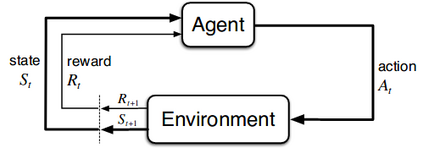
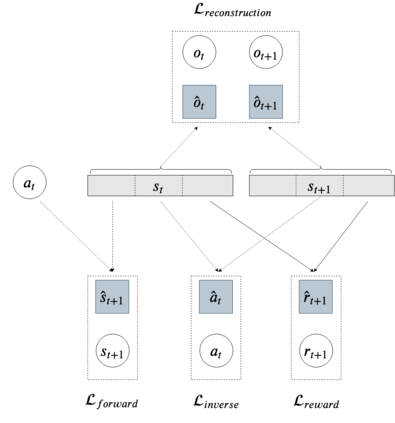
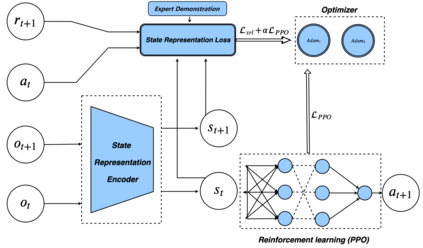
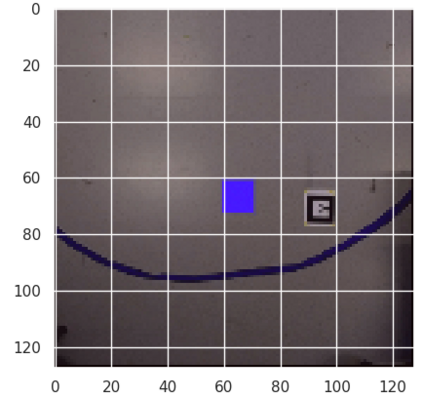
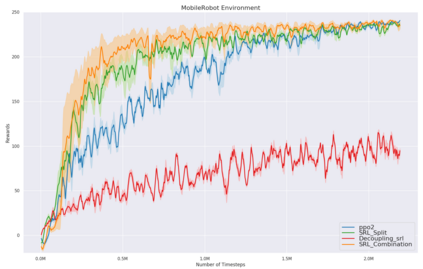
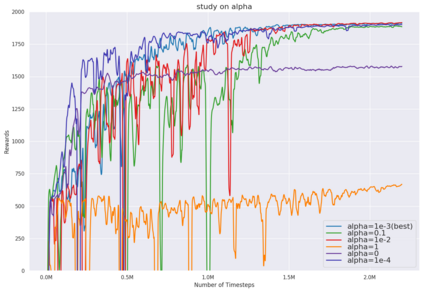
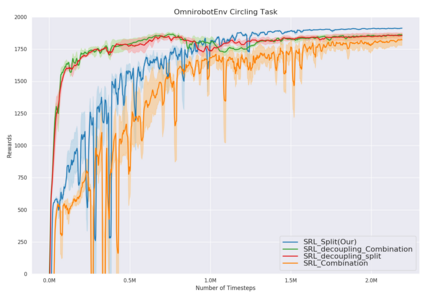
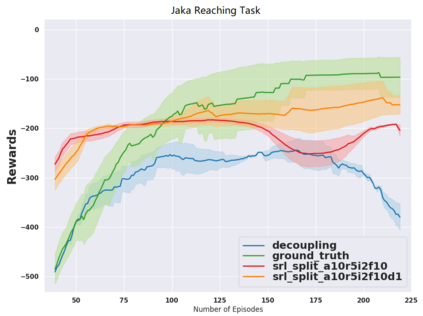
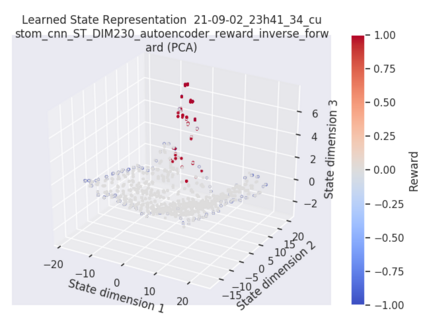
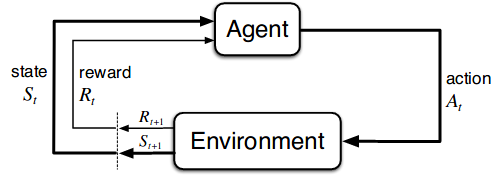
While the rapid progress of deep learning fuels end-to-end reinforcement learning (RL), direct application, especially in high-dimensional space like robotic scenarios still suffers from high sample efficiency. Therefore State Representation Learning (SRL) is proposed to specifically learn to encode task-relevant features from complex sensory data into low-dimensional states. However, the pervasive implementation of SRL is usually conducted by a decoupling strategy in which the observation-state mapping is learned separately, which is prone to over-fit. To handle such problem, we present a new algorithm called Policy Optimization via Abstract Representation which integrates SRL into the original RL scale. Firstly, We engage RL loss to assist in updating SRL model so that the states can evolve to meet the demand of reinforcement learning and maintain a good physical interpretation. Secondly, we introduce a dynamic parameter adjustment mechanism so that both models can efficiently adapt to each other. Thirdly, we introduce a new prior called domain resemblance to leverage expert demonstration to train the SRL model. Finally, we provide a real-time access by state graph to monitor the course of learning. Results show that our algorithm outperforms the PPO baselines and decoupling strategies in terms of sample efficiency and final rewards. Thus our model can efficiently deal with tasks in high dimensions and facilitate training real-life robots directly from scratch.
翻译:虽然深层次学习的快速进展有助于终端到终端强化学习(RL),但直接应用,特别是在机器人情景等高维空间的直接应用,仍然受到高抽样效率的影响。因此,国家代表学习(SRL)建议具体学习将复杂感官数据的与任务相关的特征从复杂的感官数据编码到低维状态。然而,普遍实施SRL通常是通过一种脱钩的战略来进行,在这种战略中,观测-状态绘图是单独学习的,容易过度使用。为了处理这类问题,我们提出了一个称为政策优化的新算法,它通过摘要演示将SRL纳入原始RL规模。首先,我们利用RL损失来帮助更新SRL模型模型,以便国家能够发展适应强化学习的需求,并保持良好的物理解释。第二,我们引入一个动态参数调整机制,以便两种模型能够有效地适应彼此。第三,我们引入了一种新的域比对利用专家演示来培训SRL模型。最后,我们通过州图提供实时访问,以监测学习过程。结果显示,我们的实际算算算方法超越了我们高水平的模型和最终的机器人奖项。