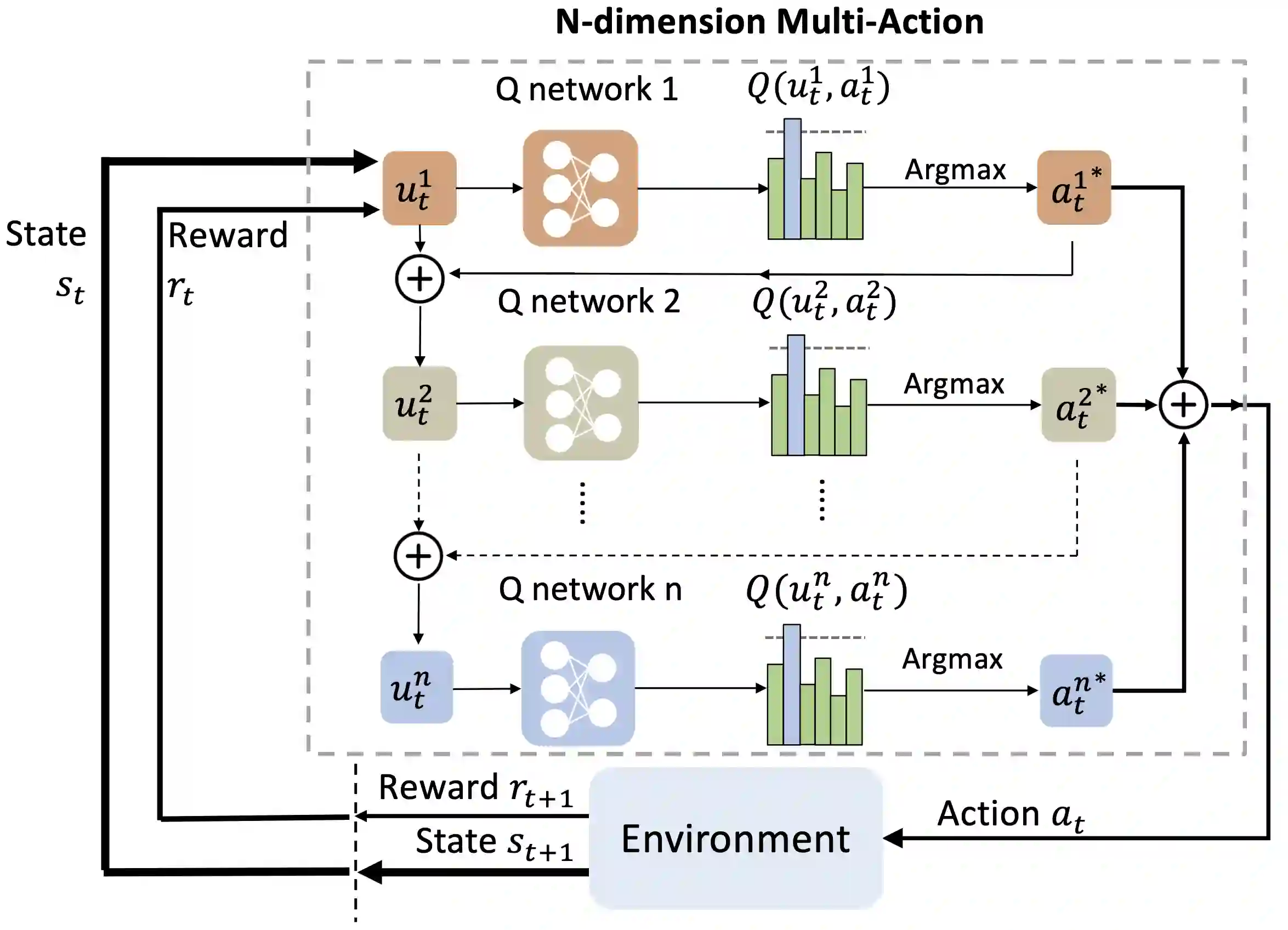
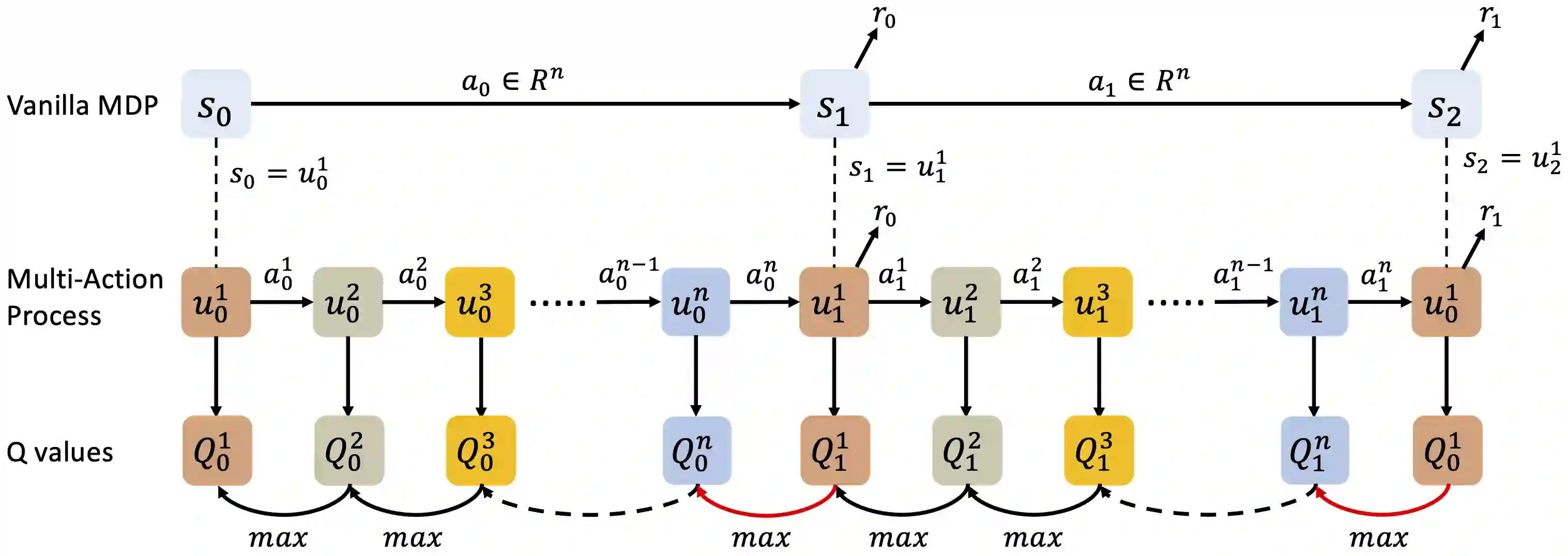
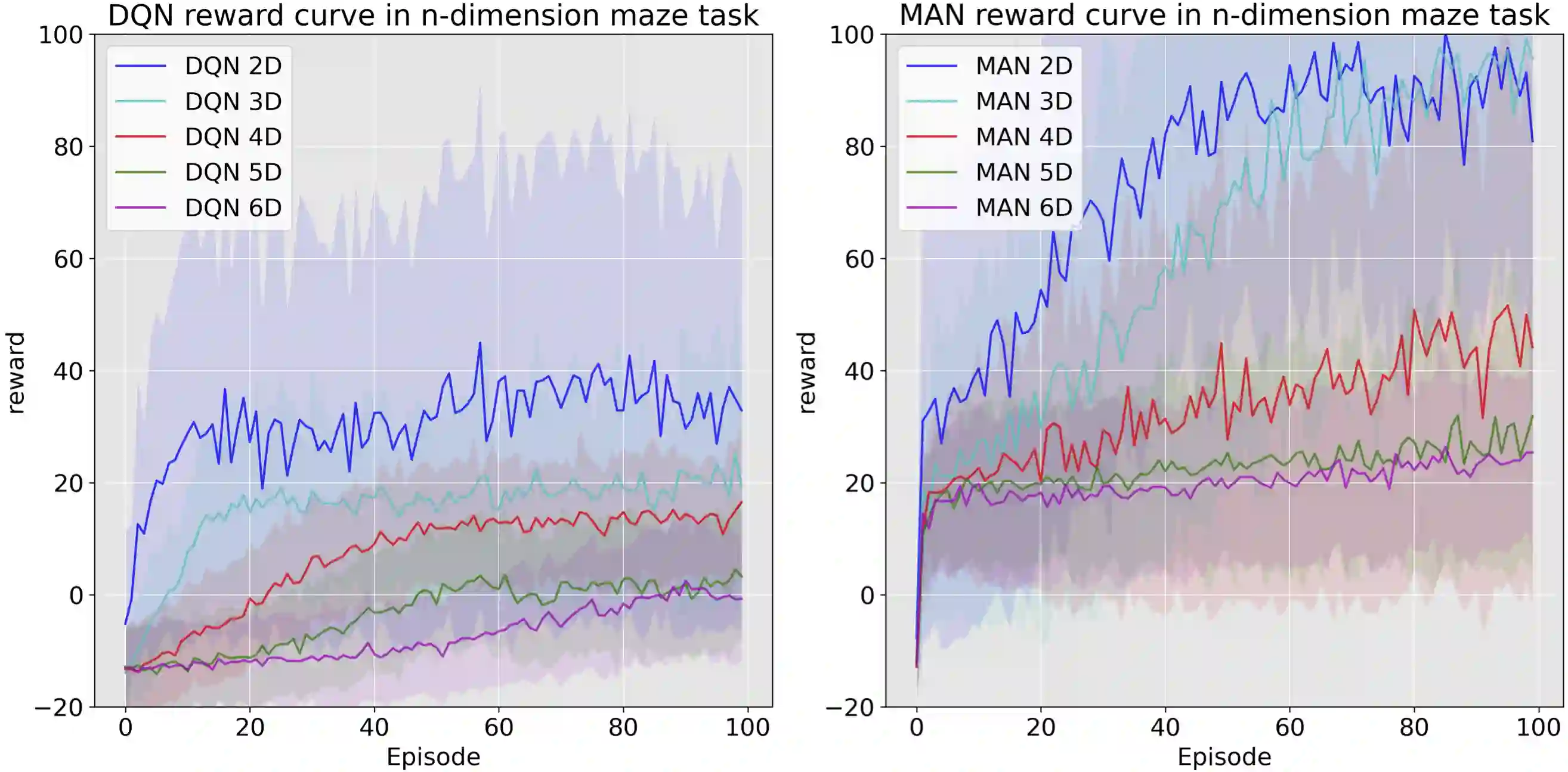
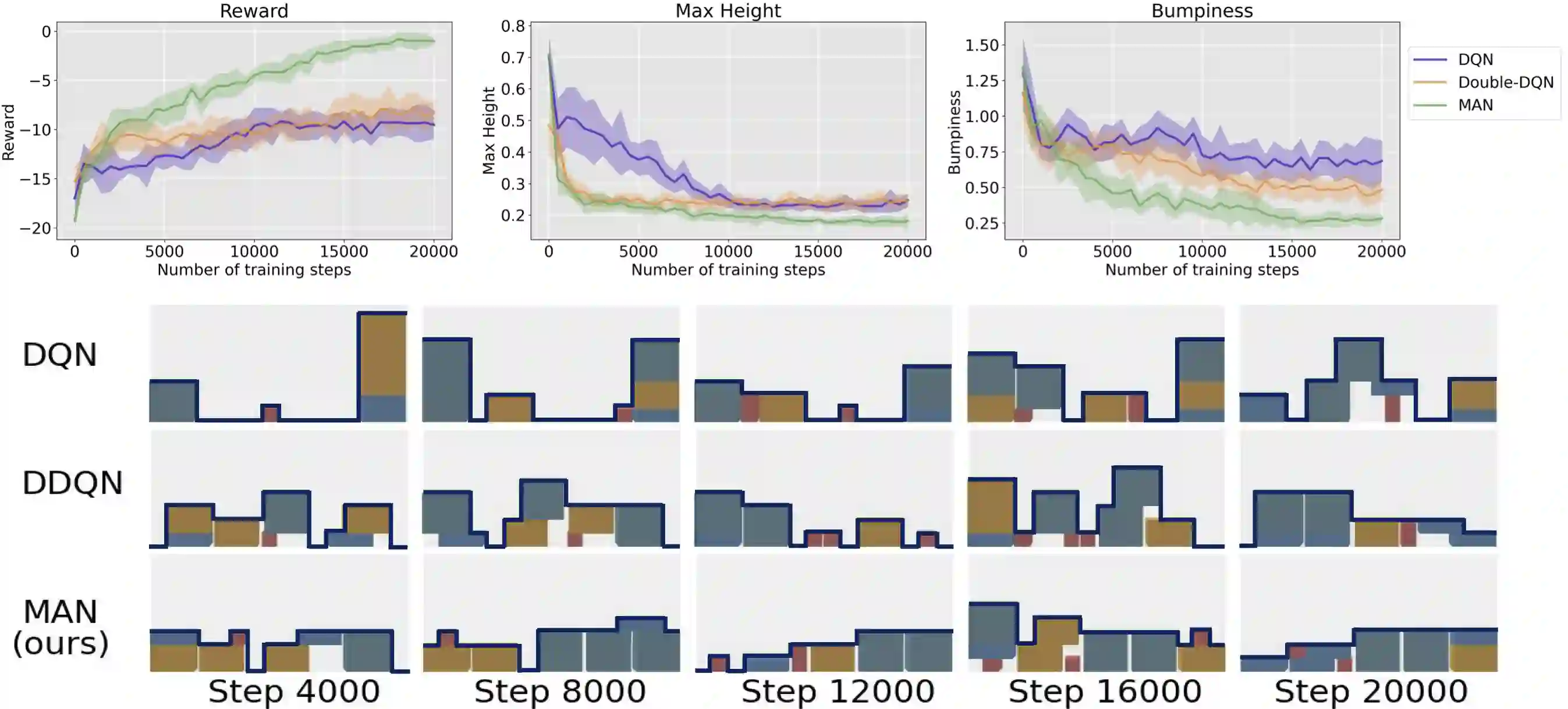
Learning control policies with large discrete action spaces is a challenging problem in the field of reinforcement learning due to present inefficiencies in exploration. With high dimensional action spaces, there are a large number of potential actions in each individual dimension over which policies would be learned. In this work, we introduce a Deep Reinforcement Learning (DRL) algorithm call Multi-Action Networks (MAN) Learning that addresses the challenge of high-dimensional large discrete action spaces. We propose factorizing the N-dimension action space into N 1-dimensional components, known as sub-actions, creating a Value Neural Network for each sub-action. Then, MAN uses temporal-difference learning to train the networks synchronously, which is simpler than training a single network with a large action output directly. To evaluate the proposed method, we test MAN on three scenarios: an n-dimension maze task, a block stacking task, and then extend MAN to handle 12 games from the Atari Arcade Learning environment with 18 action spaces. Our results indicate that MAN learns faster than both Deep Q-Learning and Double Deep Q-Learning, implying our method is a better performing synchronous temporal difference algorithm than those currently available for large discrete action spaces.
翻译:由于目前勘探效率低下,在强化学习领域,使用大型离散动作空间的学习控制政策是一个具有挑战性的难题。在高维行动空间中,每个单个层面都有大量潜在行动,可以学习政策。在这项工作中,我们引入了深强化学习(DRL)算法,称为多行动网络(MAN)学习,以应对高维大型离散动作空间的挑战。我们提议将Ndimenion动作空间纳入称为子动作的N1维部分,为每个子动作创建一个价值神经网络。然后,MAN利用时间差异学习同步地培训网络,这比直接培训一个具有大动作输出的单一网络简单得多。为了评估拟议的方法,我们测试MAN三种情景:N-dimenion Maze任务,一个块堆叠任务,然后将MAN扩大到18个动作空间的Atari Arcade学习环境的12场游戏。我们的结果显示,MAN学到的时间比深Qear和双深深基学习都要快,这意味着我们的方法比当前可以使用的时空空间更好地进行同步动作。</s>