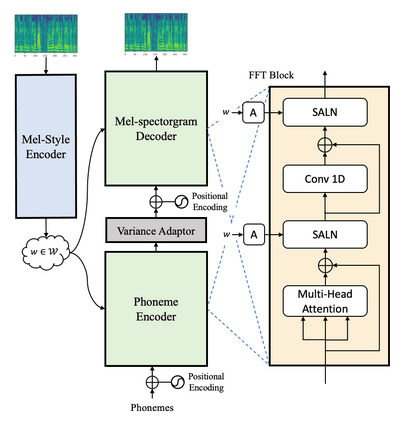
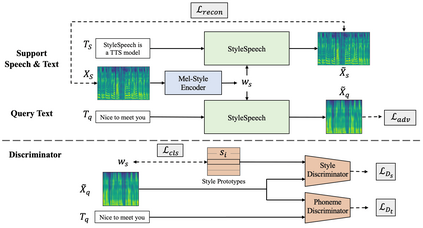
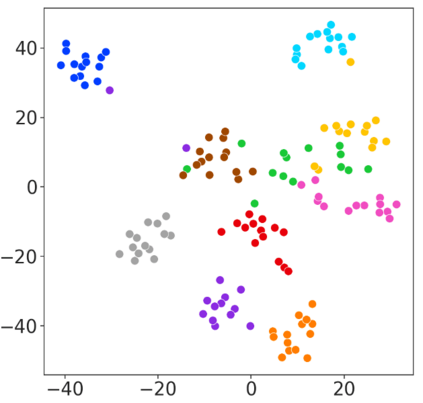
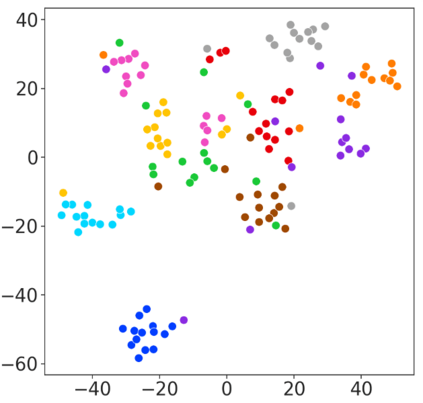
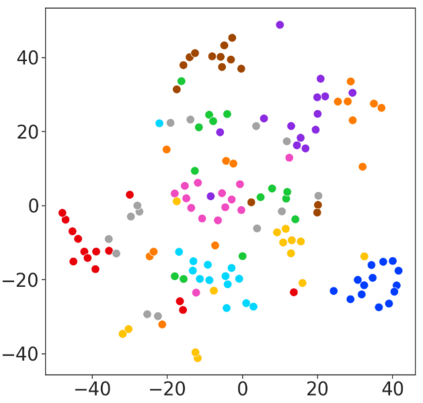
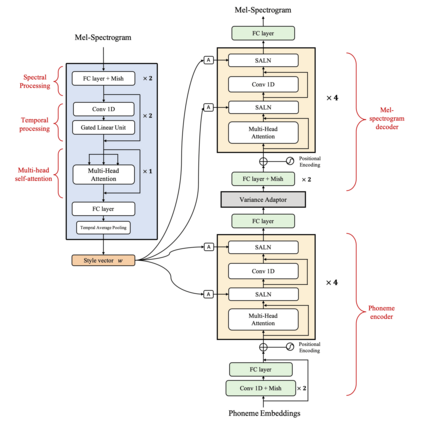
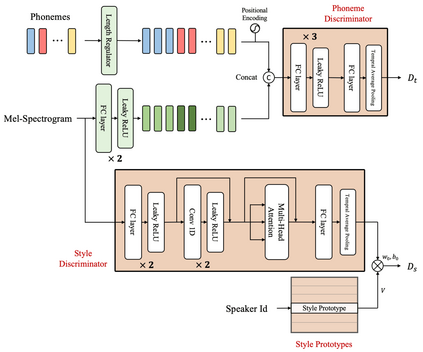
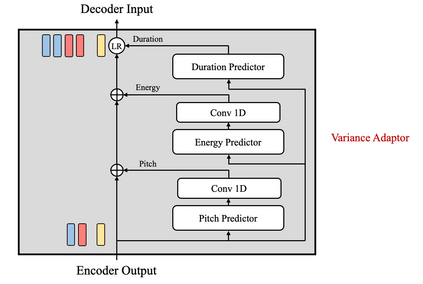
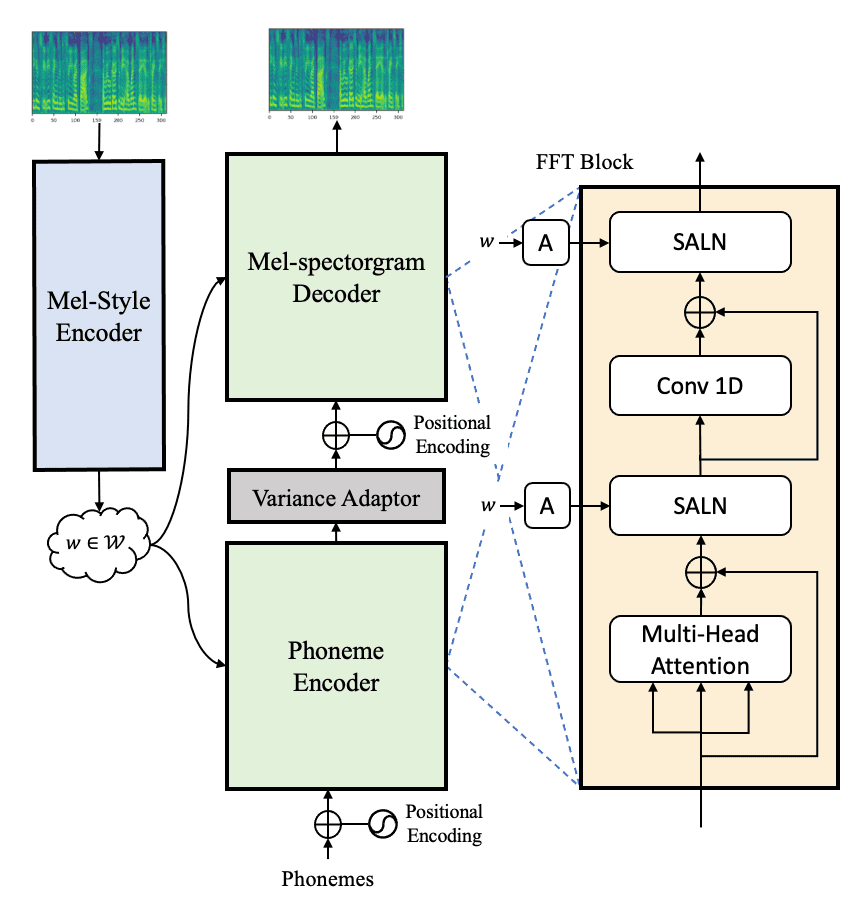
With rapid progress in neural text-to-speech (TTS) models, personalized speech generation is now in high demand for many applications. For practical applicability, a TTS model should generate high-quality speech with only a few audio samples from the given speaker, that are also short in length. However, existing methods either require to fine-tune the model or achieve low adaptation quality without fine-tuning. In this work, we propose StyleSpeech, a new TTS model which not only synthesizes high-quality speech but also effectively adapts to new speakers. Specifically, we propose Style-Adaptive Layer Normalization (SALN) which aligns gain and bias of the text input according to the style extracted from a reference speech audio. With SALN, our model effectively synthesizes speech in the style of the target speaker even from single speech audio. Furthermore, to enhance StyleSpeech's adaptation to speech from new speakers, we extend it to Meta-StyleSpeech by introducing two discriminators trained with style prototypes, and performing episodic training. The experimental results show that our models generate high-quality speech which accurately follows the speaker's voice with single short-duration (1-3 sec) speech audio, significantly outperforming baselines.
翻译:随着神经文本到语音(TTS)模型的快速进步,个性化语音生成现在对许多应用的需求很大。为了实际应用,TTS模型应该产生高质量的语音,只有来自特定演讲者的少数音样样本,而且时间短。然而,现有的方法要么需要微调模型,要么无需微调就达到低调质量。在这项工作中,我们提议SteleSpeech,这是一个新的TTS模型,不仅综合高质量的语音,而且有效地适应新演讲者。具体地说,我们建议Sty-Adaptive层正常化(SALN)模式,根据从参考演讲音频中提取的风格调整文本输入的增益和偏差。与SALN相比,我们的模式有效地将语言与目标演讲者的风格合成,甚至从单一音频。此外,为了提高Speastech对新演讲的适应性,我们把它扩大到Meta-StyleSpeech,引入了两个经过风格原型培训的导师,并进行了反射培训。实验结果显示,我们的模型产生了高品质的语音(1-3级),并准确地按照单一音频基准。