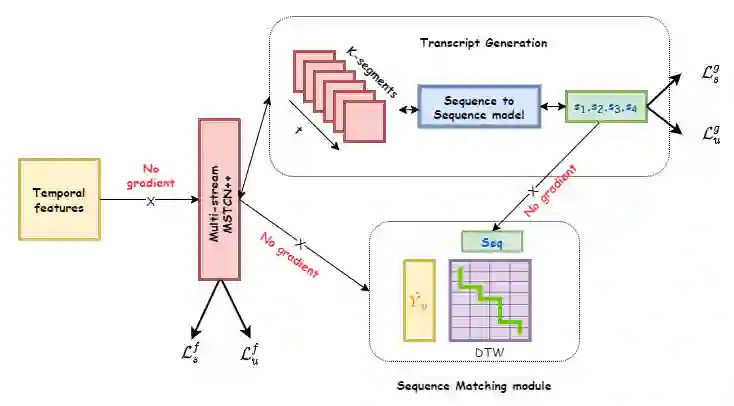
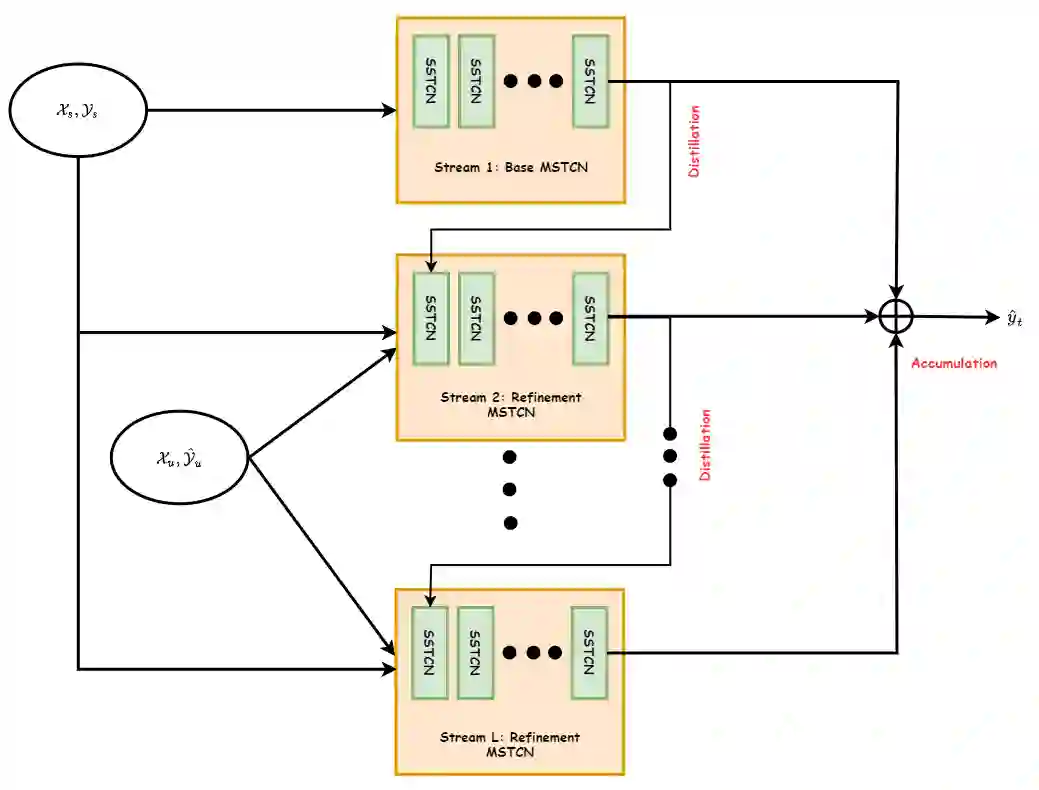
Recent temporal action segmentation approaches need frame annotations during training to be effective. These annotations are very expensive and time-consuming to obtain. This limits their performances when only limited annotated data is available. In contrast, we can easily collect a large corpus of in-domain unannotated videos by scavenging through the internet. Thus, this paper proposes an approach for the temporal action segmentation task that can simultaneously leverage knowledge from annotated and unannotated video sequences. Our approach uses multi-stream distillation that repeatedly refines and finally combines their frame predictions. Our model also predicts the action order, which is later used as a temporal constraint while estimating frames labels to counter the lack of supervision for unannotated videos. In the end, our evaluation of the proposed approach on two different datasets demonstrates its capability to achieve comparable performance to the full supervision despite limited annotation.
翻译:最近的时间行动分解方法在培训期间需要框架说明才能有效。 这些说明非常昂贵,而且要花很多时间才能获得。 当只有有限的附加说明数据时,这些说明限制了它们的性能。 相反,我们很容易通过互联网收集大量的内部无附加说明的视频,这样,本文件就提出了一个时间行动分解任务的方法,可以同时利用附加说明和无附加说明的视频序列的知识。我们的方法使用多流蒸馏方法,反复地改进并最终合并其框架预测。我们的模型还预测了行动顺序,该动作顺序后来被用作时间限制,同时估算框架标签,以弥补对无附加说明的视频缺乏监督的情况。 最后,我们对两个不同数据集的拟议方法的评估表明,尽管注释有限,我们仍有能力实现与全面监督相类似的业绩。