决策驱动的股票价格变化构建了一个非决定性的Markov决策程序。然而,股市固有的低信号到噪音比率和不稳定性在股市中构成了挑战,以在采取一项行动(主要投资者的决定)之后确定国家过渡(股票价格变化),并根据当前状况(现价)决定一项行动。为了克服这些挑战,我们利用贝耶斯深层神经网络来计算由一项行动引导的国家过渡的预测分布。此外,我们不探索国家行动关系来制定政策,而是寻求基于可见和隐蔽的国家行动关系,以稳妥地模仿主要投资者的连续决策。与采用分析性分析分析过程或利用时间序列分析来模拟和抽样股票价格变动的常规选择定价不同,我们的算法模拟股票价格路径,模仿主要投资者不需要预先确定概率分布和较少预定参数的行为。 最终,我们寻求基于基于可预见的风险分配和先期性参数的国家行动,我们寻求一种基于基于可视隐形的国家行动的国家-行动关系来建立基于概率关系的事件事件,寻求一种基于概率变化的州-行动关系,以概率调整投资组合,从而学习对价格进行最优化选择进行最优化的学习,从而学习对价格进行最先变现的变现的变现式的变现式选择,从而学习,学习,学习对价价价比。最后学习对价比。