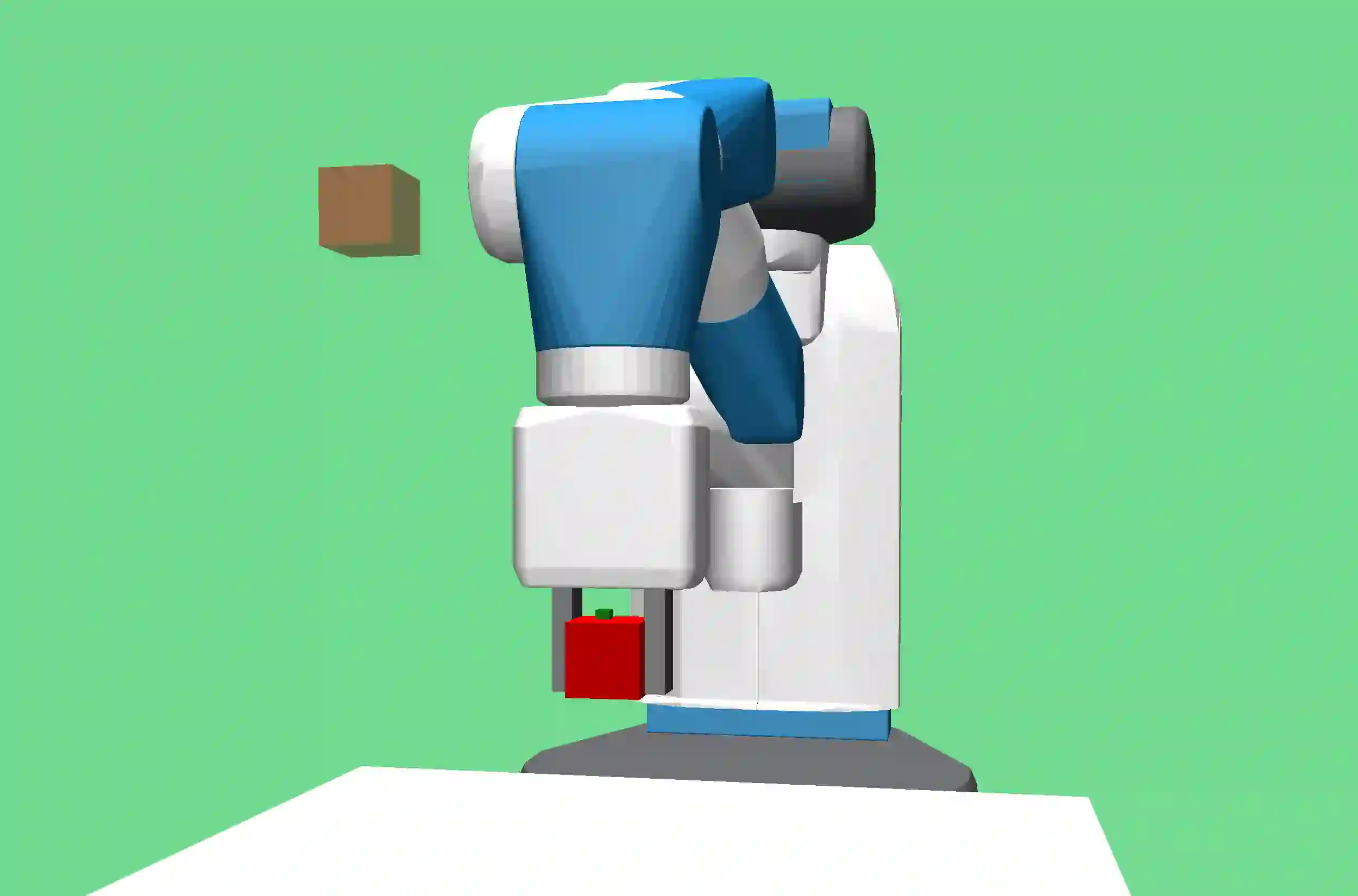
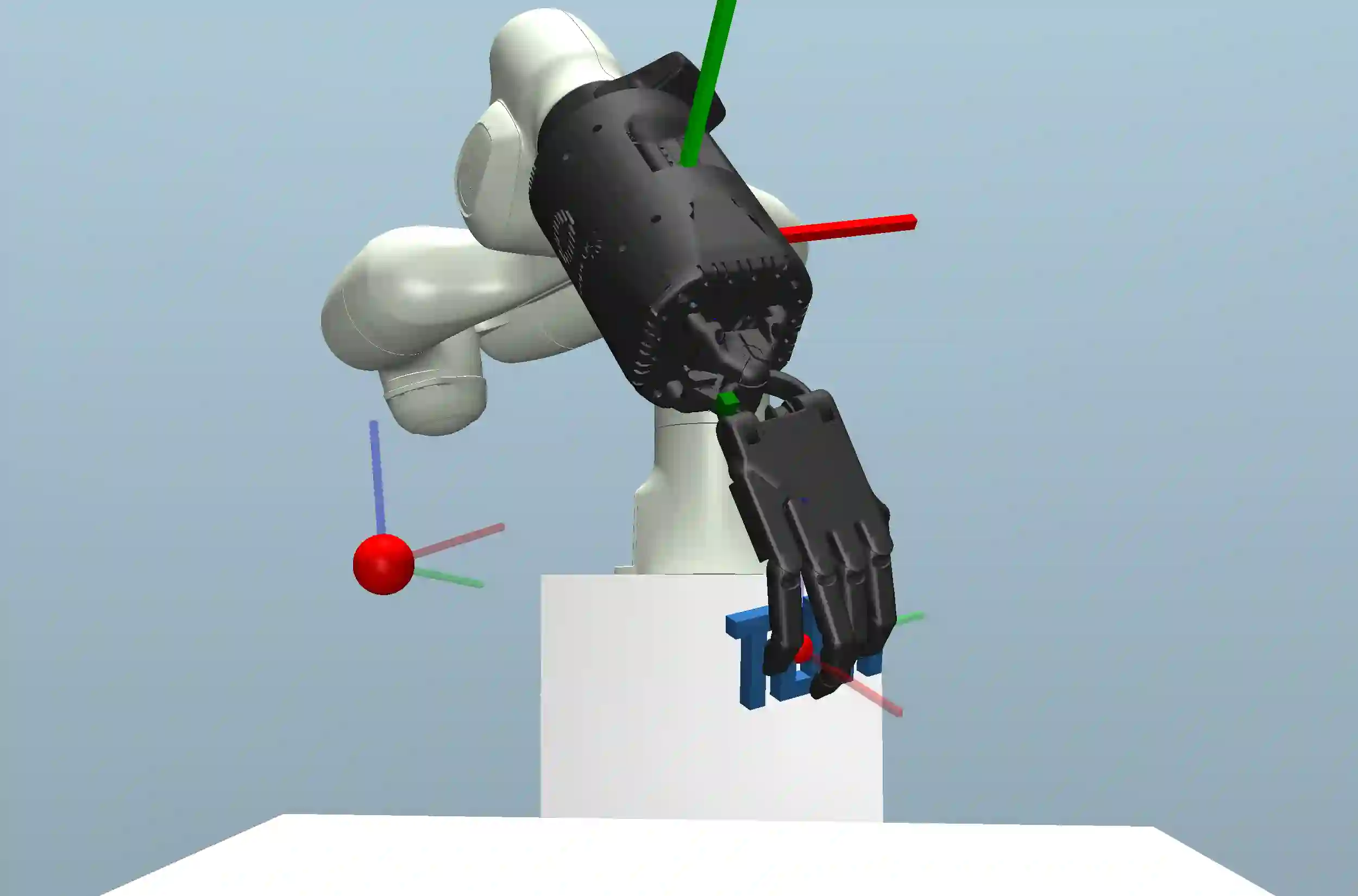
Reinforcement learning is a promising method for robotic grasping as it can learn effective reaching and grasping policies in difficult scenarios. However, achieving human-like manipulation capabilities with sophisticated robotic hands is challenging because of the problem's high dimensionality. Although remedies such as reward shaping or expert demonstrations can be employed to overcome this issue, they often lead to oversimplified and biased policies. We present Dext-Gen, a reinforcement learning framework for Dexterous Grasping in sparse reward ENvironments that is applicable to a variety of grippers and learns unbiased and intricate policies. Full orientation control of the gripper and object is achieved through smooth orientation representation. Our approach has reasonable training durations and provides the option to include desired prior knowledge. The effectiveness and adaptability of the framework to different scenarios is demonstrated in simulated experiments.
翻译:强化学习是一种很有希望的机器人掌握方法,因为它可以在困难的情况下学习有效接触和掌握政策;然而,由于问题涉及面广,使用尖端机器人手实现人性化操纵能力具有挑战性;虽然可以采用奖励制成或专家示范等补救措施来克服这一问题,但往往会导致政策过于简单和有偏见;我们提出了Dext-Gen,这是一个强化学习框架,用于在稀薄的奖励环境中进行脱轨,适用于各种握手,并学习不偏袒和复杂的政策;对握手和对象的全面定向控制是通过平稳的定向代表实现的;我们的方法有合理的培训期限,并提供选择,包括预期的事先知识;模拟实验显示框架对不同情景的有效性和适应性。