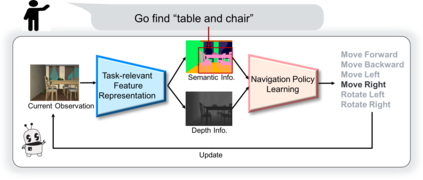
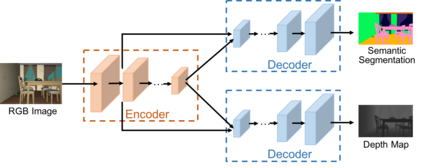
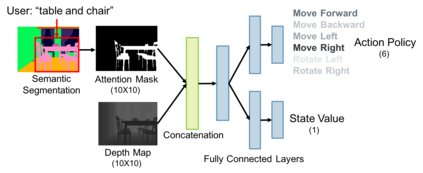
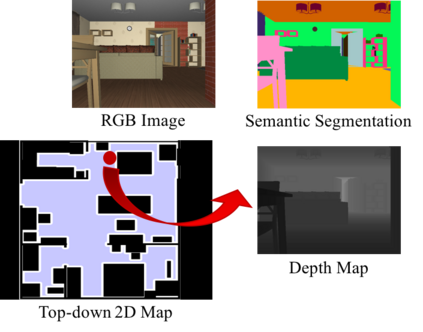
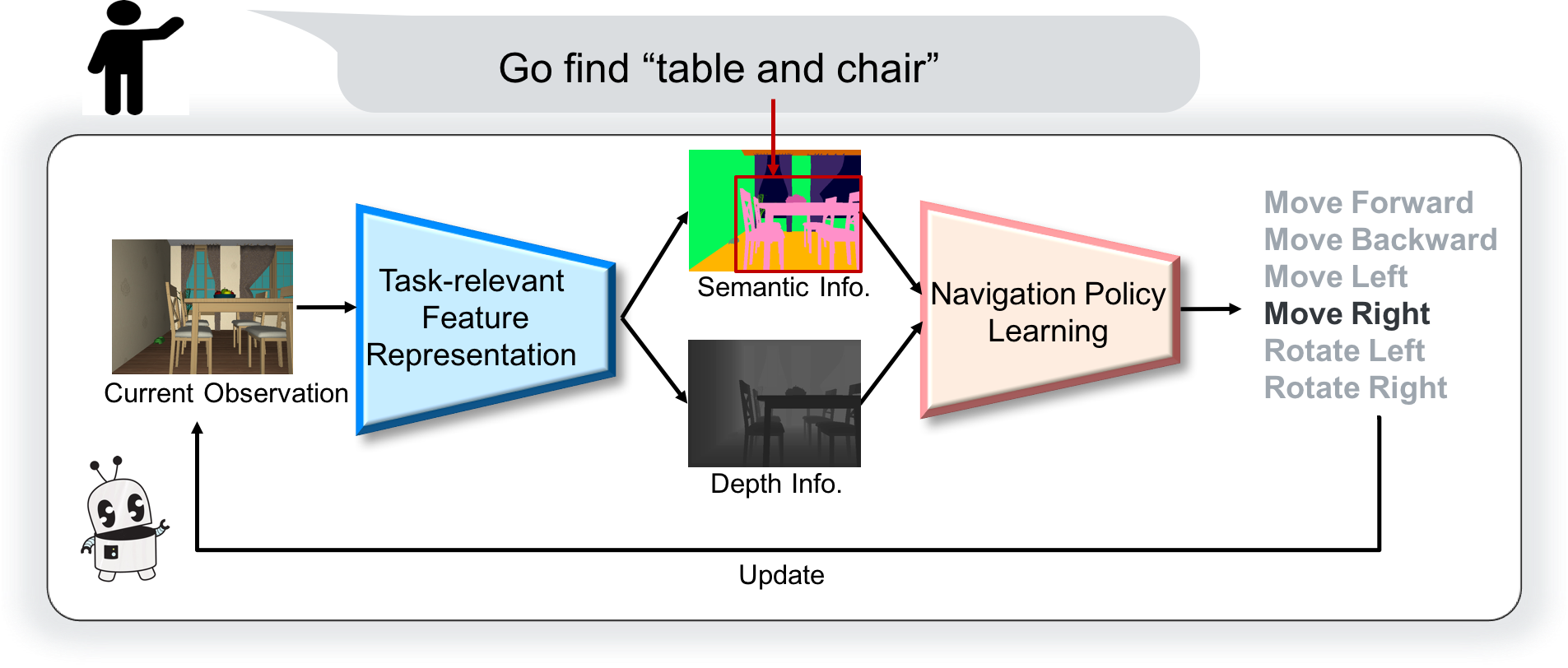
We study the problem of learning a generalizable action policy for an intelligent agent to actively approach an object of interest in an indoor environment solely from its visual inputs. While scene-driven or recognition-driven visual navigation has been widely studied, prior efforts suffer severely from the limited generalization capability. In this paper, we first argue the object searching task is environment dependent while the approaching ability is general. To learn a generalizable approaching policy, we present a novel solution dubbed as GAPLE which adopts two channels of visual features: depth and semantic segmentation, as the inputs to the policy learning module. The empirical studies conducted on the House3D dataset as well as on a physical platform in a real world scenario validate our hypothesis, and we further provide in-depth qualitative analysis.
翻译:我们研究一个问题,即如何学习一项一般可行的行动政策,使智能剂能够仅仅从其视觉投入中积极对待室内环境中感兴趣的对象。虽然对现场驱动或识别驱动的视觉导航进行了广泛研究,但先前的努力因有限的一般化能力而严重受损。在本文中,我们首先认为,物体搜索任务取决于环境,而接近能力则是一般的。为了学习一项普遍化的接近政策,我们提出了一个新颖的解决方案,称为GAPLE,它采用两种视觉特征的渠道:深度和语义分割,作为政策学习模块的投入。在House3D数据集和现实世界情景中的物理平台上进行的经验研究证实了我们的假设,我们进一步提供了深入的质量分析。